浅谈2021搜索引擎几大核心算法,网站专利解读,值得一阅
Posted 爱学SEO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈2021搜索引擎几大核心算法,网站专利解读,值得一阅相关的知识,希望对你有一定的参考价值。
浅谈2021搜索引擎的几个核心算法和专利解释,事实上搜索引擎算法是非常多的,除了一些算法公布,还有一些算法是内部机密,我们作为 seo 人员需要知道尽可能多的关于搜索引擎算法。 (最低部有领取资料渠道)
你知道搜索引擎有什么算法吗?之前我们学习了搜索引擎的基本操作原理。搜索引擎的原理是在搜索引擎算法的框架内运行,而关键词排序的真正影响是搜索引擎算法,已发表的搜索引擎算法只是搜索引擎系统的一个缺陷修复。
其实搜索引擎除了已公开的算法,还有很多未公开的内部保密算法,我们作为SEO人员只需简单了解搜索引擎算法就行了,找出一些规律供我们使用,了解搜索引擎算法也不是为了作弊,而是为了更好的为用户提供优质的内容,提升网站对搜索引擎的友好度,下面主要来给大家讲讲搜索引擎最重要的两个核心算法,作为SEO人员必须要对以下两种算法有基本的了解。
1、搜索引擎核心算法
每个搜索引擎平台都有自己的算法,不知道大家平时是否有研究搜索引擎算法的习惯,例如百度、谷歌google、搜狗、360搜索、bing必应等这些搜索引擎平台的算法,那么如何研究搜索引擎算法了?例如我们可以通过网站实验进行研究,也可以研究搜索引擎已公布的算法规则,不管是什么搜索引擎,都有首自己一套独立的核心算法体系,主要作用是对网页文本识别和词频分析。
也许有的人站长会有这样的疑问,为什么同个关键词在不同的搜索平台排名是不一样的呢?其实这种问题确实是比较常见的,虽然所有搜索引擎运行原理大致是一样的,但不同的搜索引擎平台的核心算法是不一样的,所以也就出现了同个关键词不同的搜索平台排名不一样的结果。
搜索引擎核心算法解读
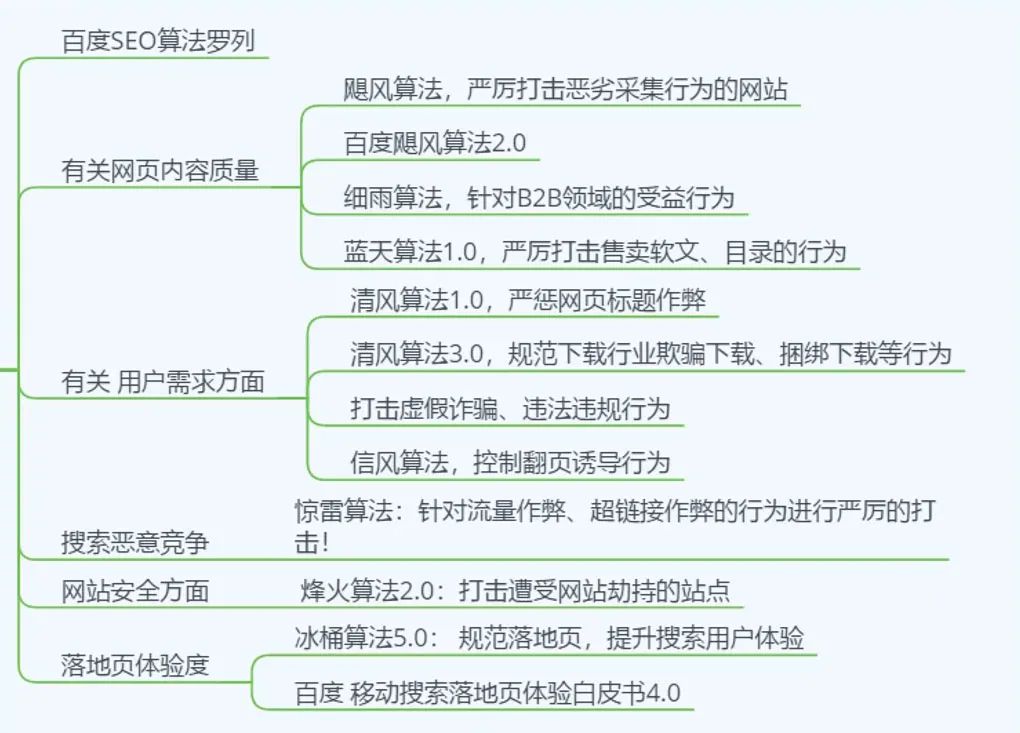
1)一般性算法
我们有时候看到搜索引擎经常发布更新算法,其实这些算法都是搜索引擎的一些小算法,主要作用是对搜索引擎系统的完善与修复,还有就是提醒站长,对网站这块不合格的地方尽快改正,否则将会对这块地方进行打击,目前百度搜索引擎公布的小算法有飓风算法、细雨算法、蓝天算法等,360公布的算法有悟空算法和哪吒算法。
2)核心算法解析
任何搜索引擎都是基于这两种算法,一种是TF-IDF算法,另一种为BM25算法。
(1)了解TF-IDF算法
TF-IDF算法是一种关于网页文本的算法,任何搜索引擎平台都是对于网页文字内容的识别,抓取你的网站链接,分析你网站文本内容,计算网站关键词的相关性及频率,这些都是基本TF-IDF文本算法,这种算法不适用普通人研究,只适合于科学家研究,我们普通人没有必要深入研究它,因这个算法真的是超级烧脑,我们只面要进行初步了解,对搜索引擎算法有更深一步的认识就行了。
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,看上去虽然有点高大小,但其实就是一种统计方法。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
