编译器中的图论算法
Posted 程序芯世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译器中的图论算法相关的知识,希望对你有一定的参考价值。
编译器中的图论算法
1. 前言
LLVM是一款开源的编译器框架,近年来已经逐渐超越GCC。
许多深度学习编译框架TVM、Tensorflow XLA的后端也是使用的它。 正是由于其友好的Lisense,模块化及统一的IR,使得其越来越流行。因此对LLVM的研究很有必要。
文中介绍了LLVM中构造支配树的两种算法,分别是SLT算法与Semi-NCA算法。构造支配树的算法,就是图论在编译器中的一个应用。如果蜕去LLVM的外衣,相信很多参加过ACM比赛的选手应该对支配树的构造很熟悉。
本文的目的是以一种通俗易懂的方式给需要了解这个算法的朋友一个感性的认识。如果需要看原论文或者关于深度学习编译器论文的可以后台回复idom获取。
2. 支配树简介
2.1 支配树定义
对于一张有向图(可以有环),我们规定一个起点 ,从 点到图上另一个点 可能存在多条路径,对于从 到 的任意路径中,都存在一个点 ,即从 到 必须经过 ,那么我们称 为 的支配点。
用 表示离点 最近的支配点, 对于原图除 外,每一个点 ,从 向 建一条边,最后我们得到了一颗以 为根的树,这棵树就是支配树(Dominator tree)
2.2 支配树在编译器中的应用
-
计算支配边界,构造SSA -
循环不变量提升
更多应用欢迎补充。
3. 基本概念
