Day66~(Redis)67
Posted jgcs123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day66~(Redis)67相关的知识,希望对你有一定的参考价值。
背景
例如,08年北京奥运,网上售票崩溃,12306购票崩溃
像一些网站的崩溃,都是因为,高并发,用户量比较大,而当时使用的是关系型数据库。关系型数据库,存在于磁盘中,那么要到cpu中计算需要
cpu—catch —-内存—–磁盘
而磁盘的io性能较低,
关系型数据库的数据逻辑关系复杂,不是适合做大规模集群
解决思路
降低磁盘IO次数,越低越好
去除数据关系。
故出现了在内存中存储,且不存数据关系,这就是Nosql,泛指非关系型的数据库,是对关系型数据库的补充。
常见的Nosql数据库
redis,hbase,MongoDB,memcache
Redis特征
1.数据间没有必然的关联关系。
2.内部采用单线程机制进行工作。
3.高性能。
4.多数据类型支持 String,list, hash, set, sorted_set
5.持久化支持,可以进行数据灾难恢复
Redis应用
-
为热点数据加速查询(主要场景),如热点商品,热点新闻,热点资讯
-
任务队列,秒杀,抢购,购票排队
-
即时信息查询,如各种排行帮,网站访问统计,公交到站信息,在线人数信息,设备信号等
-
时效信息控制,如验证码控制,投票控制
-
分布式数据共享,分布式集群架构中session分离
-
消息队列
-
分布式锁
Redis基本操作
功能性命令
信息添加
--设置Key,value 数据
--set key value
set name zhangsan
信息查询
--查询命令 如果空值 查询出 nil值
--get key
get name
Copy
清除屏幕信息
在window
--清除屏幕
clear
Copy
帮助信息查询
获取命令帮助
--help 命令名 可以help 加群组
help get
Copy
退出指令
quit
exit
<ESC>
Redis的数据类型
业务数据的特殊性
1.原始业务功能设计
-
秒杀
-
618活动
-
双十一
-
排队购票
2.运营平台监控到的突发高频访问数据
-
突发时政要闻,娱乐大瓜
3.高频复杂的统计数据
-
在线人数
-
投票排行榜
4.系统功能优化升级
-
单服务升级
-
对tocken的管理
Redis 是基于上述的功能需要设计出数据类型,推出了主要的5种数据类型。也是常用的五种数据类型,但其中数据类型并不止五种。
Redis 自身是一个Map,其中的所有数据都是采用Key:value的形式进行存储的
数据类型指的是存储的数据类型 Value部分,key部分永远都是字符串
String 类型
存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型
存储数据的格式:一个存储空间一个数据
存储内容:字符串,若字符串按照整数的形式展示、可以作为数字操作使用
String数据操作
--添加修改数据
set key value
--获取数据
get key
--删除数据
del key
--添加多个数据
mset key1 value1 key2 value2 key
--获取多个数据
mget key1 key2
--获取数据字符个数
strlen key
--追加信息,有就追加,没有就新建
