[入门级项目]采集《python进阶》教程
Posted jixn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[入门级项目]采集《python进阶》教程相关的知识,希望对你有一定的参考价值。
首发于:https://mp.weixin.qq.com/s/Xo7StWY0VS2aEQi-52FNlA
前言
- 难度:入门级
- python版本:3.7
- 主要收获:爬虫经验+100;python经验+100
主要会用到python和爬虫技术,入门级项目,偏简单,适合新人练手,看这个之前最好是对python和爬虫有一些了解
需求
需求名称:采集《python进阶》教程
网页:https://docs.pythontab.com/interpy/
需求:采集网页上的所有进阶内容,并整理成文档
采集具体的进阶教程内容即可
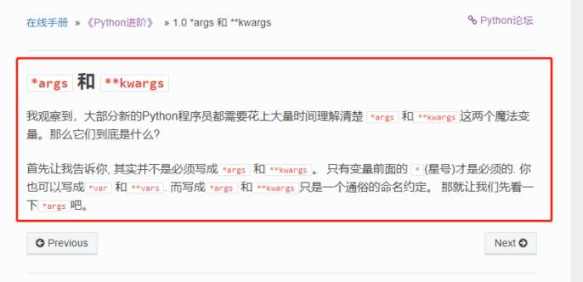
需求分析
我们看下需求,需要采集的东西并不是很多,我们先打开网页看一下

看下目录,数据量不是很多
大致数了一下就几十个页面,这很少了
对应下需求,根据经验,列下我们需要解决的一些问题
- 单页面抓取问题
- 多页面url获取问题
- 整理成文档
单页面抓取问题
这个问题其实就是看下抓取页面的请求构造
我们先找下源代码中是否有包含我们所需要的数据
在页面上找个稍微特殊的词

比如说 “小清新”
键盘按下ctrl+U查看下源代码
在按下ctrl+F,查找“小清新”

可以看到,源码中就直接有我们所需要的数据,那么可以判断,这八成就是一个get请求
如果没有反爬,那就比较简单了
直接构建一个最简单的get请求试一下
import requests
r = requests.get(\'https://docs.pythontab.com/interpy/\')
print(r.text)
print(r)
运行一下,打印输出的是有我们需要的数据(由于太多就不贴了),完美!
多页面url获取问题
我们可以看到所需要采集的页面几十个,并不是很多,就需求目标而言,我们其实是可以一个个的复制下来,但是这样没有技术范儿,而且如果说我们采集的页面很多呢,几百几千,甚至几十万,手动复制的效率实在过于低下
我们打开网页
可以看到有个Next按钮
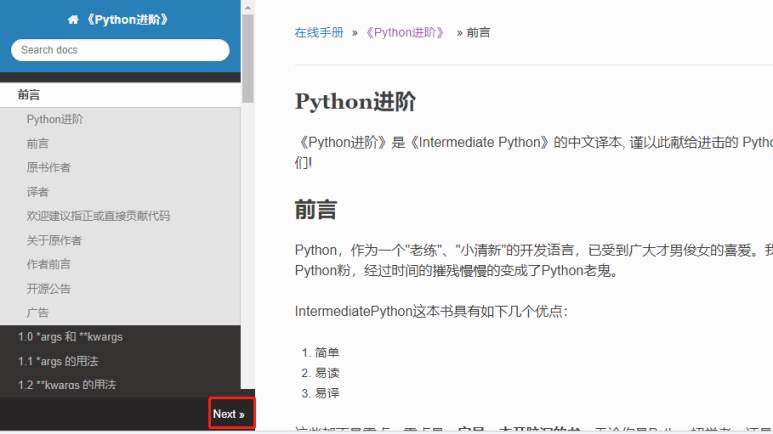
这里就有下一页的url
我们跳到最后一页,就会发现Next没有了
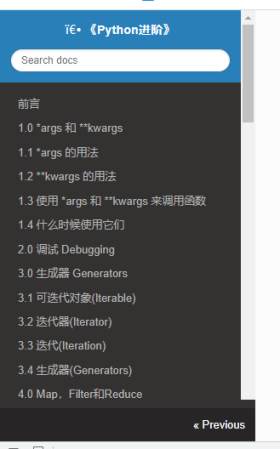
那么我们是不是就可以通过这种方式来拿到各个页面的url
我们一直去提Next按钮获取下一页的url,直到最后一页,没有Next,判断结束
整理成文档
本来想将抓取到的内容(去标签)保存成txt的,然后在转成pdf格式,好看一些
不过由于保存的内容没有格式,转换后并不好看,所以决定不去标签,直接存成html文件
然后在转换成pdf
这里有个在线的将html转成pdf,还是满好用的:https://www.aconvert.com/cn/ebook/
代码实现
逻辑理清了,代码实现就比较简单了
直接上下代码
import requests
from lxml import etree
from urllib import parse
def get_html(url):
"""网页采集数据,并保存到文件中
Args:
url (str): 待采集的url
Returns:
str: 下一页的url
"""
r = requests.get(url)
html = etree.HTML(r.text)
content = html.xpath(\'//div[@role="main"]\')
content0 = etree.tostring(content[0])
# print(content0)
with open("python进阶教程.html","ab+") as f:
f.write(content0)
_next = html.xpath("//a[contains(text(),\'Next »\')]/@href")
if not _next:
return \'\'
nexturl = parse.urljoin(url,_next[0])
print(nexturl)
return nexturl
url = \'https://docs.pythontab.com/interpy/\'
while 1:
url = get_html(url)
if not url:
break
运行代码会在当前目录生成一个python进阶教程.html文件
打开看一眼

