云原生技术与云原生产品
Posted 架构587
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生技术与云原生产品相关的知识,希望对你有一定的参考价值。
最近随着Snowflake的上市,“云原生”这个概念也随之更加火了。每提及Snowflake,必提及“云原生”数据仓库。
不过,这个Snowflake的“云原生”,却使我陷入了困惑。
-
一方面,我印象中的云原生应该是Kubernetes相关的那个“云原生” -
但另一方面,把“云原生”应用到“更适合云环境”的Snowflake好像也挺合理
我不禁在想到底什么是“云原生”
云原生的定义
云原生(Cloud Native)最早是由Pivotal公司的 Matt Stine 于2013提出。
-
2017年前其把云原生定义为:模块化、可观察、可部署、可测试、可替换、可处理 -
现在简化为:DevOps+持续交付+微服务+容器
而把云原生更加发扬光大的则是:CNCF基金会,全名为:Cloud Native Computing Foundation。名字起的非常好 —— 云原生计算基金会,让人不禁觉得其是“Cloud Native”的权威。
大名鼎鼎的Kubernetes就是其孵化出的第一个项目,目前有大量云原生相关的开源项目在孵化中或已毕业。如果说大数据时代造就了Apache软件基金会,那么云原生时代则成就了CNCF。
可以从 https://github.com/cncf/toc/blob/master/DEFINITION.md 上看到CNCF对于云原生的定义(包含了多种语言的版本,非常专业)
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。
而云原生的代表技术则包括:
-
容器(containers) -
服务网格(service meshes) -
微服务(microservices) -
不可变基础设施(immutable infrastructure) -
声明式API(declarative APIs)
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
另外,CNCF还有一张著名的云原生路径地图(Trail Map): https://github.com/cncf/landscape/blob/master/README.md#trail-map
云原生技术与云原生产品
了解了CNCF对于“Cloud Native”的定义后,发现好像我之前的理解是对的。那为啥Snowflake也可以算是云原生呢?突然我觉得之前的两种说法其实都是对的。
CNCF的定义更多的是定义了“云原生技术”:构建和运行在云上(公有云、私有云)应用程序的方法,是一套技术体系和方法论。最初更像是指导企业上云的技术栈&方法论。
而云原生虽好,但不是每个公司都有技术实力来实现云原生的,而且也没有必要每个公司都投入这么大的精力来实现云原生。所以,需要有服务商来基于“云原生技术”来实现面向最终用户的产品 —— “云原生产品”。
这里,我觉得有点类似前段时间也比较火的“中台”,其实也是“中台技术”和“中台产品”。“中台技术”是帮助企业来抽取可共享的功能模块,从而形成支撑前台的中间平台,本身更像是一种思想和方法论。类比软件工程中的 DRY 原则(Don't Repeat Yourself)。而后来被大家吐槽很多的是组装了各种开源组件的“中台产品”,中台产品本身也是有价值的,只不过不能把其作为一种万能灵药。中台不是银弹,云原生也不是,没有啥是。