append key value
--键key不存在时将key的值设置为value 若存在则不变
setnx key value
Copy
对于单数据操作和多数据操作,多数据操作节省,数据发送传递时间。
String类型数据扩展
数值增长
--增长指令,只有当value为数字时才能增长
incr key
incrby key increment
incrbyfloat key increment
--减少指令,有当value为数字时才能减少
decr key
decrby key increment
Copy
按照数值进行操作,如果原始数据无法转换成数值,或超越了redis数值的上限范围,将报错。 9223372036854775807(java中long型数据最大值,Long.MAX_VALUE)
设置数据生命周期
--设置时间 为values秒过期
setex key seconds value
--设置时间 为values毫秒过期
psetex key milliseconds value
Copy
后续的向相同的key中放值 会覆盖他的值 和过期时间,
数据最大的存储量 512MB
String类型业务场景
场景一:“最强女生”,启动海选投票,只能通过微信投票,每个微信号每4个小时只能投1票。
主页高频访问信息显示控制,例如新浪微博大V主页显示粉丝数与微博数。

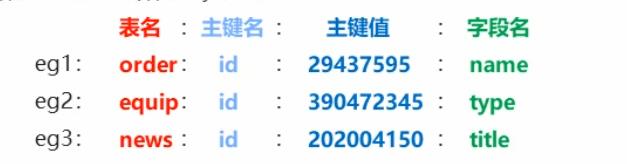
key的设置约定,在数据库中的表明:主键名:主键值:字段名
key的设置约定,在数据库中的表明:主键名:主键值:字段名
Hash类型
对一系列存储的数据进行编组,方便管理,典型应用存储对象信息。
一个存储空间保存多个键值对数据,
底层使用哈希表结构实现数据存储
hash数据操作
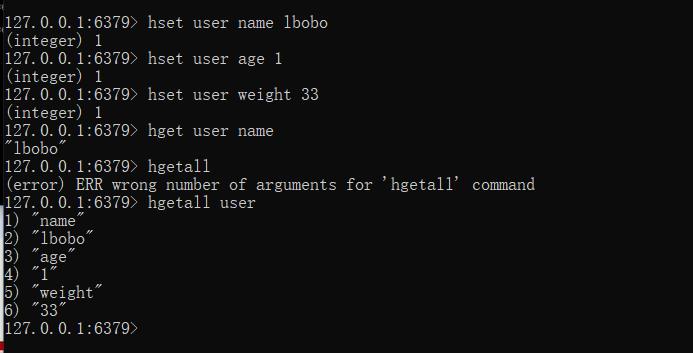
--添加数据
hset key field value
--获取数据
hget key field
hgetall key
--删除数据
hdel key field
Copy
--添加多个
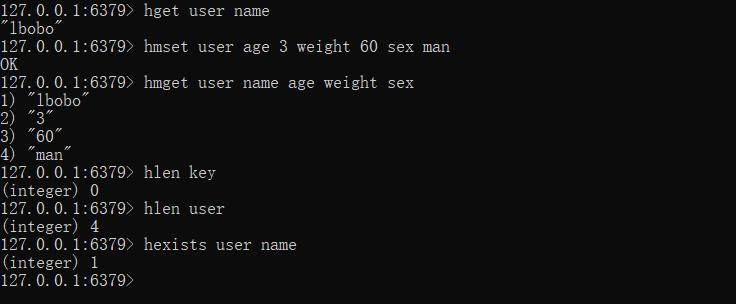
hmset key field1 value1 field2 value2
--获取多个
hmget key field1 field2
--获取哈希表中字段的数量
hlen key
--获取哈希表中是否存在指定的字段
hexists key field
Copy
hash类型数据扩展操作
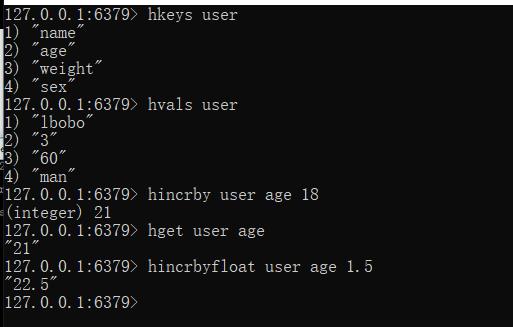
--获取哈希表中所有的字段名或字段值
hkeys key
hvals key
--设置指定字段的数值数据增加指定范围的值
hincrby key field increment
hincrbyfloat key field increment
--指定字段如果不存在,就增加,存在就不变,
hsetnx key field value
Copy
hash类型数据操作注意事项
-
hash类型下的value只能存储字符串,不允许存储其他类型数据,不存在嵌套现象。如果数据未获取到,对应的值为(nil)
-
每个hash可以存储232-1个键值对
-
hash类型十分贴近对象的数据存储形式,并且可以灵活添加删除对象属性。但hash设计初中不是为了存储大量对象而设计的,切记不可滥用,更不可以将hash作为对象列表使用
