解释器模式
Posted 童话述说我的结局
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解释器模式相关的知识,希望对你有一定的参考价值。
一、定义
解释器模式(Interpreter Pattern) 是指给定一门语言, 定义它的语法的一种表示, 并定义一个解释器,该解释器使用该表示来解释语言中的句子。是一种按照规定的语法进行解析的模式,属于行为型模式。就比如编译器可以将源码编译解释为机器码, 让CPU能进行识别并运行。解释器模式的作用其实与编译器一样,都是将一些固定的语法进行解释,构建出一个解释句子的解释器。简单理解,解释器是一个简单语法分析工具,它可以识别句子语义,分离终结符号和非终结符号,提取出需要的信息,让我们能针对不同的信息做出相应的处理。其核心思想是识别语法,构建解释。
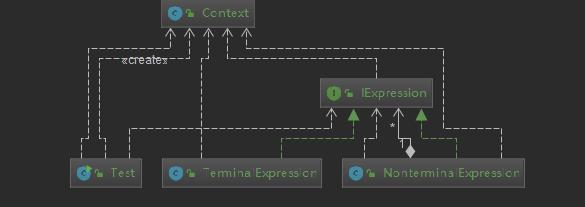
解释器模式主要包含四种角色:
- 抽象表达式(Expression) :负责定义一个解释方法interpret, 交由具体子类进行具体解释;
- 终结符表达式(Terminal Expression) :实现文法中与终结符有关的解释操作。文法中的每一个终结符都有一个具体终结表达式与之相对应,比如公式R=R1+R2,R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符(R1,R2);
- 非终结符表达式(Nonterminal Expression) :实现文法中与非终结符有关的解释操作。文法中的每条规则都对应于一个非终结符表达式。非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中, “+”就是非终结符,解析“+”的解释器就是一个非终结符表达式。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式;
- 上下文环境类(Context) :包含解释器之外的全局信息。它的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,给R1赋值100,给R2赋值200,这些信息需要存放到环境中。
二、解释器模式的案例
1.标准写法
// 抽象表达式 public interface IExpression { // 对表达式进行解释 Object interpret(Context context); }
// 终结符表达式 public class TerminalExpression implements IExpression { private Object value; public Object interpret(Context context) { // 实现文法中与终结符有关的操作 context.put("",""); return null; } }
// 非终结符表达式 public class NonterminalExpression implements IExpression { private IExpression [] expressions; public NonterminalExpression(IExpression... expressions) { // 每个非终结符表达式都会对其他表达式产生依赖 this.expressions = expressions; } public Object interpret(Context context) { // 进行文法处理 context.put("",""); return null; } }
// 上下文环境类 public class Context extends HashMap { }
public class Test { public static void main(String[] args) { try { Context context = new Context(); // 定义一个语法容器,用于存储一个具体表达式 Stack<IExpression> stack = new Stack<IExpression>(); // for (; ; ) { // // 进行语法解析,并产生递归调用 // } // 获取得到最终的解析表达式:完整语法树 IExpression expression = stack.pop(); // 递归调用获取结果 expression.interpret(context); }catch (Exception e){ e.printStackTrace(); } } }
上面我只写了标准写法,上下文内容我没做补充,只是让大家明白这个模板怎么写,具体的案例在菜鸟教程也有https://www.runoob.com/design-pattern/interpreter-pattern.html
2.使用解释器模式解析数学表达式:
下面用解释器模式来实现一个数学表达式计算器,包含加减乘除运算。首先定义抽象表达式角色IArithmeticInterpreter接口:
//抽象表达式角色 public interface IArithmeticInterpreter { int interpret(); }
//终结表达式角色AbstractInterpreter抽象类 public abstract class Interpreter implements IArithmeticInterpreter { protected IArithmeticInterpreter left; protected IArithmeticInterpreter right; public Interpreter(IArithmeticInterpreter left, IArithmeticInterpreter right) { this.left = left; this.right = right; } }
//加 public class AddInterpreter extends Interpreter { public AddInterpreter(IArithmeticInterpreter left, IArithmeticInterpreter right) { super(left, right); } public int interpret() { return this.left.interpret() + this.right.interpret(); } }
//减 public class SubInterpreter extends Interpreter { public SubInterpreter(IArithmeticInterpreter left, IArithmeticInterpreter right) { super(left, right); } public int interpret() { return this.left.interpret() - this.right.interpret(); } }
//乘法 public class MultiInterpreter extends Interpreter { public MultiInterpreter(IArithmeticInterpreter left, IArithmeticInterpreter right){ super(left,right); } public int interpret() { return this.left.interpret() * this.right.interpret(); } }
//除法 public class DivInterpreter extends Interpreter { public DivInterpreter(IArithmeticInterpreter left, IArithmeticInterpreter right){ super(left,right); } public int interpret() { return this.left.interpret() / this.right.interpret(); } }
//创建数字表达式类 public class NumInterpreter implements IArithmeticInterpreter { private int value; public NumInterpreter(int value) { this.value = value; } public int interpret() { return this.value; } }
