探究 Java 应用的启动速度优化
Posted 阿里技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探究 Java 应用的启动速度优化相关的知识,希望对你有一定的参考价值。
一 高性能和快启动速度,能否鱼和熊掌兼得?
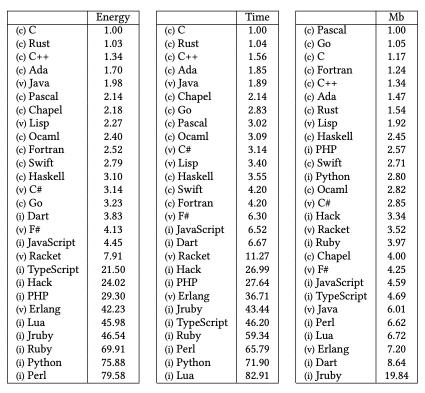
-
著名的V8(javascript引擎)的 TurboFan 编译器使用了相同的设计,只是用更加现代的方式去实现;
-
Hotspot 使用 Graal JVMCI 做 JIT 时,性能基本与 C2 持平;
-
Azul 的商业化产品将 Hotspot 中的 C2 compiler 替换成 LLVM,峰值性能和 C2 也是持平。
二 Java 启动慢的根因
1 框架复杂
-
在每一层都提供选项,Spring 可以让你尽可能的推迟选择。
-
适应不同的视角,Spring 具有灵活性,它不会强制为你决定该怎么选择。它以不同的视角支持广泛的应用需求。
-
保持强大的向后兼容性。
$ java -verbose:class -jar myapp-1.0-SNAPSHOT.jar | grep spring | head -n 5[Loaded org.springframework.boot.loader.Launcher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar][Loaded org.springframework.boot.loader.ExecutableArchiveLauncher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar][Loaded org.springframework.boot.loader.JarLauncher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar][Loaded org.springframework.boot.loader.archive.Archive from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar][Loaded org.springframework.boot.loader.LaunchedURLClassLoader from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]$ java -verbose:class -jar myapp-1.0-SNAPSHOT.jar | egrep '^\[Loaded' > classes$ wc classes7404 29638 1175552 classes
const express = require('express')const app = express()app.get('/', (req, res) => {res.send('Hello World!')})app.listen(3000, () => {console.log(`Example app listening at http://localhost:${port}`)})
NODE_DEBUG=module node app.js 2>&1 | head -n 5MODULE 18614: looking for "/Users/yulei/tmp/myapp/app.js" in ["/Users/yulei/.node_modules","/Users/yulei/.node_libraries","/usr/local/Cellar/node/14.4.0/lib/node"]MODULE 18614: load "/Users/yulei/tmp/myapp/app.js" for module "."MODULE 18614: Module._load REQUEST express parent: .MODULE 18614: looking for "express" in ["/Users/yulei/tmp/myapp/node_modules","/Users/yulei/tmp/node_modules","/Users/yulei/node_modules","/Users/node_modules","/node_modules","/Users/yulei/.node_modules","/Users/yulei/.node_libraries","/usr/local/Cellar/node/14.4.0/lib/node"]MODULE 18614: load "/Users/yulei/tmp/myapp/node_modules/express/index.js" for module "/Users/yulei/tmp/myapp/node_modules/express/index.js"$ NODE_DEBUG=module node app.js 2>&1 | grep ': load "' > js$ wc js55 392 8192 js
2 一次编译,到处运行
-
Class Loading
$ jar tf slf4j-api-1.7.25.jar | headMETA-INF/META-INF/MANIFEST.MForg/slf4j/org/slf4j/event/EventConstants.classorg/slf4j/event/EventRecodingLogger.classorg/slf4j/event/Level.class
for (int i = 0; (loader = getNextLoader(cache, i)) != null; i++) {Resource res = loader.getResource(name, check);if (res != null) {return res;}}