3.1 DFS树
对图进行深度优先遍历得到的一颗树称为DFS树。树上的每一个节点都有一个按照深度优先遍历的顺序得到的编号。
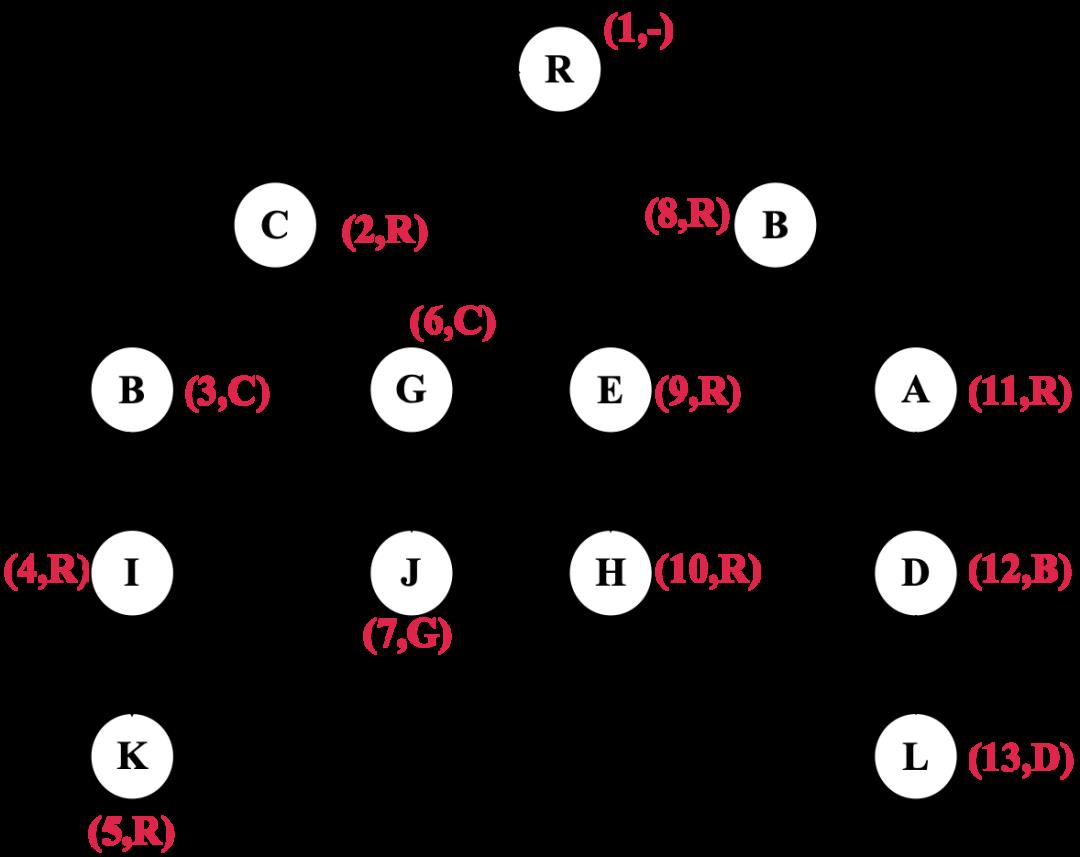
如图2所示,节点和实线虚线共同构成了一个有向图,对有向图进行深度优先遍历就形成了DFS树。其中实线是DFS的树边。红色数字表示按照深度优先遍历的顺序得到的编号,红色字母表示该节点的半必经节点。
3.2 树边与非树边
如果在DFS树中存在一条由
到
的边,则顶点
是顶点
的父节点,这条边称为树边。
记作
如果在有向图中存在一条
到
的边,则顶点
是顶点
的前驱节点。注意要与父节点相区别,因为父节点是在DFS树上存在由
到
的边。
到
的边中除去树边以外的边称作非树边。
的前驱节点记作
非树边记作
如图2中 是 的父节点。 到 的边为树边
3.3 祖先与完全祖先
是
的祖先,如果在DFS树中存在一条由
到
的路径,
可以等于
。
记作
如图2中 都是 的祖先,因为这些点都可以沿着实线边(DFS树边)到点
是
的完全祖先,如果在
树中存在一条由
到
的路径,
不等于
。
记作
如图2中 都是 的完全祖先,因为这些点都可以沿着实线边(DFS 树边)到点 。与祖先的唯一区别就是不包括 自身。
3.4 横跨边与返祖边
右子树的节点指向左子树节点的边。横跨边的起点永远大与终点编号,因为DFS树中右子树的遍号永远大于左子树的编号。
记作
如图2所示, 的这四条边都是横跨边
子节点到其完全祖先的边叫返祖边。
记作