//计算器类 public class Calculator { private Stack<IArithmeticInterpreter> stack = new Stack<IArithmeticInterpreter>(); public Calculator(String expression) { this.parse(expression); } private void parse(String expression) { String [] elements = expression.split(" "); IArithmeticInterpreter leftExpr, rightExpr; for (int i = 0; i < elements.length ; i++) { String operator = elements[i]; if (OperatorUtil.isOperator(operator)){ leftExpr = this.stack.pop(); rightExpr = new NumInterpreter(Integer.valueOf(elements[++i])); System.out.println("出栈: " + leftExpr.interpret() + " 和 " + rightExpr.interpret()); this.stack.push(OperatorUtil.getInterpreter(leftExpr, rightExpr,operator)); System.out.println("应用运算符: " + operator); } else{ NumInterpreter numInterpreter = new NumInterpreter(Integer.valueOf(elements[i])); this.stack.push(numInterpreter); System.out.println("入栈: " + numInterpreter.interpret()); } } } public int calculate() { return this.stack.pop().interpret(); } }
//操作工具类 public class OperatorUtil { public static boolean isOperator(String symbol) { return (symbol.equals("+") || symbol.equals("-") || symbol.equals("*")); } public static Interpreter getInterpreter(IArithmeticInterpreter left, IArithmeticInterpreter right, String symbol) { if (symbol.equals("+")) { return new AddInterpreter(left, right); } else if (symbol.equals("-")) { return new SubInterpreter(left, right); } else if (symbol.equals("*")) { return new MultiInterpreter(left, right); } else if (symbol.equals("/")) { return new DivInterpreter(left, right); } return null; } }
public class Test { public static void main(String[] args) { ExpressionParser parser = new SpelExpressionParser(); Expression expression = parser.parseExpression("100 * 2 + 400 * 1 + 66"); int result = (Integer) expression.getValue(); System.out.println("计算结果是:" + result); System.out.println("result: " + new Calculator("10 + 30").calculate()); System.out.println("result: " + new Calculator("10 + 30 - 20").calculate()); System.out.println("result: " + new Calculator("100 * 2 + 400 * 1 + 66").calculate()); } }
三、解释器模式在源码中的体现
在JDK源码中的Pattern对正则表达式的编译和解析就体现到了解析器模式
private void compile() { // Handle canonical equivalences if (has(CANON_EQ) && !has(LITERAL)) { normalize(); } else { normalizedPattern = pattern; } patternLength = normalizedPattern.length(); // Copy pattern to int array for convenience // Use double zero to terminate pattern temp = new int[patternLength + 2]; hasSupplementary = false; int c, count = 0; // Convert all chars into code points for (int x = 0; x < patternLength; x += Character.charCount(c)) { c = normalizedPattern.codePointAt(x); if (isSupplementary(c)) { hasSupplementary = true; } temp[count++] = c; } patternLength = count; // patternLength now in code points if (! has(LITERAL)) RemoveQEQuoting(); // Allocate all temporary objects here. buffer = new int[32]; groupNodes = new GroupHead[10]; namedGroups = null; if (has(LITERAL)) { // Literal pattern handling matchRoot = newSlice(temp, patternLength, hasSupplementary); matchRoot.next = lastAccept; } else { // Start recursive descent parsing matchRoot = expr(lastAccept); // Check extra pattern characters if (patternLength != cursor) { if (peek() == \')\') { throw error("Unmatched closing \')\'"); } else { throw error("Unexpected internal error"); } } } // Peephole optimization if (matchRoot instanceof Slice) { root = BnM.optimize(matchRoot); if (root == matchRoot) { root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot); } } else if (matchRoot instanceof Begin || matchRoot instanceof First) { root = matchRoot; } else { root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot); } // Release temporary storage temp = null; buffer = null; groupNodes = null; patternLength = 0; compiled = true; } Map<String, Integer> namedGroups() { if (namedGroups == null) namedGroups = new HashMap<>(2); return namedGroups; }
private Pattern(String p, int f) { //保存数据 pattern = p; flags = f; // to use UNICODE_CASE if UNICODE_CHARACTER_CLASS present if ((flags & UNICODE_CHARACTER_CLASS) != 0) flags |= UNICODE_CASE; // Reset group index count capturingGroupCount = 1; localCount = 0; if (pattern.length() > 0) { //调用编译方法 compile(); } else { root = new Start(lastAccept); matchRoot = lastAccept; } }
四、总结
优点:
扩展性强:在解释器模式中由于语法是由很多类表示的,当语法规则更改时,只需修改相应的非终结符表达式即可;若扩展语法时,只需添加相应非终结符类即可;
增加了新的解释表达式的方式;
易于实现文法:解释器模式对应的文法应当是比较简单且易于实现的,过于复杂的语法并不适合使用解释器模式。
缺点:
语法规则较复杂时,会引起类膨胀:解释器模式每个语法都要产生一个非终结符表达式当语法规则比较复杂时,就会产生大量的解释类,增加系统维护困难;
执行效率比较低:解释器模式采用递归调用方法,每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,因此完整表达式的最终结果是通过从后往前递归调用的方式获取得到。当完整表达式层级较深时,解释效率下降,且出错时调试困难,因为递归迭代层级太深。
以上是关于解释器模式的主要内容,如果未能解决你的问题,请参考以下文章