$ javap -p SimpleMessage.classpublic class org.apache.logging.log4j.message.SimpleMessage implements org.apache.logging.log4j.message.Message,org.apache.logging.log4j.util.StringBuilderFormattable,java.lang.CharSequence {private static final long serialVersionUID;private java.lang.String message;private transient java.lang.CharSequence charSequence;public org.apache.logging.log4j.message.SimpleMessage();public org.apache.logging.log4j.message.SimpleMessage(java.lang.String);
public class A {private final static String JAVA_VERSION_STRING = System.getProperty("java.version");private final static Set<Integer> idBlackList = new HashSet<>();static {idBlackList.add(10);idBlackList.add(65538);}}
-
只执行一次;
-
有多线程尝试访问类时,只有一个线程会执行类初始化,JVM 保证其他线程都会阻塞等待初始化完成。
-
Just In Time compile
while (true) {switch(bytocode[pc]) {case AALOAD:...break;case ATHROW:...break;}}
$ java -jar benchmarks.jar hessianIOBenchmark Mode Cnt Score Error UnitsSerializeBenchmark.hessianIO thrpt 118194.452 ops/s$ java -Xint -jar benchmarks.jar hessianIOBenchmark Mode Cnt Score Error UnitsSerializeBenchmark.hessianIO thrpt 4535.820 ops/s
java -XX:+PrintFlagsFinal -version | grep CompileThresholdintx Tier3CompileThreshold = 2000 {product}intx Tier4CompileThreshold = 15000 {product}
三 如何优化 Java 应用的启动速度
-
受到 JakartaEE 影响,常见框架考虑复用和灵活性,设计得比较复杂;
-
为了跨平台性,代码是动态加载,并且动态编译的,启动阶段加载和执行耗时;
-
Class Loading
-
通过 JarIndex 解决 JAR 包遍历问题,不过该技术过于古老,很难在现代的囊括了tomcat、fatJar的项目里使用起来
-
AppCDS 可以解决 class 文件解析处理的性能问题
-
Class Initialize: OpenJDK9 加入了 HeapArchive,可以持久化一部分类初始化相关的 Heap 数据,不过只有寥寥数个 JDK 内部 class (比如 IntegerCache )可以被加速,没有开放的使用方式。
-
JIT预热: JEP295 实现了 AOT 编译,但是存在 bug,使用不当会引发程序正确性能问题。在性能上没有得到很好的 tuning,大部分情况下看不到效果,甚至会出现性能回退。
1 AppCDS
+-------------+
| mark |
+-------------+
| Klass* |
+-------------+
| fields |
| |
+-------------+
// InstanceKlass layout:// [C++ vtbl pointer ] Klass// [java mirror ] Klass// [super ] Klass// [access_flags ] Klass// [name ] Klass// [methods ]// [fields ]...
Object:+-------------+| mark | +-------------------------++-------------+ |classes.jsa file || Klass* +--------->java_mirror|super|methods|+-------------+ |java_mirror|super|methods|| fields | |java_mirror|super|methods|| | +-------------------------++-------------+
AppCDS 对 customer class loader 力不从心
-
调用用户定义的 Classloader.loadClass() ,拿到class byte stream
-
计算class byte stream的checksum,与jsa中的同类名结构的checksum比较
-
如果匹配成功则返回jsa中的 InstanceKlass ,否则继续使用slow path解析class文件
bar.jar+- com/bar/Bar.classbaz.jar+- com/baz/Baz.classfoo.jar+- com/foo/Foo.class
JAR Index
JarIndex-Version: 1.0foo.jarcom/foobar.jarcom/barbaz.jarcom/baz
com/bar --> bar.jarcom/baz --> baz.jarcom/foo --> foo.jar
-
jar i 根据 META-INF/MANIFEST.MF 中的 Class-Path 属性产生索引文件,现代项目几乎不维护这个属性
-
只有 URLClassloader 支持JAR Index
-
要求带索引的jar尽量出现在 classpath 的前面
2 类提前初始化
class IntegerCache {
static final Integer cache[];
static {
Integer[] c = new Integer[size];
int j = low;
for(int k = 0; k < c.length; k++)