如图2所示, 这两条边都是返祖边。
4. 半支配路径与半支配节点
在求支配节点之前,我们首先需要了解半支配路径,然后求出半必经节点及必经节点,最终得到整个支配节点树。

4.1 半支配路径
公式表示:
通俗解释:
在DFS树中存在一条路径,如果这条路径中(不包括起点和终点)的每一个点的编号都大于终点的编号,则该路径为一条半支配路径。
根据定义可以将半支配路径分为两类:
-
树边半支配路径
树边半支配路径比较特殊,只包含两个点,这两个点在一条树边上。
-
非树边半支配路径
非树边半支配路径即路径上指向终点的边为非树边,这条非树边要么是横跨边要么是返祖边。
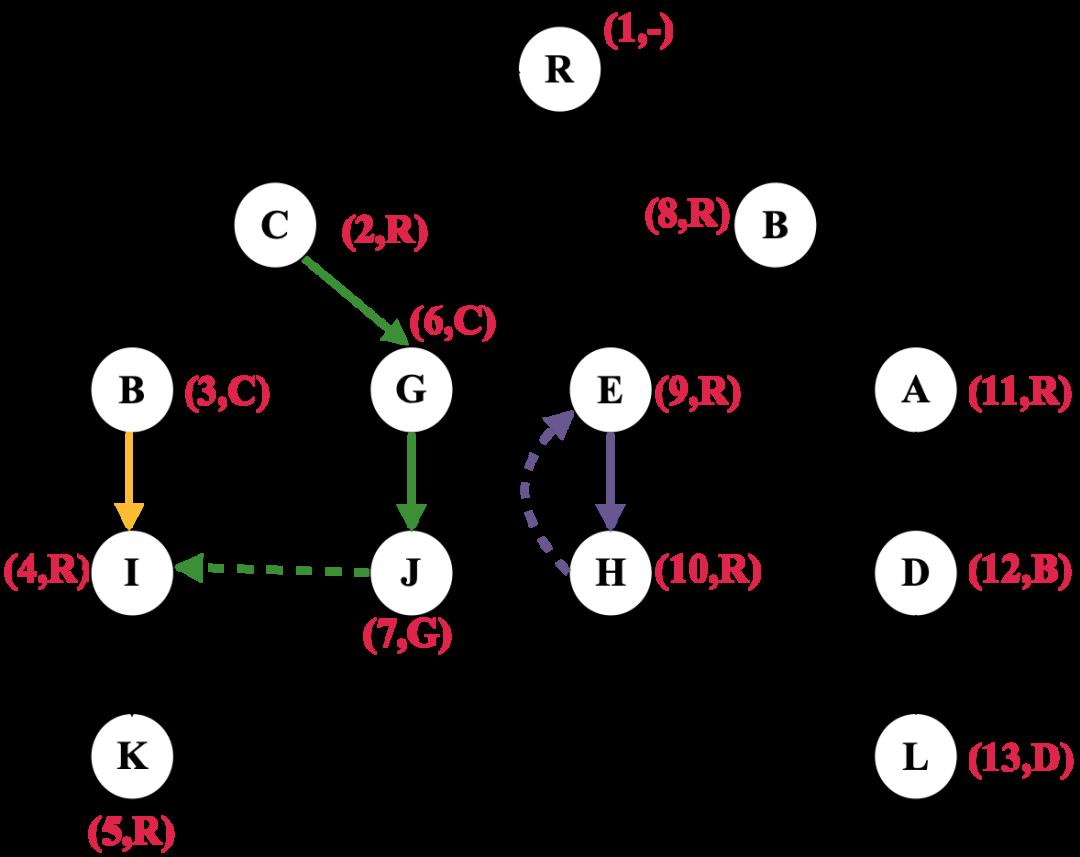
如图4所示,黄色加粗的线为树边半支配路径,绿色和紫色是非树边半支配路径,其中绿色边含有横跨边,紫色边含有返祖边。
4.2 半支配节点
公式表示:
通俗解释:
V的半支配节点为所有终点为V的半支配路径中,起点值最小的那个。
因为半支配路径有两类,一是树边半支配路径,二是非树边半支配路径,因此也可以将半支配节点的求法化简为这两类
公式化简:
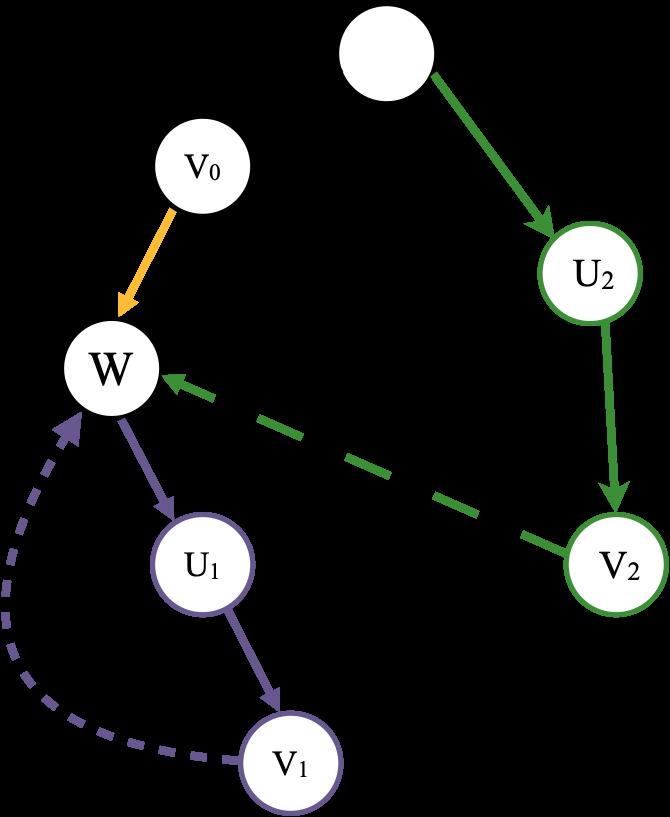
根据图形理解更加简单:
其中黄色线对应公式中的第(1)种情况
紫色线和绿色线对应公式中的第(2)种情况
其中的
可以取下图中
和
两种情况,
可以是绿色线或紫色线上的任意一个点,包括
或
。绿色线或紫色线就是公式中的条件
求半支配节点的伪代码
Create a DFS tree T.
