揭秘HDFS联邦架构
Posted 数风云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘HDFS联邦架构相关的知识,希望对你有一定的参考价值。
文/张鸿
说到数据湖,我们一定会想到海量的数据规模和多样的数据类型,这就要求数据湖必须具备强大的数据存储能力。在数据湖的体系架构中,HDFS和对象存储是数据湖最为重要的两种存储引擎。今天我们主要介绍的是HDFS中的一个重要特性——HDFS联邦架构。
HDFS联邦架构(即HDFS Federation),是Hadoop 2.x的新增特性,它是指HDFS集群可同时存在多个Namenode,这些Namenode分别管理一部分数据,且共享所有Datanode的存储资源。HDFS联邦主要解决了Hadoop 1.x中单Namenode的瓶颈问题,通过扩展Namenode数量提升整个集群存储文件的数量和响应外部请求的能力。HDFS联邦架构更适用于像数据湖这种具有大规模Hadoop集群的应用场景。
接下来,让我们对HDFS联邦架构一探究竟。

Hadoop1.x的HDFS 采用单Namenode架构,主要由以下两大模块组成:
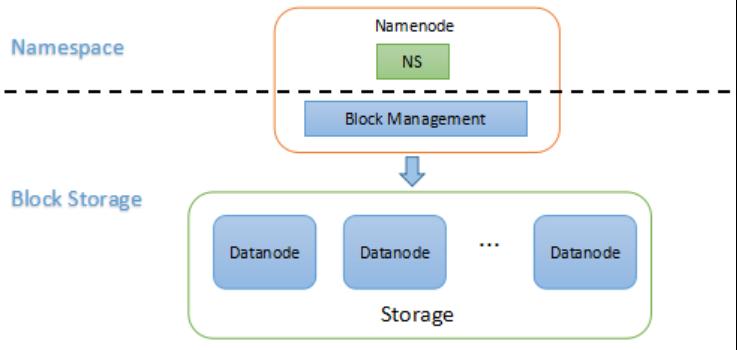
Namespace由目录、文件和块组成,它支持所有命名空间相关的文件操作,如创建、删除、修改,查看所有文件和目录。
块存储服务包括Block管理和存储两部分。
1) Block管理
通过控制注册以及阶段性的心跳,来保证Datanode的正常运行;
处理Block的报告信息和维护块的位置信息;
支持Block相关的操作,如创建、删除、修改、获取Block的位置信息;
管理Block的冗余信息、创建副本、删除多余的副本等。
2) 存储
Datanode提供本地文件系统上Block的存储、读写、访问等。
单组Namenode只允许整个集群有一个活动的Namenode,管理所有的命名空间。随着集群规模的增长,在1000个节点以上的大型Hadoop集群中,单组Namenode的局限性越发的明显,主要表现在以下几个方面:
由于Namenode在内存中存储所有的元数据(metadata),因此单个Namenode所能存储的对象(文件+块)数目受到Namenode所在JVM的heap size的限制。按照经验估算,1G内存大约可以存储100万个对象。按照单台服务器256G内存来估算,Namenode最多可存储2亿多个对象。
由于Namenode没有隔离性设计,单一对Namenode负载过高的应用,会影响到整个集群的服务能力,HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。
由于是单个Namenode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个Namenode的吞吐量。随着集群规模增长,Namenode响应的RPC QPS也在逐渐提高。越来越高并发的读写,与Namenode的粗粒度元数据锁,使Namenode RPC响应延迟和平均RPC队列长度都在慢慢提高。
既然单组Namenode存在上述局限性,那么为什么要通过联邦架构的方式横向拓展Namenode,纵向拓展Namenode为什么不行?不选择纵向拓展Namenode的原因主要体现在以下三个方面:
Namenode启动需要将元数据加载到内存中,具有128 GB Java Heap的Namenode启动一次大概需要40分钟到1个小时,那如果配置512GB甚至更大的内存,启动时间不可接受。
Namenode在Full GC时,如果发生错误将容易导致整个集群宕机。
元数据文件fimage过大,NN合并传递消耗更多的资源。
HDFS 联邦架构主要用于构建数据湖中的大型Hadoop集群,该集群具有以下特点:
1、文件数量非常多:数据湖中文件数达到数亿甚至更多。
2、单一集群规模大:数据湖的Hadoop集群规模达到数百台甚至更多。
3、各业务场景需要隔离:数据湖多种业务场景共同部署在一个物理集群,各业务之间要求互不影响。
联邦架构与单组Namenode架构相比,主要是Namespace被拆分成了多个独立的部分,分别由独立的Namenode进行管理。
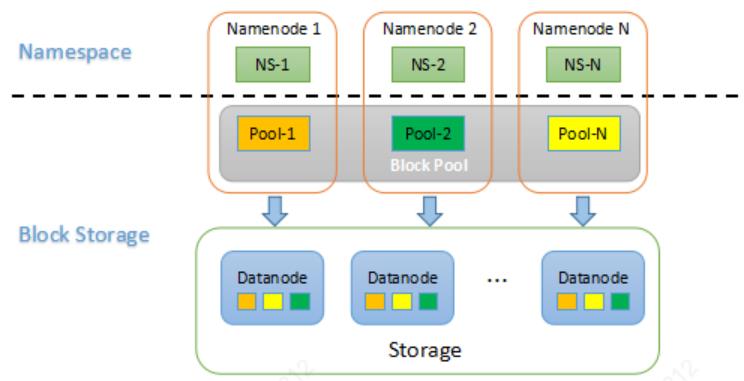
为了水平扩展Namenode,HDFS联邦架构使用了多个独立的Namenode/Namespace。这些Namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。
分布式的Datanode被用作通用的数据块存储设备。每个Datanode要向集群中所有的Namenode注册,且周期性地向所有Namenode发送心跳和块报告,并执行来自所有Namenode的命令。