-
hgetall操作可以获取全部属性,如果内部fiekd过多,遍历整体数据效率就会很低,有可能成为数据访问瓶颈
hash类型应用场景
电商购物车设计与实现
将用户的id当成key
将商品编号当成 field
将商品购买数量当成 value,对value进行操作
取值 hget,
增加 hincrby
设值 hset
删除 hdel
全选 hgetall
总量 hlen
清空购物车 删除key
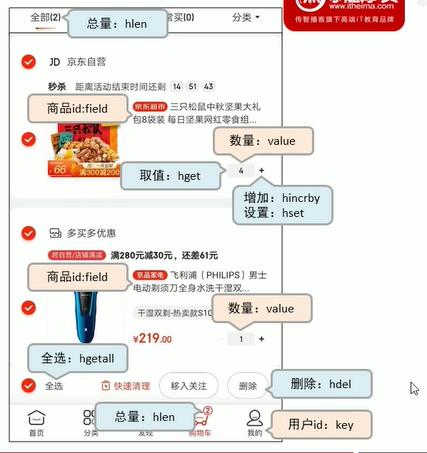
思考,当前设计是否增加购物车的呈现,
我们看上面的这张图时,我们主要看的商品信息,而不是数量,用户真正看的是,商品,然后再下单。商品的信息还要去查询数据库。
改进,我们将商品记录保存成两条field
field1:保存购买数量, value 数值
field2:保存用于购物车中显示的信息,文字,图片,商家
value json存储
不过一般购物车不持久化
抢购的设计

商家id当成key
参与抢购的商品id当成field
参与抢购商品的数量当成value
抢购时使用降值得方式控制产品数量,
尽量不要让redis去做 业务是否存在得判断
String整体型,读为主
hash分块,更新比较灵活
LIst类型
数据存储需求:存储多个数据,并对数据进入存储空间得数据进行区分。
需要得存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
底层使用双向链表存储结构进行实现
List数据操作
--添加修改数据 左添加,右添加
lpush key value1 [value2]
rpush key value1 [value2]
--获取数据
lrange key start stop
lindex key index
llen key
--获取并移除数据
lpop key
rpop key
Copy
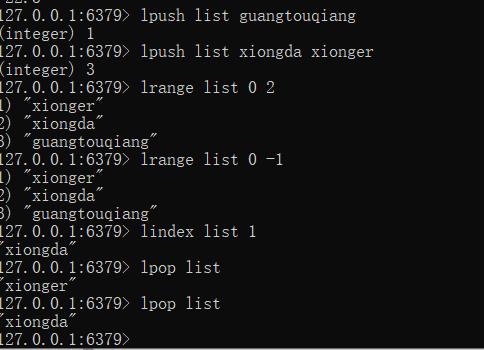
体会一下左进得顺序。
List数据操作扩展
规定时间获取并移除数据
blpop key1 [key2] timeout
brpop key1 [key2] timeout
Copy
再timeout 时间内取数据,有数据就取无数据就等待,
List数据业务场景
微信朋友圈点赞,要求按照点赞顺序显示点赞好友信息,如果取消点赞,移除对应好友信息。如果取消点赞,则移除指定数据
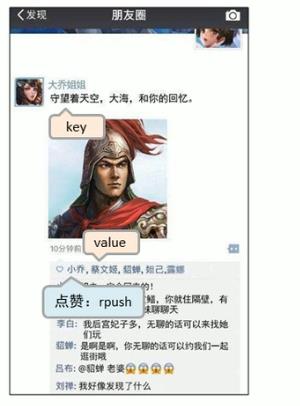
--移除指定数据
lrem key count value
Copy
注意这个数量,因为队列中得数列可以有重复值故要制定其个数,l是left从左边开始删除,count的值为value的元素
list类型数据操作注意事项
-
list 中保存的数据都是string类型的,数据总容量是有限制的,最多232-1个元素(4294967295)
-
list具有索引的概念,但是操作数据时候通常以队列的形式进行入队出队操作,或以栈的形式进入栈出栈的操作
-
获取全部数据操作结束索引设置为-1
-
list 可以对数据进行分页操作,通过第一页的信息来自list,第2页及更多的信息通过数据库的形式加载
Set类型
存储需求:存储大量数据,再查询方面提供更高的效率
需要的结构:能保存大量的数据结构,高效的内部的存储机制,便与查询。