解释:意思是一个字或词语在一篇文章中的占比程度,哪些更重要,哪些不重要,字词的重要性简单地讲指的就是词频,增加这个字或词的频率,搜索引擎也就是基于这个对文章内容进行识别的。
百度百科对TF-IDF算法的解释:
TF-IDF是一种网页文字统计方法,用以评估某个关键词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF算法的作用:
可以帮助搜索引擎计算此文章页面字或词频,词频高则认为这个字或词很重要,自然给你的得分就会高,如果这个字或词频率低,那么此页页得分就会低,大家也可以根据以下TF-IDF公式进行理解:

以上公式主要针对计算文章页面字或词出现频率的解读,通过这个公式进行罗列,百度搜索和谷搜索都在用TF-IDF算法,下面大兵大家进行相应的解读。
TF-IDF算法计算公式

逆向文件频率(Inverse document frequency,IDF)IDF的主要思想是:如果包含词条文档越少,IDF越大,则说明词条具有很好的类别区分能力,某一特定词语的IDF,可以由总文件数目以包含该词语之件的数目,再将得到的商取对数得到。

TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间的相关程度的度量或评级,除了TF-IDF以外,因特网上的搜索引擎还会使用基于连结分析评级方法,以确定文件在搜寻结果中出现的顺序。
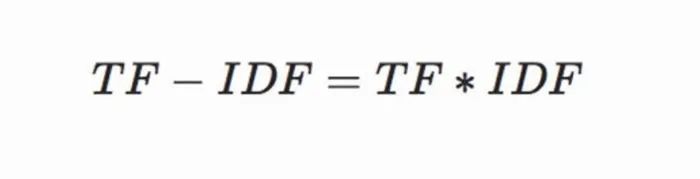
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤常见的词语,保留重要的词语。
和道了“词频”和“逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值,某个词对文章的重要性越高,它的TF-IDF值就越大,所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的简单分享。
第一步、计算词频

第二步、计算逆文档频率

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0,分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。logo表示对得到的值取对数。
第三步、计算TF-IDF
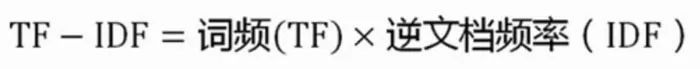
一个词语在一篇文章中出现的次数越多,同时在所有文档中出现的次数越少,越能够代表该文章,这也是就是TF-IDF的含义。
关于“TF-IDF算法”原理详细解答,点击《TF-IDF算法解释,TF-IDF算法原理及公式》看这篇文章。
有些站长看了以上TF-IDF算法原理的介绍,觉得既然文章内容中关键词的词频越高排名越好,那是不是可以向文章内容中加入大量的关键词,提高该关键词在该文章的密度呢?对于这种问题搜索引擎就推出了第二种算法BM25算法,主要针对的就是大家提出的关键词密度问题,下面一起来看看。