semi(w) = w | w ∈ V
for w ∈ V − {r} in reverse preorder by the DFS
for v ∈ pred G (w)
u = eval(v)
if semi(u) < semi(w)
semi(w) = semi(u)
end for
Link parent(w) and w
end for
其中的 eval(v)就是在求黄色、紫色、绿色各条线上 semi 最小的点。因为是对 DFS 树进行逆序,因此求 的时候紫色线和绿色线上各节点的 semi 值已经是已知的了。
5. 支配节点与支配树
LLVM在2017年之前采用的是SLT算法,新的版本使用的是semi-NCA算法。两者都是在上一节介绍的半必经节点的基础上求得必经节点。下文会分别对这两种算法进行介绍,并比较其时间复杂度。
5.1 SLT 算法
SLT算法会根据前文求出的半支配节点进一步求出直接支配节点。
公式表示:
其中 在
通俗解释:
在DFS树中,
到
的路径上有一点
,
的sdom值是该路径上最小的点,如果
等于
则
等于
,否则等于
下面的两张图是对求 idom 的公式两种情况的一个总结,可以让我们的理解更加直观。
公式中的情况1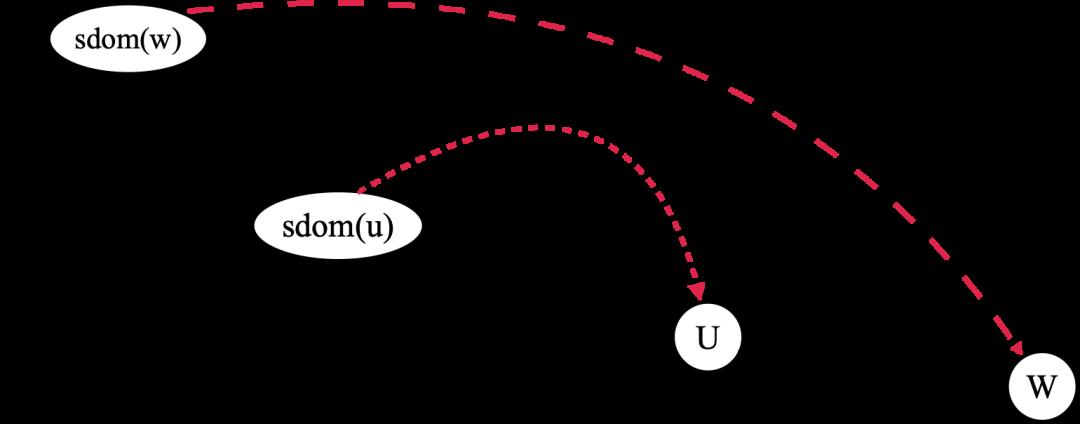 公式中的情况2
公式中的情况2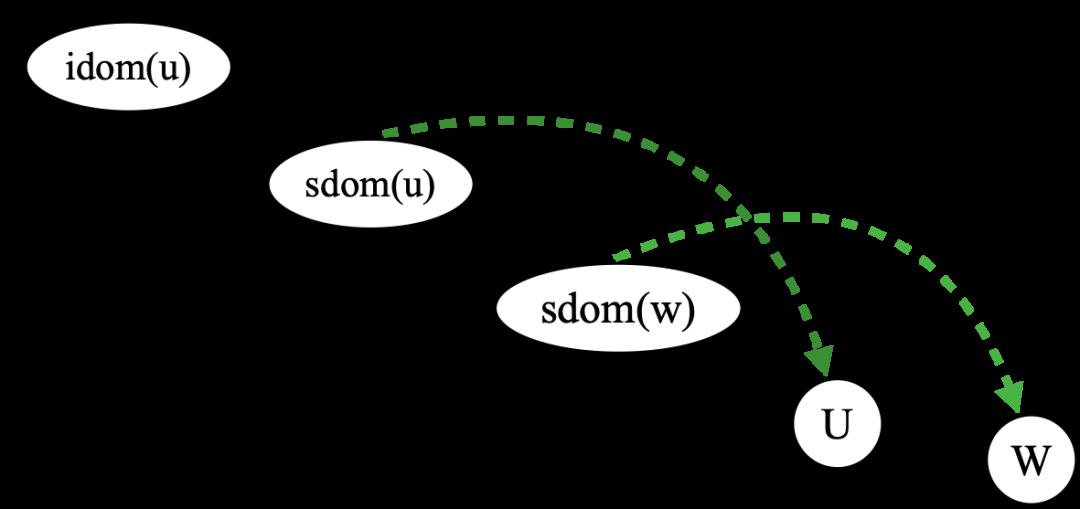
计算支配节点树的伪代码:
Create a DFS tree T.
for w ∈ V − {r} in reverse preorder by the DFS
Calculate semi dominator for w
Add w to bucket of semi(w)
while bucket of parent(w) is not empty do
v = pop one element from the bucket
u = eval(v)
if semi(u) < semi(v) then
