怎么下载m3u8格式视频?Python爬取A站m3u8格式视频案例讲解
Posted 松鼠爱吃饼干
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么下载m3u8格式视频?Python爬取A站m3u8格式视频案例讲解相关的知识,希望对你有一定的参考价值。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
-
确定需求 (确定要爬的内容是什么?)。只有知道数据要的是什么,才能根据实际情况去分析 它的来源
-
怎么去分析 (开发者工具[浏览器都自带 鼠标右键点击插件或者F12]) 抓包分析
所有的ts文件内容 来自 m3u8
- 发送请求 对于视频的详情页url地址发送请求
- 获取数据 获取视频的详情页网页源代码
- 解析数据 提取 m3u8的 url地址 标题
- 发送请求 对于m3u8的 url地址 发送请求
- 获取数据 获取所有ts url地址(不是完整是需要拼接)
- 发送请求 对于 ts url地址 发送请求
- 保存数据 保存ts 视频片段 一个一个视频片段
- 合成视频 一个整体视频内容
import requests # 数据请求模块 pip install requests import re # 正则表达式 内置模块 不需要安装 import os # 文件操作 import zipfile # 做压缩文件
url = f\'https://www.acfun.cn/v/ac23857874 headers = { \'User-Agent\': \' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/92.0.4515.159 Safari/537.36\' } response = requests.get(url=url, headers=headers) print(response)
运行代码,返回值为200
元字符 * +
.*? 通配符 可以匹配任意字符(除了\\n) 匹配文字 匹配数字 字母 特殊字符 re.S
\\ 转义字符 把含有特殊含义的字符转成除了字符本身以外 没有其他意思
[0] 正则表达式提取出来的内容 返回是列表 [0] 0 是指列表索引位置 索引位置是0 是列表里面的第一个元素
[0,1,2,3,4,5] img\\ 我转义我自己
() 表示精确匹配 ? 非贪婪匹配
title = re.findall(\'<title >(.*?) - AcFun弹幕视频网 - 认真你就输啦 \\(\\?ω\\?\\)ノ- \\( ゜- ゜\\)つロ</title>\', response.text)[0] m3u8_url = re.findall(\'"backupUrl(.*?)\\"]\', response.text)[0].replace(\'\\"\', \'\').split(\'\\\')[2] m3u8_data = requests.get(url=m3u8_url, headers=headers).text print(m3u8_url)
正则表达式替换 re.sub() join 是把列表转成字符串
\\d 匹配数字 \\d+匹配多个数字 * 匹配前一个字符0个或者多个无数个
m3u8_data = re.sub(\'#EXTM3U\', \'\', m3u8_data) m3u8_data = re.sub(\'#EXT-X-VERSION:\\d\', \'\', m3u8_data) m3u8_data = re.sub(\'#EXT-X-TARGETDURATION:\\d\', \'\', m3u8_data) m3u8_data = re.sub(\'#EXT-X-MEDIA-SEQUENCE:\\d\', \'\', m3u8_data) m3u8_data = re.sub(\'#EXTINF:\\d\\.\\d+,\', \'\', m3u8_data) m3u8_data = re.sub(\'#EXT-X-ENDLIST\', \'\', m3u8_data) m3u8_data = m3u8_data.split() for link in m3u8_data: # 字符串拼接 加上 才是完整url地址 构建完整的url地址 link_url = \'https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/\' + link
link_content = requests.get(url=link_url, headers=headers).content link_name = link.split(\'.\')[1] with open(filename + link_name + \'.ts\', mode=\'w\') as f: f.write(link_content)

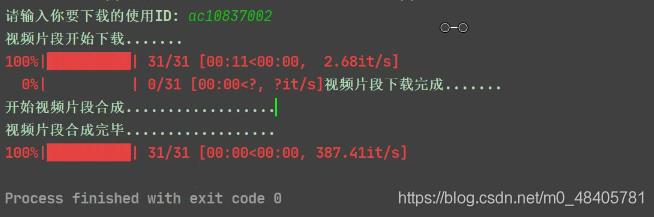
files = os.listdir(filename) print(\'开始视频片段合成..................\') with zipfile.ZipFile(filename + title + \'.mp4\', mode=\'w\') as z: for file in tqdm(files): path_file = filename + file z.write(path_file) os.remove(path_file) print(\'视频片段合成完毕..................\')

以上是关于怎么下载m3u8格式视频?Python爬取A站m3u8格式视频案例讲解的主要内容,如果未能解决你的问题,请参考以下文章