set类型:与hash存储结构完全相同,仅存储键,不存储值,
Set的数据操作
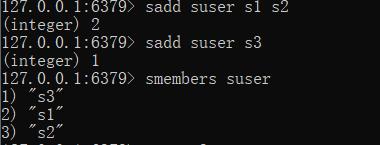
--添加数据
sadd key member1 [member2]
--获取全部数据
smembers key
--删除数据
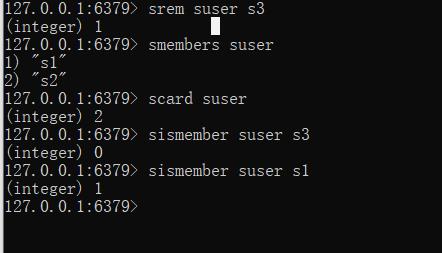
srem key member1 [member2]
--获取集合数据总量
scard key
--判断集合中是否包含指定数据
sismember key member
Copy
Set数据操作扩展
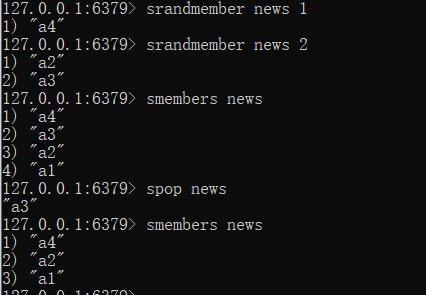
随机推荐
每位用户首次使用今日头条时会设置3项爱好的内容,但是后期为了增加用户的活跃度、兴趣点,必须让用户对其他信息类别产生兴趣,增加客户留存度,如何实现。
系统分析出各类最新的数据或最热的信息条目组成set集合
随机条选其中部分信息
配合用户关注的信息分类中的热点信息,组合抽取成全信息集合,例如:前6条你关注的第7条随机抽取的热点信息。
--随机获取集合中指定数量的数据
srandmember key [count]
--随机获取集合中的某个数据并将该数据移出集合
spop key
Copy
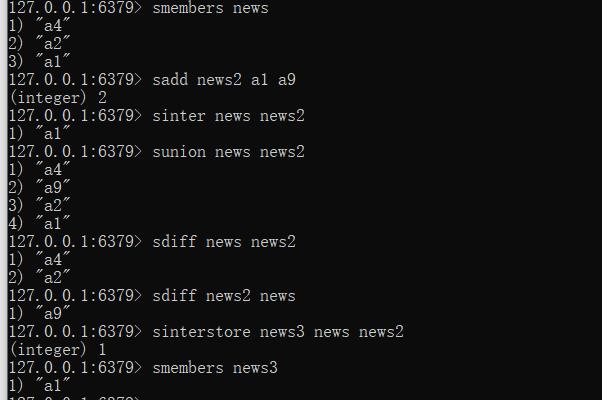
--求两个集合的交、并、差集
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]
--求两个集合的交并差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]
--将指定数据从原始集合移动到目标集合中
smove source destination member
Copy
Set类型操作注意事项
set类型不允许数据重复,如果添加的的数据已经存在将只保存一份
Set类型应用场景
权限控制
这个场景只为举例,具体的权限控制,有具体的权限框架。
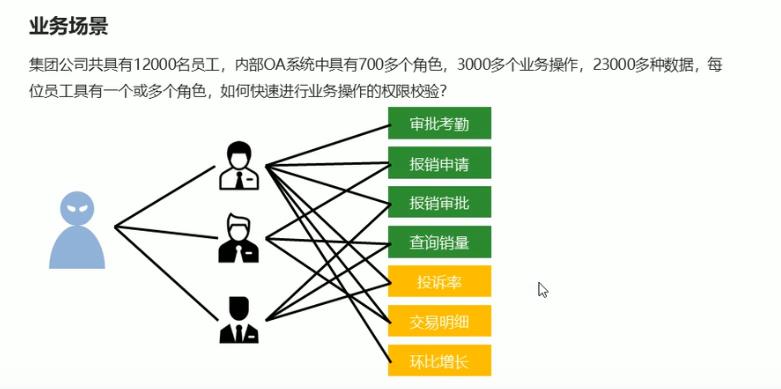
解决方案
-
依赖set集合数据不重复的特征,依赖set集合hash存储结构特征完成数据过滤与快速查询
-
根据用户id获取用户所有角色
-
根据用户所有角色获取用户所有操作权限放入set集合
-
根据用户所有角色获取用户所有数据全选放入set集合
网站的访问数据

解决方案
-
利用set集合的数据去重,记录各种访问数据
-
建立String类型数据,利用incr统计日常访问量(PV)
-
建立set模型记录不同cookie(UV)
-
建立set模型,记录不同IP数量(IP)
sorted_set类型
存储需求:数据排序有利于数据的有效展示,需要一种可以提供自身特征进行排序的方式
存储结构,在set存储结构基础上添加可排序字段。根据排序字段进行排序。

sorted_set基本操作
--添加数据
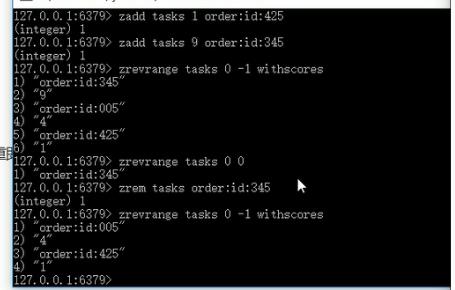
zadd key score1 member1 [score2 member2]
--获取全部数据
zrange key start stop [withscores]
zrevrange key start stop [withscores]
--删除数据
zrem key member [member ...]