(2)了解BM25算法
BM25算法其实是TFIDF相关性的升级版本,既然是关键词在文章中出现的频率越高排名越好,这就会导致大量站长作弊,例如在一篇文章中插入大量的关键词,提高该关键词在文章出现的频率,其实这种操作方法是正确的。
人为故意增加关键词出现的频率属于作弊优化方法,于是搜索引擎就推出了BM25算法,对你文章内容中关键词的词频进行二次审核,审核文章内容中出现的高频关键词是否与文章具有相关性,例如文章出现的高频关键词与文章主题不相关,也不相匹配,那么搜索引擎就会判断这篇文章内容为作弊的文章,由此可见人为增加文章内容中关键词频率的方法是错误的。

以上搜索核心算法较深奥,适合做搜索算法研究和工具工发类站长研究,SEO站长们可作为课外资料学习了解,不需要深究。
3、百度搜索专利技术解析
搜索算法是搜索引擎内部核心运作的一个系统,我们可以通过搜索引擎官方发布的一些专利去研究解读搜索引擎专利技术,研究出来对我们SEO搜索排名有哪些帮助,这个我们也是需要进行了解的。
虽然搜索专利技术的多少代表着搜索引擎公司的核心市场竞争力,搜索专利越多意味着他们掌握着搜索核心技术越多,一个做搜索引擎公司的技术如何,我们看这个搜索引擎公司有多少搜索专利技术就知道了。
我们通过研究搜索引擎的专利技术,可帮助我们更好的了解搜索引擎,从而帮助我们实现更好的SEO效果。
百度搜索大概有70多个搜索专利技术,下面我们给大家解读几个重点的搜索专利技术。
前面我们说过一篇网页可以通过词频获得更高的得分,从而获得网页关键词排序的优先权,那么百度搜索引擎如何知道词频内容是不是我们特意加的呢?关于这个问题百度就发明了以下这个专利技术。
1、对话内容连贯性的判断方法、装置以及设备的搜索专利技术
本发明提出一种对话内容连贯性的判断方法,包括:将上文语句输入至语句生成模型中,生成下文语句:
计算每个上文语句与当前语句之间的相似度,以构建第一相似度矩阵;
计算每个下文语句与当前语句之间的相似度,以构建第二相似度矩阵;
将第一相似度矩阵和第二相似度矩阵分别输入至连贯性判别模型中,生成当前语句的连贯性特征参数,连贯性判别模型是基于神经网络构建的。利用连贯性判别模型和语句生成模型相结合的方式,来解决对话内容连续性问题,可以从语义的维度比对两个句子的连贯性,推送给用户回复连贯性且优质的回复。本发明还提供了一种对话内容连贯性的判断装置以及设备。
对“对话内容连续性的判断方法、装置以及设备”搜索专利技术解读:
(1)“本发明提出一种对话内容连贯性的判断方法”
解读:意思是判断你网页内容是否连贯,对于这个搜索引擎是有一套专业的搜索算法能够发现识别你的网页内容是否连贯,例如你的网页内容上部分讲的是“红烧肉如何做”,而下部分内容却讲的是“女人如何穿搭衣服才更好看”,这样的内容就属于典型的上下内容不连贯不相关。
(2)“计算每个上文语句与当前语句之间的相似度,以构建第一相似度矩阵;计算每个下文语句与当前语句之间的相似度,以构建第二相似度矩阵;将第一相似度矩阵和第二相似度矩阵分别输入至连贯性判别模型中,生成当前语句的连贯性特征参数”这代表的意思是什么呢?