HDFS联邦架构中存在多个命名空间,如何划分和管理这些命名空间非常关键。在联邦架构中并未采用“文件名hash”的方法,因为该方法的locality(局部性)非常差,比如:查看某个目录下面的文件,如果采用“文件名hash”的方法存放文件,则这些文件可能被放到不同Namespace中,HDFS需要访问所有Namespace,代价过大。
为了方便管理多个命名空间,HDFS 联邦架构采用了经典的Client Side Mount Table。
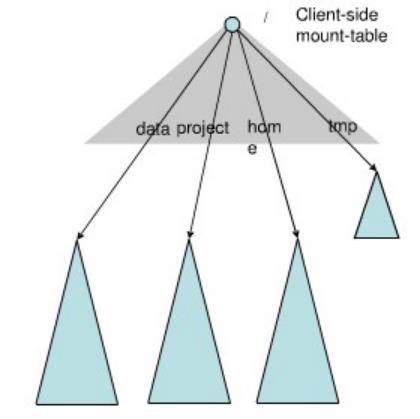
如上图所示,下面四个蓝色三角形代表一个独立的命名空间,上方灰色的三角形代表从客户角度去访问的子命名空间。各个蓝色的命名空间Mount到灰色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。
HDFS 联邦架构中命名空间管理的基本原理:将各个命名空间挂载到全局mount-table中,就可以做将数据到全局共享;同样的命名空间挂载到个人的mount-table中,这就成为应用程序可见的命名空间视图。
HDFS 联邦架构引入了块池(Block Pool)的概念。块池管理的原理如下:
一个Block Pool由属于同一个Namespace的数据块组成,每个Datanode可能会存储集群中所有Block Pool的数据块。
每个Block Pool内部自治,也就是说各自管理各自的Block,不会与其他Block Pool交流。一个Namenode挂掉了,不会影响其他Namenode。
某个Namenode上的Namespace和它对应的Block Pool一起被称为Namespace volume。它是管理的基本单位。当一个Namenode/Namespace被删除后,其所有Datanode上对应的Block Pool也会被删除。当集群升级时,每个Namespace volume作为一个基本单元进行升级。
2.3.3
HDFS联邦的挂载点配置,本质上就是HDFS虚拟路径与nameservice路径的映射关系,所以可以在默认挂载点配置存在的情况下,业务可以增加自己的映射关系,屏蔽属于不同联邦的目录,来实现业务在目录路径上的无感知切换。
举个例子,数据湖的用户需要用到/dir/dir1、/dir/dir2、/dir/dir3这三个既定业务目录下的文件,放在平台安装的hdfs://ns1和hdfs://ns2两个联邦nameservice中。
可以如下配置:
/dir/dir1 --> hdfs://ns1/任意目录 /dir/dir2 --> hdfs://ns1/任意目录 /dir/dir3 --> hdfs://ns2/任意目录 |
也就是说,业务想用到什么目录,可以映射到具体的nameservice目录上,然后业务直接用业务自己的目录就可以了。
这个配置是写入到HDFS的配置文件core-site.xml中,并且是客户端参数,不需要HDFS服务重启,只要配置文件修改就立即生效。
数据湖采用HDFS联邦架构的最主要的原因是,联邦架构能够解决数据湖大规模Hadoop集群面临的单Namenode的问题。
1) HDFS集群扩展性。多个Namenode分管一部分目录,使得一个集群可以扩展到更多节点,不再由于内存的限制制约文件存储数目。
2) 性能更高效。多个Namenode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
3) 良好的隔离性。用户可根据需要将不同业务数据交由不同Namenode管理,这样不同业务之间影响很小。
在解决Namenode扩展能力方面,社区虽然提供了联邦架构,但这个方案有很强的局限性:
HDFS联邦架构并没有完全解决单点故障问题。虽然Namenode/Namespace存在多个,但是从单个Namenode/Namespace看,仍然存在单点故障:如果某个Namenode挂掉了,其管理的相应的文件便不可以访问。
HDFS 联邦架构采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入以达到理想的负载均衡。
HDFS 联邦架构是改造了客户端的解决方案,重度依赖客户端行为,对客户端不透明。当增加了Namenode,并且进行了Namespace拆分后,如果客户端的挂载点不及时更新,有可能导致客户端的访问是合法但不符合预期。
HDFS联邦是Hadoop2.X提供的增强特性,旨在解决数据湖中单Namenode在集群扩展性不足、性能存在瓶颈、业务无法隔离等问题,但是联邦架构目前仍然存在一些不足之处。相信随着Hadoop不断迭代演进,未来HDFS联邦技术也将更加成熟。

顾问:许国平 李湘宜
罗学平 刘德清
张刚 付佳
总编:孙鹏晖
编辑:韩翠娟
美编:韩翠娟


-本文为“数风云”第35期文章;
-欢迎来稿:请按“题目-作者”格式命名发送到sunpenghui@abchina.com。
以上是关于揭秘HDFS联邦架构的主要内容,如果未能解决你的问题,请参考以下文章