「SDS极客」Spark On Kubernetes存算分离的最佳实践
Posted XSKY融合存储
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「SDS极客」Spark On Kubernetes存算分离的最佳实践相关的知识,希望对你有一定的参考价值。
前言
Kubernetes 作为当前最火的容器编排引擎,其具有强大的编排能力,能够对容器化的应用进行自动部署、扩缩和管理。Spark 作为 Hadoop 中举足轻重的运算框架,有着比 MapReduce 更好的性能,强大的特性(SparkSQL,Spark Streaming 等等)。那么如何在 Kubernetes 上运行 Spark 呢?如果加上 XSKY Hadoop Client(以下简称 XHC ) 呢?
Spark 在 v2.3 版本就开始支持容器化,并支持了通过 kubernetes 进行部署。而从 v3.0.0 开始,加入了更为方便的 pod template,支持 HCFS(Hadoop Compatible File System),Spark On K8S 支持 Kerberos 等特性,Spark 社区可谓是全面拥抱 kubernetes。
架构
如下图所示,在 XHC + Spark + kubernetes 组合中,XHC 存在于 Driver 以及 Executor 中,Spark 通过 XHC接口读取 XEOS 中的数据。
1、编译
环境
java:1.8.0_131
maven:3.6.1
2、下载源码
git clone https://github.com/apache/spark.git
3、执行编译
cd spark/
git checkout 2.4.7
./build/mvn -Pkubernetes -DskipTests clean package
4、制作 image
./bin/docker-image-tool.sh -r registry.xsky.com -t spark-2.4 build
5、运行 wordcount
部署 XHC,通过 XHC 一键部署工具部署即可。kubernetes 集群自行部署。
6、创建 configmap
创建 spark.properties 文件
注:spark.properties隐去了 xhc 的相关配置。
# cat spark.properties
spark.app.name=spark-wordcount
spark.app.id=spark-33b038d365ab4ad6b341bf0aa13bb458
spark.jars=file:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.7.jar
spark.driver.port=7078
spark.driver.host=spark-test-driver-svc.default.svc
spark.driver.blockManager.port=7079
spark.master=k8s://https://10.252.90.111:6443
spark.kubernetes.resource.type=java
spark.kubernetes.container.image=registry.xsky.com/spark:spark-2.4
spark.kubernetes.driver.pod.name=spark-test-driver
spark.submit.deployMode=cluster
spark.kubernetes.container.image.pullpolicy=Always
spark.kubernetes.submitInDriver=true
spark.executor.instances=3
##################
### xhc config ###
##################
重要说明:
spark.jars:为运行的应用,这里用了 Spark Example,WordCount
spark.driver.host=spark-test-driver-svc.default.svc:指定 driver 的host,主要需要与 svc 一致
spark.kubernetes.container.image=registry.xsky.com/spark:spark-2.4:指定 pod 使用的 image
spark.submit.deployMode:Spark 部署模式,这里使用 Cluster 模式
spark.executor.instances=3:指定 executor 的数量
xhc config:配置了与 XEOS 认证的关键信息,如:桶名、AccessKey(AK)、SecretKey(SK)等信息。
执行 kubectl create 创建 configmap
# kubectl create configmap test-config --from-file=spark.properties
说明:
test-config 为 k8s configmap 的名称
--from-file=FILENAME 将 FILENAME 文件中导入 configmap
FILENAME:本地文件名,默认使用文件名作为 configmap 中的 key,如需另指则使用 --from-file=KEY=FILENAME 配置
7、创建 svc
创建 spark-test-driver-svc.yaml 文件
# cat spark-test-driver-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: spark-test-driver-svc
namespace: default