解读:搜索引擎截取你网页内容第一段,再截取你网页内容第二段,两段内容进行相似度的对比,生成一个特征码,再用这个特征码进行判断文章内容之间是否存在关联性。
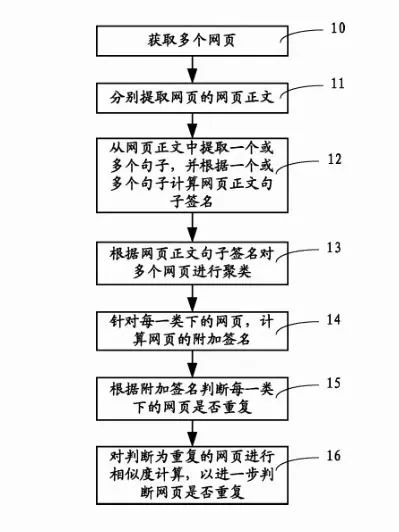
2、一种网页重复的判断系统及其判断方法的搜索专利技术
本发明专利公开了一种网页重复判断系统及判断方法。该判断方法步骤是:先提取网页正文内容;从网页正文中提取一个或多个句子,并根据一个或多个句子计算网页正文句子签名;根据网页正文句子签名对多个网页进行聚类;针对每一类下的网页,计算网页的附加签名;根据附加签名判断每一类下的网页是否重复。通过上述方式,网页重复判断系统及判断方法利用网页正文句子签名在内的多维度签名有效且快速地判断网页是否有重复。
解读:搜索引擎系统会提取网页正文内容,分析每个网页中的一个或多个句子找到其规律计算网页正文句子签名,并且这个签名内容是全网唯一的,如果你的这个签名在全网内容中出现的频率高,意味着这个网页内容是重复的,如果你的这个签名重复率不高,则意味着这个网页内容是原创不重复的,因此搜索引擎系统只需要判断网页签名内容的频率,频率越高内容重复度越高,频率越低内容重复度就越低。
可以简单理解为网页签名内容频率越高,内容质量越低,网页关键词排名就越差,反之关键词排名就越好。
以上就是我对于这条搜索专利技术简单的理解,具体如何实现的,可参考如下这张图。
网页内容重复的判断系统已经是自动化运作了,如果你从A网站复制一段内容,B网站复制一段内容进行拼凑成一篇内容,这样的内容算不算高质量内容呢?其实无论你再如何拼凑,搜索引擎系统对网站内容的签名是改变不了的,搜索系统根据你的网页签名内容对比搜索引擎索引库内容进行对比,发现你的内容还是重复的,因为搜索引擎签名内容是不会变的。
现在靠采集抄袭别人网站内容,来达到排名目已经很难实现了。
3、用于处理点击行为数据的方法和装置的搜索专利技术
解读:早在2018年就有很多站长利用所谓快排技术,以虚拟点击方式增加网页虚拟点击及虚拟流量ip,试图通过点击的方式为网站带来虚拟流量,针对这种黑帽操作方法搜索引擎于是就发明了“用于处理点击行为数据的方法和装置”的搜索专利技术,利用这个搜索专利技术靠虚拟点击模拟人工点击是可进行识别出来的。
该搜索专利技术具体运行原理如下图所示:
先获得正常用户点击的行为数据,然后对这些数据进行建模,生成一个特征设备标识,当下次网站点击行为与正常用户点击行为数据模型不一样的时候,系统就会判断你的网站可能存在一种非正常用户点击行为,例如你的网站正常流量为100IP,突然暴增到10000IP,此时系统就会判断你的网站流量暴增是不符合正常规律的,是存在恶意非人工的点击行为,系统会对你近期的流量数据与原始行为数据进行对比,找出你是不是通过点击算法作弊来实现你网站流量的暴增,搜索引擎系统会对这些点击行为数据进行分析,这些数据搜索引擎系统都可以进行判断识别的,因此你认为现在通过虚拟用户点击行为来达到关键词排名目的还可以行吗?
自2019年开始,黑帽优化站点陆续都被搜索引擎惩罚了,搞快排、买IP,买PV,买流量这些作弊方法都违反了正常用户点击行为数据,因此就很容易被搜索引擎算法命中,并对网站进行打击,被打击的直接表现是网站关键词排名突然间就没有了,为什么网站关键词排名突然没有了?因为你的的黑帽作弊优化方法命中了搜索引擎反作弊的系统,系统认为你在人为操控流量点击,这种情况就容易被搜索引擎算法打击,比如限制你网站内容展示,限制你网站关键词的排名,甚至直接你的网站关键词排到100名以后,这些都是搜索引擎对站点惩罚的表现,因此靠欺骗搜索引擎的黑帽优化方法建议大家远离,不要觉得你用黑帽优化方法目前搜索引擎系统还识别不到。
通过了解搜索引擎专利技术,原来这么多网站优化技巧我们是不知道的,我们为什么要了解搜索引擎专利技术呢?我们可以通过科学专业角度更多去理解搜索引擎,了解搜索引擎运行原理,帮助我们远离作弊,远离一些非法违规操作,避免网站优化走上弯路。
4、搜索算法及总结
1)要了解搜索引擎规则,需要了解搜索算法
我们可以使用相关工具和搜索算法工具来理解搜索引擎。
(1)摩天楼SEO工具
(2)检测并提升TF-IDF得分
(3)第三方SEO算法工具
2)任何高级算法的目标都很简单: 尽最大努力满足用户的需求
对SEO感兴趣的同学,可以关注我或者直接私信我,领取更多SEO学习资料。
以上是关于浅谈2021搜索引擎几大核心算法,网站专利解读,值得一阅的主要内容,如果未能解决你的问题,请参考以下文章