Copy
--按照条件获取数据
zrangebyscore key min max [withscores] [limit]
zrevrangebyscore key max min [withscores]
--条件删除数据
zremrangebyrank key start stop
zremrangebyscore key min max
Copy
注意
-
min和max用于限定搜索条件
-
start和stop 用于限定查询范围,作用与索引
--获取集合数据总量
zcard key
zcount key min max
--集合交、并操作
zinterstore destination numkeys key [key ]
zunionstore destination numkeys key [key]
Copy
-
numkeys的值是后面key得个数,必须匹配。
-
注意交操作:只有都有的适合才会交,他默认将都有的值加起来了。
-
可以通过帮助命令来查看,求max值,min值
sorted_set 类型扩展操作
业务场景
活跃度统计,亲密度排序,榜单类
统计数量,排序
为所有参加排名得资源建立排序依据,根据排序后得结果获取索引
--获取数据对应的索引
zrank key member
zrevrank key member
--score值获取与修改
zscore key member
zincrby key increment member
Copy
sorted_set注意事项
-
score 保存的数据存储空间是64位,所以有范围。正负九百万亿
-
score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时侯要慎重
-
sorted_set底层存储还是基于set结构的,因此数据不能重复,如果重复添加相同的数据,score值将被反复覆盖,保留最后一次修改的结果
sorted_set应用场景
定时任务执行管理,任务过期管理
体验VIP,云盘体验VIP,当VIP体验到期后怎么管理。
解决方案
-
对于基于时间线限定的任务处理,将处理时间记录位score值,利用排序功能区分处理的先后顺序
-
记录下一个要处理的事件,当到期后处理对应的任务,移除redis中的记录,并记录下一个要处理的时间
-
当新任务加入时,判定并更新当前下一个要处理的任务时间
-
为提升sorted_set的性能,通常将任务根据特征存储成若干个sorted_set.例如1小时内,1天内,年度等,操作时逐渐提升,将即将操作的若干个任务纳入到1小时内处理队列中
-
获取当前系统时间
--获取当前时间,获取秒,毫秒。
time
Copy
任务或消息权重设定应用
对于带有权重的任务,优先处理权重高的任务,采用score记录权重即可
注意:这样可能无法保证原子性。这里再删除要用到事务。
KEY通用操作
key基本操作
--删除指定key
del key
--获取key是否存在
exists key
--获取key的类型
type key
--为指定key设置有效期
expire key seconds
pexpire key milliseconds
expireat key timestamp
pexpireat key milliseconds-timestamp
--获取key的有效期
ttl key
pttl key
--切换key从失效性转换为永久性
persist key
Copy
会返回三种值,当该key不存在时,返回-2,当该key未被设置有效期时,返回-1,当该key设置有有效期时,返回剩余时间。
当一个key被设置有效期后,有效期结束后,该key值将会被清空。
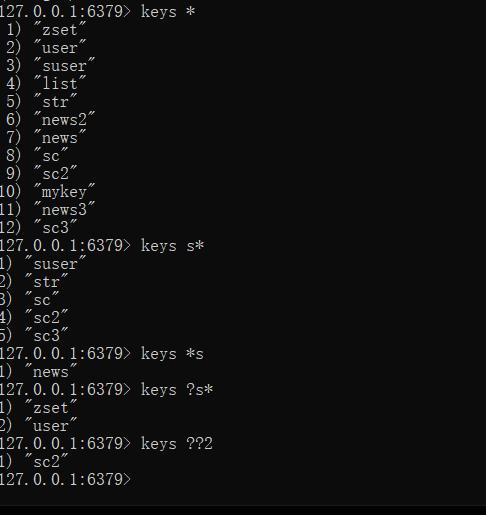
--查询key
keys pattern
* --匹配任意数量的任意符号
? --匹配一个任意符号
[] --匹配一个指定符号
Copy
--为key改名
rename key newkey
renamenx key newkey
--对所有key排序,再list,set,zset中。
sort
--其他key的通用操作,可以使用tab键进行切换