而完全深耕于 AWS、Azure、GCP公有云的云数仓 Snowflake 的上市使得云原生(其实更准确是 云原生产品)更火。
公有云的优势
云原生技术是“构建和运行在云上(公有云、私有云)应用程序的方法”。而这个趋势最早首先是“公有云”有巨大的能力优势,然后才是“云原生技术”使得能同时兼容公有云和私有云。那我们先主要看看公有云为啥这么有优势。
我的观点是:公有云是“共享经济”的充分体现。
公有云有如下的优势:
1). 弹性算力
在公有云出现前,如果一个企业想提供一个服务,那首先要做的就是采购一批服务器,而这些服务器的使用是为了能平稳处理业务的最高峰准备的。所以,这些机器大多数时间都是相对空闲的。这样,明显的资源浪费产生了。而有了公有云的共享计算能力,我们只需要按需动态申请和启动虚拟机即可,无需提前采购多余的机器。比如:对于一个大的ETL计算,我们一台机器可能要跑1小时。但是我们要是充分利用公有云的“弹性算力”,我们可以申请10台机器一起跑,可能7分钟就跑完了(多台机器会有一定的性能损耗)。虽然我们最终付出的钱差不多,但是,对使用者的体验却完全不同(由1小时的等待减少为7分钟)
2). 理论上低成本
对于共享的资源,其从成本上肯定会比企业自己采购要便宜很多,尤其是当规模越来越大,其总成本会越来越低。当然,这里只是描述理论上的总成本。如果云市场上没有充分竞争的话,那么,云服务商可能会收取比较高的价格,所以,这里说“理论上低成本”
3). 快速land & expand
公有云是快速 land & expand 这种商务策略的最佳案例,用户开始使用云服务时,往往花的钱非常低(各大云服务商一般都提供一定的免费额度)。当然,真正深入使用公有云以后,就会采购越来越多的服务,使用越来越多的资源。最终,云服务商也可以赚取大量的利润。
4). 高可用,低运维
高可用自不必说,低运维更是让使用者省心。尤其是这个趋势越来越明显:DBA、运维等岗位逐步都转移到云服务商,而对于传统企业来说,很难找到水平比较高的DBA和运维了,最终,即使你不想上云,也找不到人来维护私有机房了。
公有云产品上百+,重要的就那几个
S3对象存储
首先,质量最好,最难以替代的是:对象存储。AWS上是S3,阿里云上叫OSS。
S3有如下几个特点:
-
简单,其名字S3就是“Simple Storage Service”的简写。不能完全支持POSIX文件API标准 -
无限容量 -
高可用:理论上可达到 99.999999999%(11 个 9)的持久性 -
11个9的意思:存储1百万个文件, statistically 每 659,000 年丢失一个文件 -
低成本 (以 100G数据存S3举例) -
S3 标准版:每月2.3美元 -
S3 标准不频繁访问:每月 1.25美元 -
S3 Glacier 归档访问:每月 0.4美元 -
支持 S3 智能分层 - 适用于访问模式未知或不断变化的数据,可自动成本节省
虚拟机 EC2
AWS上EC2,阿里云上叫ECS
-
类似于传统的计算服务器 -
多种规格型号选择(cpu、存储等) -
可以动态申请、可以包年包月 (包年包月后,虽然成本会低一些,但是无法算是弹性计算,而更像是传统的服务器) -
可以调整CPU、内存磁盘等,往往需要关闭服务器后调整 -
VM从创建到启动完毕时间不等,比如2分钟?
托管数据库
比如:托管的关系型数据库:Postgresql、mysql,托管的NoSQL数据库:MongoDB、Cassandra等
其特点:
-
高利润 -
高可用、减少使用者运维成本 -
天然集成备份等
云原生发展以后
云原生发展以后,也有一些其它托管服务越来越流行:
-
托管Kubernetes集群 -
Docker Registry -
CI/CD
公有云带来的新趋势(一):存储计算分离
传统hadoop的HDFS,往往是存储和计算都需要同时扩容。
S3实在是太便宜了,虽然它有很多局限,但是那些局限在便宜面前都不是事,都是可以用技术手段绕过的。
所以,存储和计算分离是大数据领域的一大趋势:动态扩容的Spark集群或Presto集群 (计算),把数据都用标准格式(比如Parquet)存储在 S3 (存储)
采用这种架构后,总成本大幅减少。
公有云带来的新趋势(二):Serverless & FaaS
Serverless是公有云带来的新趋势。既然公有云已经能大幅共享资源,大幅减少运维成本。那我为啥还要费劲的维护虚拟机。
Serverless并不是真的没有服务器了,而是,我只需要关心我的业务,至于背后在哪里计算,是云服务商的事情。
Serverless只是一种理念,其具体有很多种产品都算是 Serverless。
1). 阿里云的Serverless Kubernetes (创建Serverless Kubernetes时,默认不用再预置计算节点,而是当有pod发布到Kubernetes后再申请资源,近似于只为使用的资源付费。
2). FaaS (Function As A Service):AWS Lambda
AWS Lambda,其从2014年诞生以来,其应用场景逐步被扩展
一些场景示例:
-
事件驱动:上传图片到S3,自动触发 Lambda 自定义函数来产生缩微图 -
REST请求的响应:结合API Gateway,当有http请求到指定URL路径后,调用 Lambda 函数来返回处理结果 -
很多其它应用。有分享的function市场
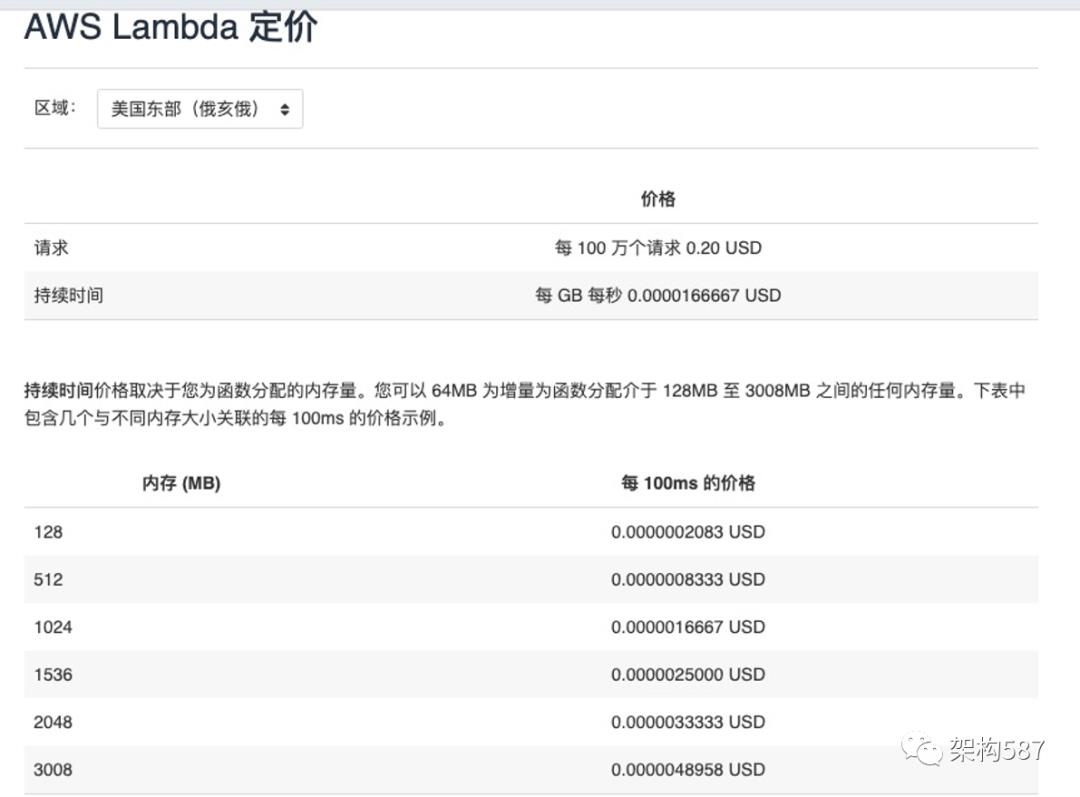
看场景可能还看不出哪里比虚拟机好。我们来看一下价格,尤其是起步价格:
适合起步, 有免费额度:AWS Lambda 免费使用套餐包含每月 1M 次免费请求以及每月 400000GB-秒的计算时间。
Snowflake的启示
结合前面公有云的优势,我们来看一下Snowflake。
Snowflake有3层:
-
存储层:毋庸置疑的基于S3 -
弹性计算层:可真正动态调整、根据使用情况动态启动、停止 -
服务层:其它需要常驻、多租户管理、权限、调度等共享的服务
关键点:
-
极致的追求减低总成本 (并让客户能理解) -
把计费模式更透明更让客户容易理解 (而不是, API调用次数,IO数等)
Why Snowflake 能存在?
对于云服务商,其出发点是:赚取最高利润的水电煤。其目标:让客户尽可能多的使用资源。最好年初就提前把资源的钱交上来,无论你使用的是我提供的产品,还是第三方提供的产品(只要都跑在我的平台上)。
对于云资源使用者,则要:
-
不能被云服务商把利润都赚去 -
费脑思考怎么才能省钱,比如:怎么才能在阿里云VM不使用时,自动关闭部分VM等。怎么做个系统来动态分配VM给不同的研发
云中间软件服务商:当大量使用云的客户都在想怎么省钱,又没有办法成立研发团队去开发,那就是大量的机会!
商业智能(BI)怎么才能像Snowflake那么深度基于“公有云”
如果Snowflake这种充分利用“公有云”的数据仓库是未来的趋势,那我们所在的BI行业,以后怎么才能更加充分的利用“公有云”的能力呢?
