带你简易入门一致性算法Raft
Posted 架构精进之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你简易入门一致性算法Raft相关的知识,希望对你有一定的参考价值。
当我们只有一个服务节点的情况下,是不存在节点共识的问题的,当存在多个不同服务节点时,才会引入分布式一致性的问题。
Raft是一种实现分布式共识的协议。所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。
主要应用场景:
Redis Sentinel的选举Leader
Etcd 主要是共享配置和服务发现,实现一致性使用了Raft算法
加密货币(比特币、区块链)的共识算法
主要解决什么问题?
分布式存储系统通常通过维护多个副本来提高系统的可用性,带来的代价就是分布式存储系统的核心问题之一:维护多个副本的数据一致性。
二、Raft算法实现流程
为了提高理解性,Raft将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety),并且使用了更强的一致性来减少了必须需要考虑的状态。
本文通过一个小故事做示例,来便于大家快速理解。
2.1 Leader选举
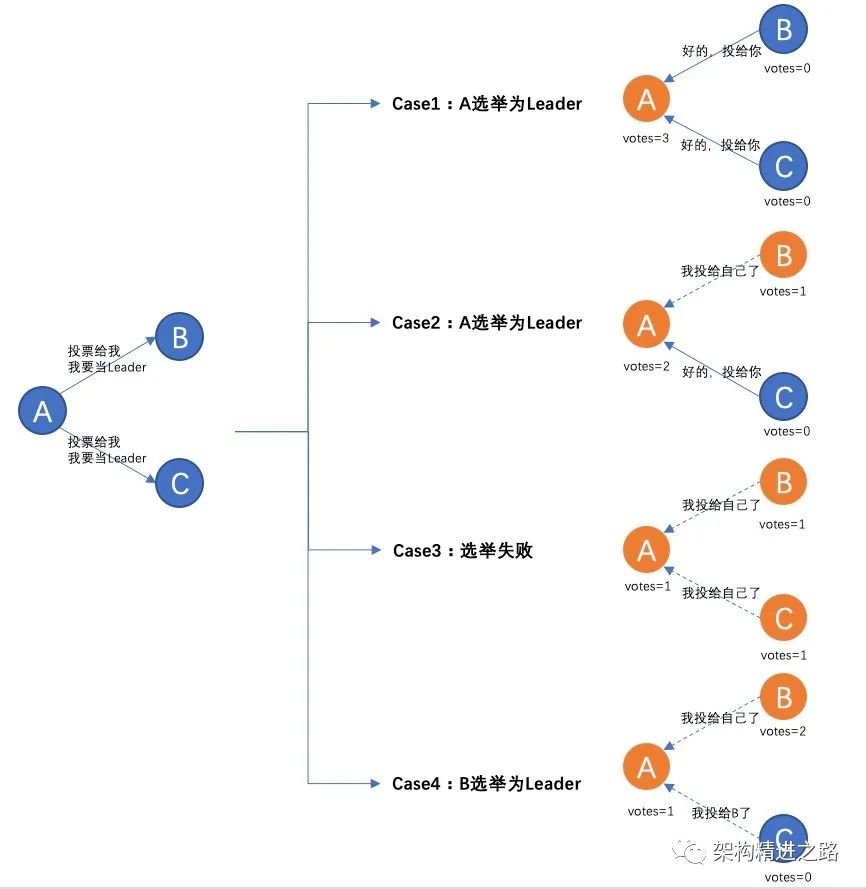
部门需要成立一个新的服务小组,现在有三名同学A,B,C。
为了便于后期统一调配资源及管理需要,现需要从三名同学中选举出一名小组Leader。
A觉得自己有能力做好Leader职务,就向B、C说“来投票给我,我想当Leader”,这时候A成了候选人,并为自己事先投了一票。
1)假如B、C之前都没有想过要自己当Leader,那就说“好吧,投给你” → A获得3张选票,当选Leader
2)假如B之前想过自己当Leader,B投了自己一票 而C投了一票给A → A获得2张选票(3人中已超过半数),当选Leader
3)假如B、C都已经把票投给了自己 → A、B、C各获得自己的一票,选举失败重新发起
4)假如B之前想过自己当Leader,而且C已经把票投给了B → B获得2张选票(3人中已超过半数),当选Leader
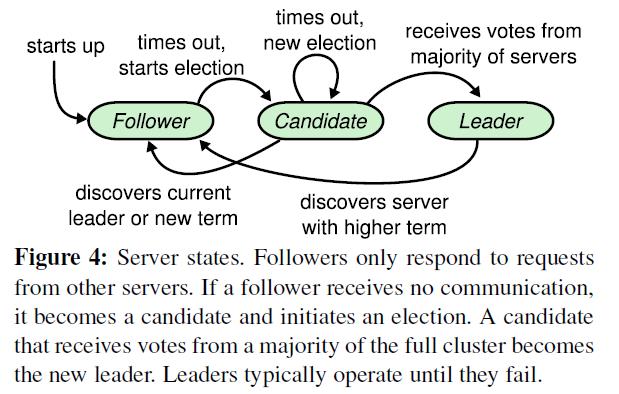
从以上选举流程可以发现,一个节点任一时刻肯定处于以下三状态之一:
Leader(领导者)
Follower(跟随者)