help @generic
Copy
改名操作,谨慎操作,如果错误改名,容易覆盖已有的值。
redis中的数据库
当数据量越来越大的时候,key值难免会发生重复,另外各种类型混杂在一起,易出现冲突。为此redis为每个服务提供了16个数据库,编号0到15,每个数据库之间数据相互独立。
--切换数据库 0-15
select index
--其他操作
quit
ping
echo massage
--移动数据,必须保证目的数据库没有该数据
move key db
--查看库中数据总量
dbsize
Copy
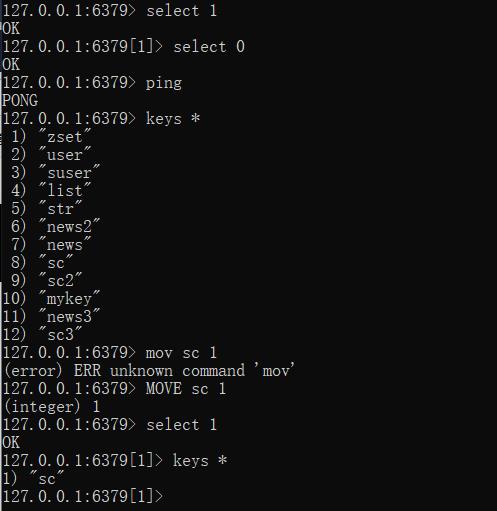
默认库是0库,使用move 操作是剪切,如果目标库中有相应的key则移动失败。
--库中元素数量
dbsize
--清除库中的所有元素
flushdb
--清除redis所有库中的所有元素
flushall
Copy
Jedis
JAVA操作Redis需要导入jar或引入Maven依赖
1.连接redis
2.操作redis
3.关闭连接
//参数为Redis所在的ip地址和端口号
Jedis jedis = new Jedis(String host, int port)
//操作redis的指令和redis本身的指令几乎一致,仅在此列出string和list
jedis.set(String key, String value);
jedis.lpush(String key, String value);
//关闭连接。
jedis.close();
Copy
编程案例
使用redis 控制不同用户,有不同免费使用次数。使用最大值控制异常减少次数判断。
public class Service {
String sa;
int num;
public Service(String sa, int num) {
this.sa=sa;
this.num=num;
}
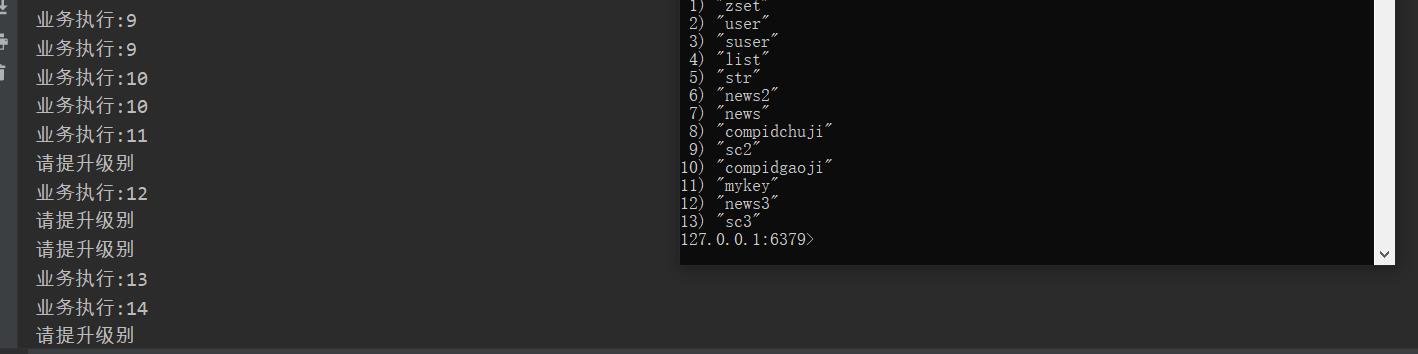
public void business(Long val) {
System.out.println("业务执行:"+val);
}
public void Service() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
String value = jedis.get("compid" + sa);
try {
if (value == null) {
jedis.setex("compid" + sa, 60, Long.MAX_VALUE - num + "");
} else {
Long incr = jedis.incr("compid" + sa);
business(incr-Long.MAX_VALUE+num);
}
} catch (Exception e) {
System.out.println("请提升级别");
} finally {
jedis.close();
}
}
}
class MyThread extends Thread {
Service sc;
MyThread(String sa,int num){
sc=new Service(sa,num);
}
@Override
public void run() {
while (true) {
sc.Service();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class main{
public static void main(String[] args) {
MyThread myThread1 =new MyThread("chuji",10);
MyThread myThread2=new MyThread("gaoji",20);
myThread1.start();
myThread2.start();
}
}
Copy
jedis工具类
public class JedisUtil {
private static Jedis jedis = null;