我发现最近比较火的一个开源软件 cube.js 能很好的利用“公有云”的能力,值得更深入的研究。
cube.js 本身是一个非常有趣的项目,其不只是可视化,而是一个近似完整的BI。而且:cube.js 可以完全部署在 AWS Lambda上,这个效果就是,如果是访问量比较小的BI页面,那基本上不用花钱。(无需使用任何的服务器)
比如:下面是一种部署cube.js在AWS Lambda上的例子:
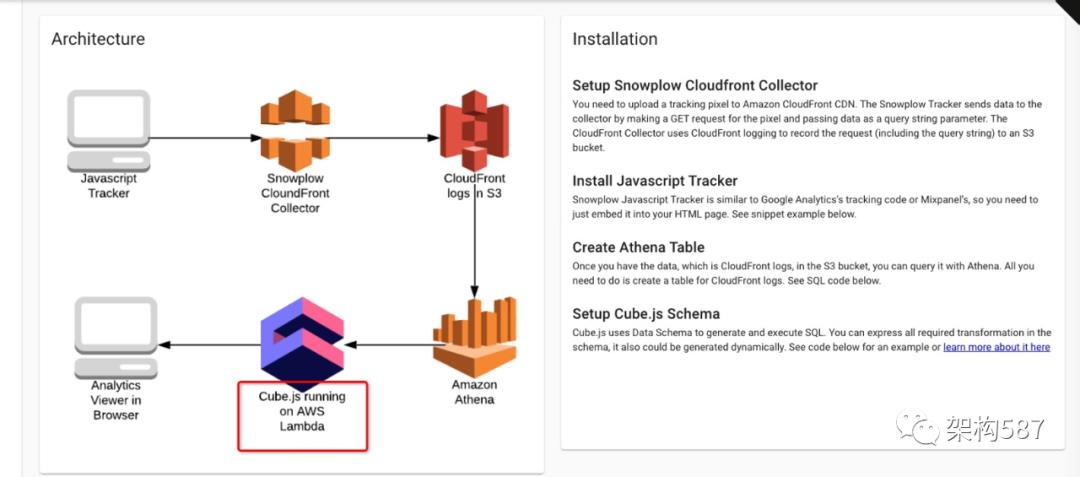
其展示效果:
一些相关URL方便感兴趣的朋友了解:
-
项目地址:https://github.com/cube-js/cube.js -
展示示例1:https://d1ygcqhosay4lt.cloudfront.net/examples/event-analytics/about -
展示示例2:https://web-analytics-demo.cubecloudapp.dev/#/ -
搭建的Dashboard样例代码:https://github.com/cube-js/cube.js/tree/master/examples/real-time-dashboard
当BI产品,如果能做到开始的时候,真正的0成本拥有(无论是对用户,还是对BI提供商),真正的按使用量付费,那它一定能颠覆传统的BI。就像Snowflake颠覆了传统数仓那样!
云原生在观远的应用
观远在公司成立之初,就坚定的拥抱Kubernetes和Spark。当方向对了以后,就不自觉地能抓住这些大趋势。比如:
-
不自觉的发现自己的产品就是充分用了“云原生” -
不自觉的发现自己的产品也充分利用了“存储计算分离”,在公有云上使用S3,在私有云上部署Minio -
由于要解决Parquet的更新问题,也开始研究 Databricks Delta Lake, Apache Hudi, Apache Iceberg -
为了解决快速查询问题,引入了clickhouse做无极加速
所以,技术的名词怎么解释其实不重要,“大数据”、”中台“、“云原生”等,重要的是:当你选择了一条正确的路,努力去解决路上遇到的挑战,那你就会不自觉地采用了“最先进的架构”,站在了最大的“风口”。
尤其感到欣慰的是:前几天读到了著名投资机构a16z的文章《Emerging Architectures for Modern Data Infrastructure》:https://a16z.com/2020/10/15/the-emerging-architectures-for-modern-data-infrastructure/ 发现其中的现代数据架构蓝图(blueprint)和观远的产品路线非常类似。
附一张观远的BI+开发平台的蓝图 (主要参考了a16z的这篇文章中的蓝图,请对比a16z原文中的图):
总结
上周,我在公司内部做了一场关于“云原生”概念的技术分享,本文主要内容即来源于那次分享。看文章好像不止是讲了“云原生技术”和“云原生产品”,而是也介绍了一下公有云的一些概念,以及基于Snowflake对于BI的启示,有些乱,但是中心思想是:
也许我们错过了互联网时代,没抓住移动浪潮,大数据时代也接近尾声,那我们一定要抓住“云原生时代”。机会只垂青有准备的头脑,那我们为“云原生时代”准备了什么。
以上是关于云原生技术与云原生产品的主要内容,如果未能解决你的问题,请参考以下文章