Candidate(候选人)
这三个状态的转移过程如下图所示:
选举过程
第一步:Follower成为Candidate
如果Follower听不到Leader的意见,他们就可以成为Candidate
第二步:候选人争取票
投自己一票,并发送投票请求到其他节点,节点收到请求后进行回应
第三步:等待其他节点回复
如果候选人得到了超半数的节点的投票(包含自己的一票),它就成为Leader
如果候选人被告知Leader已产生,则自行切换为Follower
一段时间内没有收到超半数投票,保持候选人状态,重新发起选举
第四步:候选人 赢得选举
新Leader会立刻给所有节点发消息,避免其他节点触发新的选举。
2.2 日志同步
在经过上述2.1 的Leader选举之后,已经选定了小组Leader,这里我们假定A已当选Leader。可以承担一些对接方同学(称为Client 端)提出的操作任务了。
规定每次需求对接,必须要经过小组Leader才可以。那员工提出操作请求,Leader接收到后记录下来,同时向组内其他同学进行同步,直到其他同学都确认了此需求后Leader才会确认操作并同步执行结果到员工(Follower节点)。
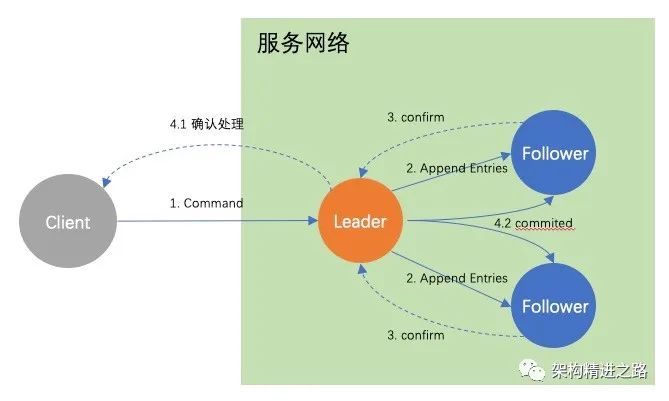
Log Replication(日志复制)
经过Leader选举流程,产生了新的Leader节点,系统的所有变更都要通过Leader节点来实现。
第一步:Leader追加日志项(append log entry)
系统的每个更改都作为一个entry 添加到节点的日志中
第二步:Leader并行发出Append Entries RPC,并等待响应
Leader会一直等到超半数节点都写入entry,Leader节点提交,然后Leader通知Follower entry已提交。
第三步:Leader得到大多数回应,向状态机应用entry
状态机:可理解为一个确定的应用程序,所谓确定是指只要是相同的输入,那么任何状态机都会计算出相同地输出。
第四步:Leader回复Client,同时通知Follower应用log
目前集群已就系统状态达成了共识
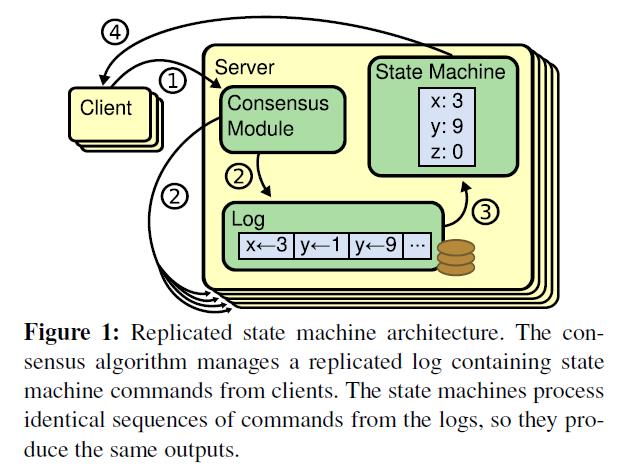
log-based replicated state machine示意图:
关于应用过程中的几个问题
Q1
假如Client 请求访问到了Follower节点怎么办?