还是可以的,不过我这里把它转换成更通用的pdf类型
html转换成pdf
先打开在线转换的网页:https://www.aconvert.com/cn/ebook/
选择html文件
选择转换的目标格式
点击转换
下载文件
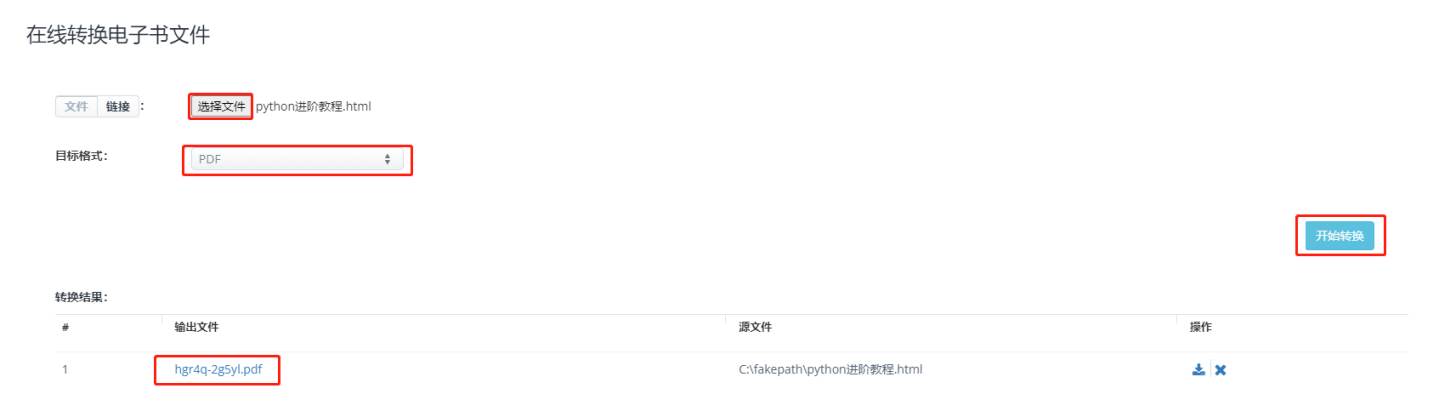
打开pdf看一下

格式还是很完美的!
注:
其实python有个pdfkit库,可以将一个html转换成pdf,有兴趣的朋友可以尝试下
关注我获取更多内容
注:转载还请注明出处,谢谢_
以上是关于[入门级项目]采集《python进阶》教程的主要内容,如果未能解决你的问题,请参考以下文章
前端进阶全栈入门级教程nodeJs博客开发(一)搭建环境与路由
前端进阶全栈入门级教程nodeJs博客开发(一)搭建环境与路由
前端进阶全栈入门级教程nodeJs博客开发(一)搭建环境与路由