spec:
ports:
- name: driver-rpc-port
port: 7078
protocol: TCP
targetPort: 7078
- name: blockmanager
port: 7079
protocol: TCP
targetPort: 7079
selector:
spark-app-selector: spark-selector1
spark-role: driver
sessionAffinity: None
type: ClusterIP
通过 kubectl create 创建 svc
# kubectl create -f spark-test-driver-svc.yaml
8、创建 Pod
创建通过 pod.yaml 文件创建 pod
注:pod.yaml隐去了 xhc 的相关配置。
# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
spark-app-selector: spark-selector1
spark-role: driver
name: spark-test-driver
namespace: default
spec:
#nodeSelector:
# kubernetes.io/hostname: k8s-2
#hostNetwork: true
containers:
#- command: ["/bin/sleep", "99999"]
- args:
- driver
- --properties-file
- /opt/spark/conf/spark.properties
- --class
- org.apache.spark.examples.JavaWordCount
- spark-internal
- xhc://localhost/
env:
- name: SPARK_DRIVER_BIND_ADDRESS
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: SPARK_LOCAL_DIRS
value: /var/data/spark-d76e771d-f660-4fb5-a3f6-88c668de5444
- name: SPARK_CONF_DIR
value: /opt/spark/conf
image: registry.xsky.com/spark:spark-2.4
name: spark-kubernetes-driver
ports:
- containerPort: 7078
name: driver-rpc-port
protocol: TCP
- containerPort: 7079
name: blockmanager
protocol: TCP
- containerPort: 4040
name: spark-ui
protocol: TCP
resources:
limits:
memory: 1408Mi
requests:
cpu: "1"
memory: 1408Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/data/spark-d76e771d-f660-4fb5-a3f6-88c668de5444
name: spark-local-dir-1
- mountPath: /opt/spark/conf
name: spark-conf-volume
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-9gzhl
readOnly: true
#dnsPolicy: ClusterFirstWithHostNet
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: k8s-2
priority: 0
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- emptyDir: {}
name: spark-local-dir-1
- configMap:
defaultMode: 420
name: test-config-1
name: spark-conf-volume
- name: default-token-9gzhl
secret:
defaultMode: 420
secretName: default-token-9gzhl
# kubectl create -f pod.yaml
执行结果
在 XHC 配置的存储桶 bucket-spark 中放了三个文本,每个文本中 10000 行数据,如下:

通过 kubectl logs PODNAME 方式获取执行结果:
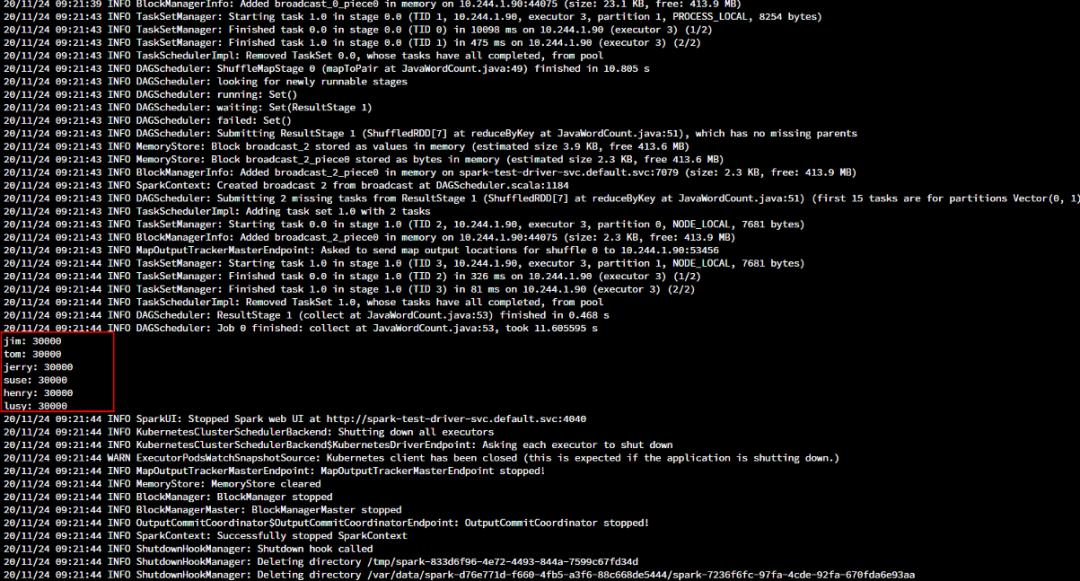
总结
综上所述,在 k8s 生态中使用 Spark 并不难,当然这里面也趟了不少坑。Spark + k8s + XHC 可谓是各司其职,k8s 做编排调度,Spark 负责计算,XHC 则提供给提供海量存储给计算使用,从而实现存算分离。XEOS 在存算分离中有着天然的优势,更有得盘率超高的 EC 特性加持,这种存算分离的架构再加上 Kubernetes 的调度编排,极大的提高的大数据场景计算和存储的利用率。配合 XHC 使用,服务于企业大数据平台,为企业云上大数据提供有力的支撑。
引用
https://spark.apache.org/docs/2.4.7/running-on-kubernetes.html#accessing-driver-ui
往期推荐
以上是关于「SDS极客」Spark On Kubernetes存算分离的最佳实践的主要内容,如果未能解决你的问题,请参考以下文章