private static String host = null;
private static int port;
private static int maxTotal;
private static int maxIdle;
//使用静态代码块,只加载一次
static {
//读取配置文件
ResourceBundle resourceBundle = ResourceBundle.getBundle("redis");
//获取配置文件中的数据
host = resourceBundle.getString("redis.host");
port = Integer.parseInt(resourceBundle.getString("redis.port"));
//读取最大连接数
maxTotal = Integer.parseInt(resourceBundle.getString("redis.maxTotal"));
//读取最大活跃数
maxIdle = Integer.parseInt(resourceBundle.getString("redis.maxIdle"));
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(maxTotal);
jedisPoolConfig.setMaxIdle(maxIdle);
//获取连接池
JedisPool jedisPool = new JedisPool(jedisPoolConfig, host, port);
jedis = jedisPool.getResource();
}
public Jedis getJedis() {
return jedis;
}
}
Copy
redis.host=127.0.0.1
redis.port=6379
redis.maxTotal=30
redis.maxIdle=10
Copy
Redis持久化
利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化。
防止数据丢失。
持久化过程存什么
将当前数据状态进行保存,快照形式,存储数据结果,关注点在数据,RDB
将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程,AOF

RDB
RDB启动方式—save
命令
save
Copy
执行完之后,会在data文件夹中生成rdb文件,
RDB配置相关命令
在配置文件中改写。
-
dbfilename dump.rdb
-
说明:设置本地数据库文件名,默认值为 dump.rdb
-
经验:通常设置为dump-端口号.rdb
-
-
dir
-
说明:设置存储.rdb文件的路径
-
经验:通常设置成存储空间较大的目录中,目录名称data
-
-
rdbcompression yes
-
说明:设置存储至本地数据库时是否压缩数据,默认为 yes,采用 LZF 压缩
-
经验:通常默认为开启状态,如果设置为no,可以节省 CPU 运行时间,但会使存储的文件变大(巨大)
-
-
rdbchecksum yes
-
说明:设置是否进行RDB文件格式校验,该校验过程在写文件和读文件过程均进行
-
经验:通常默认为开启状态,如果设置为no,可以节约读写性过程约10%时间消耗,但是存储一定的数据损坏风险
-
Save指令工作原理
注意:save指令的执行会阻塞当前Redis服务器,直到当前RDB过程完成为止,有可能会造成长时间阻塞,线上环境不建议使用。
bgsave 指令工作原理
bgsave
Copy
bgsave命令是针对save阻塞问题做的优化。Redis内部所有涉及到RDB操作都采用bgsave的方式,save命令可以放弃使用,推荐使用bgsave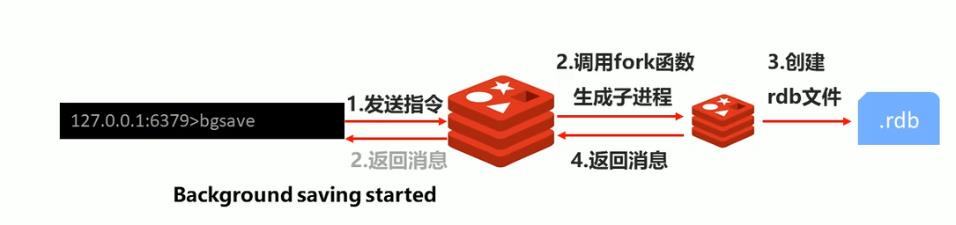
调用fork函数生成子进程。
自动保存save 配置
配置
在conf文件中进行配置
save second changes
Copy
以上是关于Day66~(Redis)67的主要内容,如果未能解决你的问题,请参考以下文章