idom(v) = u
else
idom(v) = semi(v)
end if
end while
end for
for w ∈ V − {r} in preorder by the DFS do
if idom(w) != semi(w) then
idom(w) = idom(idom(w))
end if
end for
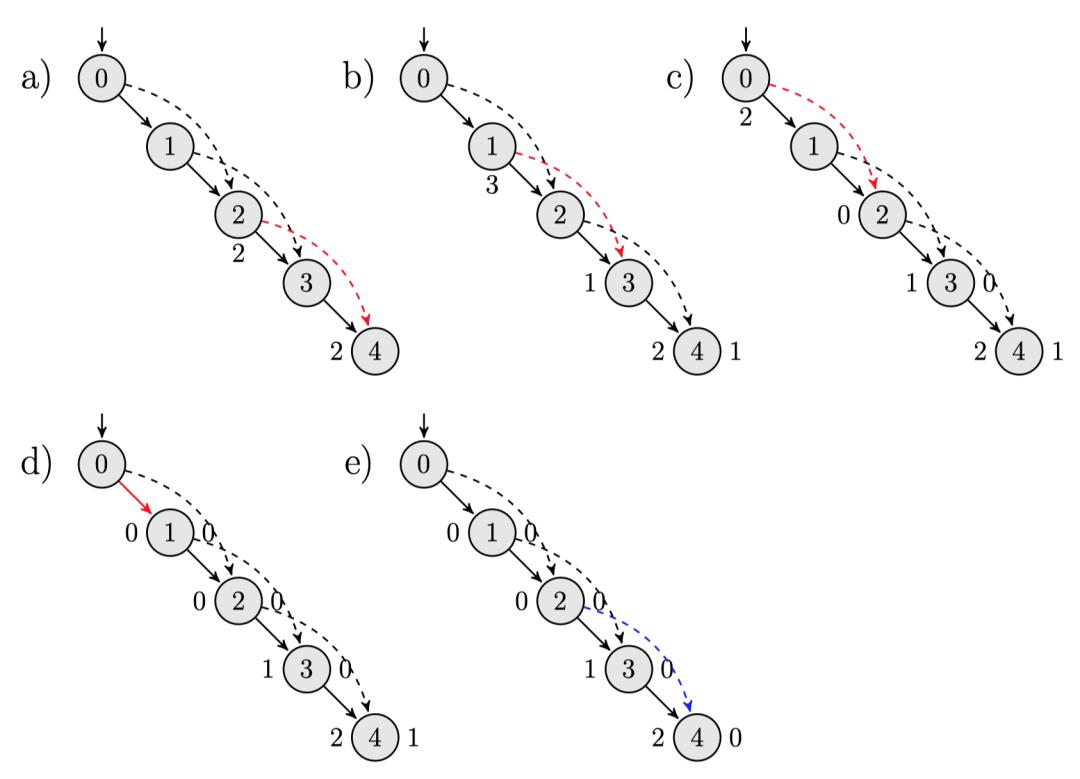
以一个实例加深对SLT算法的理解:
-
a)此时 semi(4)=2,因此 bucket(2)=4。 -
b)此时 semi(3)=1,因此 bucket(1)=3。此时 parent(3)=2,将 bucket(2)中的4弹出,2到4的路径上3的semi值最小,满足代码中的if 条件,因此idom(4)=3 -
c)此时semi(2)=0,因此bucket(0)=2。此时parent(2)=1,将bucket(1)中的3弹出,1到3的路径上2的semi值最小,满足代码中的if条件,因此idom(3)=2 -
d)此时semi(1)=0,因此 bucket(0)={2,1},此时 parent(1)=0,将 bucket(0)中的栈顶元素 1 弹出,满足 else 条件,idom(1)=0,继续将 bucket(0)中的2弹出,满足else条件,idom(2)=0 -
e)最后执行下一个循环,直接支配节点与半支配节点进行比较,此时 idom(3)不等于sdom(3),idom(4)不等于sdom(4),因此idom(3)=idom(2)=0,idom(4)=idom(idom(3))=0
5.2 semi-NCA 算法
与上文介绍的SLT算法相比,semi-NCA算法无疑更容易理解,这也是目前 LLVM正在使用的算法。下面直接上代码,相信大家一看就能够理解。
Create a DFS tree T.
Calculate semidominator for w
