Mysql的索引为什么要使用B+树?
Posted 码虫甲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql的索引为什么要使用B+树?相关的知识,希望对你有一定的参考价值。
mysql的索引为什么要使用B+树,而不是B树,红黑树等之类?
在Mysql中,无论是Innodb还是MyISAM引擎,都使用了B+树做索引结构(这里先不考虑Hash索引)。那么我们从最普通的二叉树开始,来说明Mysql为什么选择B+树作为索引结构。
一、二叉查找树
二叉查找树(BST,binary search Tree)也叫二叉排序树,在二叉树的基础上满足:任意结点的左子树上的所有结点值不大于根节点的值,任意结点的右子树上所有结点值不小于根节点的值。
但如果采用二叉查找树作为索引,并且把id作为索引且id自增,那么二叉查找树就变成了一个单支树,相当于链表查询。即BST可能长歪而变得不平衡了
二、平衡二叉树
为了解决上述二叉搜索树的问题,引入了平衡得到二叉树。
AVL树是严格的平衡二叉树,所有节点的左右子树高度差不能超过1;AVL树查找、插入和删除在平均和最坏的情况下都是O(logn).
AVL实现平衡的关键在于旋转操作:插入和删除可能破坏二叉树的平衡,此时需要通过一次或多次树旋转来重新平衡这棵树。当插入数据时,最多只需要1次旋转(单旋转或双旋转);但是当删除数据时,会导致树失衡,AVL需要维护从被删除节点到根节点这条路径上所有节点的平衡,旋转的量级为O(lgn)。
但由于旋转的耗时,AVL树在删除数据时效率很低。在删除操作较多时,维护平衡所需的代码可能高于其带来的好处,因此AVL实际应用并不广泛。
三、红黑树
与AVL树相比,红黑树并不追求严格的平衡,而是大致的平衡:只是确保从根到叶子的最长的可能路径不多于 最短的可能路径的两倍长。实现上遵守以下规则:
节点是红色或黑色;
根节点是黑色;
所有叶子是黑色的;
每个红色节点必须有两个黑色的子节点(从每个叶子到根的所有路径上不能有两个连续的红色节点);
从任一节点到每个结点的所有简单路径都包含相同数目的黑色结点
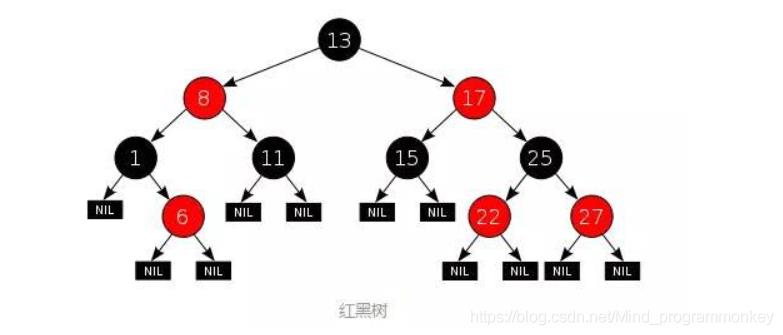
与AVL树相比 ,红黑树丶查询效率会有所下降,这是因为树的平衡性变差,高度更高了。但是红黑树的删除效率大大提高了。此外因为红黑树同时引入了颜色,当插入或删除数据时,只需要进行O(1)次数的旋转以及变色就能保证基本的平衡,不需要像AVL树进行O(logn)次数的旋转。
当然对于数据在内存中的情况如(TreeMap和HashMap),红黑树的表现是非常优异的。但是对于数据在磁盘等辅助存储设备中的情况(如Mysql等数据库),红黑树还是并不擅长,因为红黑树还是有点高。因为当数据在磁盘中,磁盘IO会成为最大的性能瓶颈,设计的目标应该是尽量减少IO次数;而树的高度越高,增删改查所需要的IO次数也越多,会严重影响性能。