解答:Follower节点会转发请求到Leader节点。
Q2
当Leader与Follower的日志不一致,需要如何处理?
解答:
1)Leader通过强制Followers复制它的日志来处理日志的不一致,Followers上的不一致的日志会被Leader的日志覆盖。
2)Leader为了使Followers的日志同自己的一致,Leader需要找到Followers同它的日志一致的地方,然后覆盖Followers在该位置之后的条目。
3)Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致位点,然后向后逐条覆盖Followers在该位置之后的条目。
2.3 安全性保障
为了保证团队运行的稳定,有几个默认的要求:
2.3.1 选举安全
即任一任期内最多一个leader被选出。假如系统中同时有多于一个leader,被称之为脑裂(brain split),这会导致数据的覆盖丢失。
一个团队某个时期内仅允许存在一个Leader(选举失败情况特殊情况除外),否则多个Leader同时处理需求发号施令,容易造成团队内步调不一致情况。
在raft中,两点保证了这个属性:
1)一个节点某一任期内最多只能投一票;
2)只有获得majority投票的节点才会成为leader。
2.3.2 Log 匹配完整性
同一团队内两名同学假如目前手头负责的事务是一致的,那之前他们的工作记录应该也是一致的。即:相同的初始状态+相同的操作=相同的结束状态
Leader将客户端请求封装到一个个的log entry,将这些log entries复制到其他Follower节点,大家按顺序应用这些请求,那最终状态肯定是一致的。
Raft日志同步结论:
1)如果不同日志中的两个条目有着相同的索引和任期号(term),则它们所存储的命令是相同的。
2)如果不同日志中的两个条目有着相同的索引和任期号(term),则它们之前的所有条目都是完全一样的。
2.3.3 leader数据完整性
团队内后继的leader,肯定应该知晓这个团队之前的工作内容,因为所有Leader任期内的工作记录是会做交接的。
如果一个log entry 在某个任期被提交,那么这条log一定会出现在所有更高term的leader的日志里面。
Raft日志覆盖规则:
1)一个日志被复制到majority节点才算committed
2)一个节点得到majority的投票才能成为leader,而节点A给节点B投票的其中一个前提是,B的日志不能比A的日志旧。
三、总结
所有的算法实现原理,其实都是真实社会工作模式的影射,联系生活中的实际案例来理解复杂的一致性算法,可以让我们达到事半功倍的效果。
本文旨在让大家对raft协议有一个简单了解入门,如有兴趣去更深入了解,推荐给大家两个不错的链接:
1)Raft可视化测试以及各语言版本实现的Raft:https://raft.github.io/
2)Raft算法-动画演示(很好的入门教程):http://thesecretlivesofdata.com/raft/
·················· END ··················
以上是关于带你简易入门一致性算法Raft的主要内容,如果未能解决你的问题,请参考以下文章