Create a tree D and initialize it with r as the root.
for v ∈ V − {r} in preorder by the DFS do
Ascend the path r *—>DparentT(v) and find the deepest vertex which number is smaller than or equal to sdom(v).
set this vertex as parent for v in D.
end for
为了方便理解,来看下面这个简单实例:
-
图 a)是已经求出的半支配节点图,左边的数字表示每个节点的半支配节点。 -
图 b)是支配节点树(代码中的 D 树),目前只求出来 0 到 4 节点的支配节点。 -
图 c)是求节点 5 支配节点的一个实例。节点 5 在 DFS 树中的父节点是 4。因此在 D 中沿着根节点 0 到 4 的路径上找到第一个小于 semi(5)的节点,此节点为 0,也就是 5 的直接支配节点。
小结
本节主要介绍了 LLVM 中求支配节点树的两种算法,分别是 SLT 和 semi-NCA 算法。两种算法的时间复杂度和空间复杂度如下。
| 算法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| SLT | O(mlogn) | O(m+n) |
| semi-NCA | O(n^2) | O(m+n) |
对于算法的详细分析、证明和实验结果可以参考原论文。
6. 后记
本篇文章缺少算法的证明,仅提供一些自己在学习过程中对这两个算法感性的认识,避免枯燥的公式。希望能够给需要学习这个算法的人提供一些帮助。
后续准备写一个编译器中的图论算法系列,题目如下:
-
编译器中的图论算法之支配树 -
编译器中的图论算法之支配边界
欢迎各位朋友帮忙补充更多的编译器中用到的图论算法或者其它感兴趣的编译器中的算法。
以上是关于编译器中的图论算法的主要内容,如果未能解决你的问题,请参考以下文章