四、B树
B树也被成为B-树,是为磁盘等辅存设备设计的多路平衡查找树,与二叉树相比,B树的每个非叶节点可以有多个子树。因此,当总节点数量相同时,B树的高度远远小于AVL树和红黑树,磁盘IO次数大大减少。
对于一棵m阶B树,需要满足以下条件:
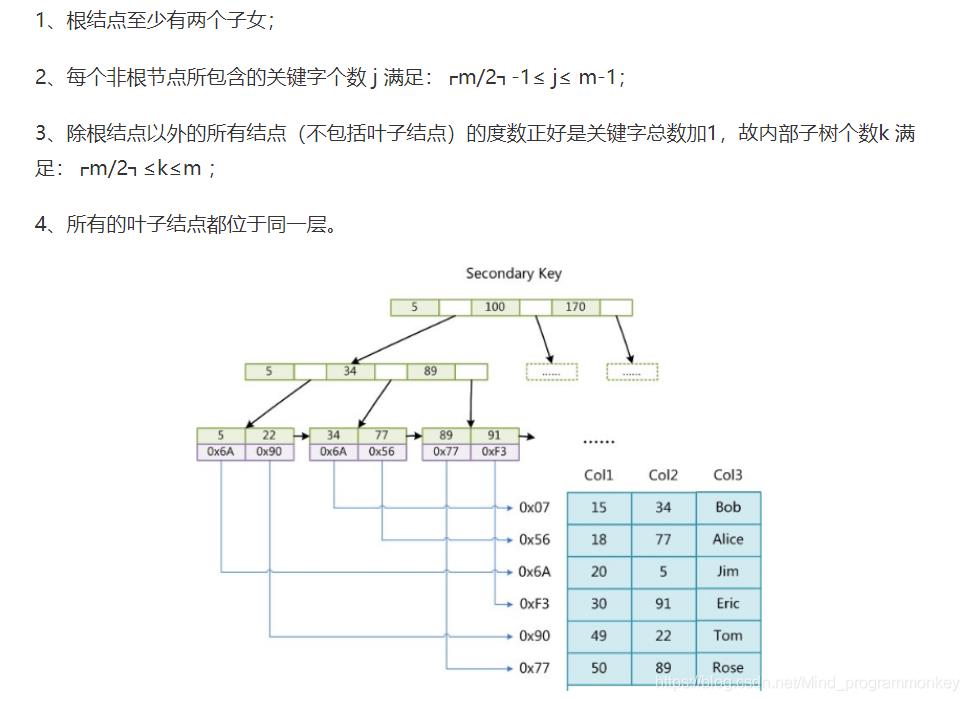
B树的优势除了树高小,还有对访问局部性原理的利用。所谓局部性原理,是指当一个数据被使用时,其附近的数据有较大概率在短时间内被使用。B树将键相近的数据存储在同一个节点,当访问其中某个数据时,数据库会将该整个节点读到缓存中;当它临近的数据紧接着被访问时,可以直接在缓存中读取,无需进行磁盘IO;换句话说,B树的缓存命中率更高。
五、B+树
B+树为B树的一种变形,m阶B+树有如下性质:
每个结点的关键字个数与孩子个数相等
除根节点之外,每个内部结点有m/2到m个孩子
B+树也是多路平衡查找树,其与B树的区别在于:
B+树的叶节点之间通过双向链表链接。
B树中的非叶节点,记录数比子节点个数少1;而B+树中记录数与子节点个数相同。
B树中一条记录只会出现一次,不会重复出现,而B+树的键则可能重复重现,一定会在叶节点出现,也可能在非叶节点重复出现。
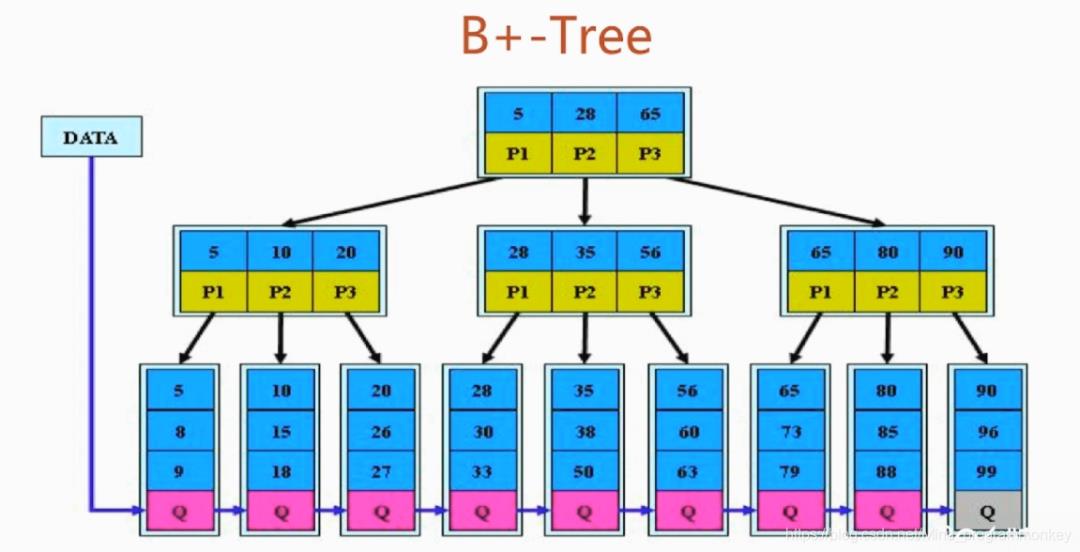
优势
更少的IO次数:B+树的非叶节点只包含键,而不包含真实数据,因此每个节点存储的记录个数比B数多很多(即阶m更大),因此B+树的高度更低,访问时所需要的IO次数更少。此外,由于每个节点存储的记录数更多,所以对访问局部性原理的利用更好,缓存命中率更高。
更适于范围查询:在B树中进行范围查询时,首先找到要查找的下限,然后对B树进行中序遍历,直到找到查找的上限;而B+树的范围查询,只需要对链表进行遍历即可。
更稳定的查询效率:B树的查询时间复杂度在1到树高之间(分别对应记录在根节点和叶节点),而B+树的查询复杂度则稳定为树高,因为所有数据都在叶节点。
总结
二叉查找树(BST):解决了排序的基本问题,但是由于无法保证平衡,可能退化为链表;
平衡二叉树(AVL):通过旋转解决了平衡的问题,但是旋转操作效率太低;
红黑树:通过舍弃严格的平衡和引入红黑节点,解决了AVL旋转效率过低的问题,但是在磁盘等场景下,树仍然太高,IO次数太多;
B树:通过将二叉树改为多路平衡查找树,解决了树过高的问题;
红黑节点,解决了AVL旋转效率过低的问题,但是在磁盘等场景下,树仍然太高,IO次数太多;
B树:通过将二叉树改为多路平衡查找树,解决了树过高的问题;
B+树:在B树的基础上,将非叶节点改造为不存储数据的纯索引节点,进一步降低了树的高度;此外将叶节点使用指针连接成链表,范围查询更加高效。
以上是关于Mysql的索引为什么要使用B+树?的主要内容,如果未能解决你的问题,请参考以下文章