c[k] = new Integer(j++);
cache = c;
}
}
int fd = open("archive_file", O_READ);
struct person *persons = mmap(NULL, 100 * sizeof(struct person),
PROT_READ, fd, 0);
int age = persons[5].age;
Heap Archive简介
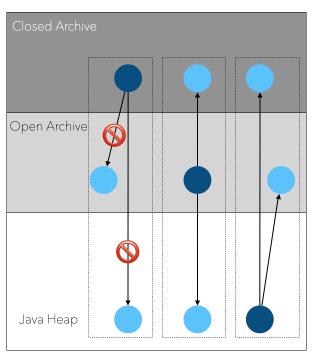
-
Closed Archive
-
不允许引用Open Archive 和Heap中的对象 -
可以引用Closed Archive内部的对象 -
只读,不可写
-
Open Archive
可以引用任何对象
可写
为什么只读?想象一下,假如Closed Archive中的对象A引用了heap中的对象B,那么当对象B移动时,GC需要修正A中指向B的field,这会带来GC开销。
利用 Heap Archive 提前做类初始化
class Foo {static Object data;} +|<---------+Open Archive Object:+-------------+| mark | +-------------------------++-------------+ |classes.jsa file || Klass* +--------->java_mirror|super|methods|+-------------+ |java_mirror|super|methods|| fields | |java_mirror|super|methods|| | +-------------------------++-------------+
3 AOT编译
注意这里的术语使用:
JEP295使用AOT是将class文件中的方法逐个编译到native代码片段,通过Java虚拟机在加载某个类后替换方法的的入口到AOT代码。
而GraalVM的的Native Image功能是更加彻底的静态编译,通过一个用Java代码编写的小型运行时SubstrateVM,该运行时和应用代码一起被静态编译到可执行的文件(类似Go),不再依赖JVM。该做法也是一种AOT,但是为了区分术语,这里的AOT单指JEP295的方式。
AOT特性初体验
cat > HelloWorld.java <<EOFpublic class HelloWorld {public static void main(String[] args) { System.out.println("Hello World!"); }}EOFjaotc --output libHelloWorld.so HelloWorld.classjava -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=./libHelloWorld.so HelloWorld
1)AOT 的一波三折
2)多 Classloader 问题
ClassLoaderData* cld = ik->class_loader_data();if (!cld->is_builtin_class_loader_data()) {log_trace(aot, class, load)("skip class %s for custom classloader %s (%p) tid=" INTPTR_FORMAT,ik->internal_name(), cld->loader_name(), cld, p2i(thread));return false;}
3)缺乏调优和维护,退回成实验特性
JEP 295 AOT is still experimental, and while it can be useful for startup/warmup when used with custom generated archives tailored for the application, experimental data suggests that generating shared libraries at a module level has overall negative impact to startup, dubious efficacy for warmup and severe static footprint implications.
java -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=...-
Java 语言本身过分复杂,动态类加载等运行时机制导致 AOT 代码没法运行得像预期一样快
-
AOT 技术作为阶段性的项目在进入 Java 9 之后并没有被长期维护,缺乏必要的调优(反观AppCDS一直在迭代优化)
4)JDK16 中被删除
We haven't seen much use of these features, and the effort required to support and enhance them is significant.
-
在 OpenJDK 的 C2 基础上做 AOT
-
在 GraalVM 的 native-image 上支持完整的 Java 语言特性,需要 AOT 的用户逐渐从 OpenJDK 过渡到native-image
5)Dragonwell 上的快速启动
四 SAE x Dragonwell : Serverless with Java 启动加速最佳实践
SAE (Serverless 应用引擎)是首款面向 Serverless 的 PaaS 平台,他可以:
Java 软件包部署:零代码改造享受微服务能力,降低研发成本
Serverless 极致弹性:资源免运维,快速扩容应用实例, 降低运维与学习成本
-
软件包大:几百 MB 甚至 GB 级别
-
依赖包多:上百个依赖包,几千个 Class
-
加载耗时:从磁盘加载依赖包,再到 Class 按需加载,最高可占启动耗时的一半
-
Java 环境 + JAR/WAR 软件包部署:集成 Dragonwell 11 ,提供加速启动环境
-
JVM 快捷设置:支持一键开启快速启动,简化操作
-
NAS 网盘:支持跨实例加速,在新包部署时,加速新启动实例/分批发布启动速度
2 加速效果
-
类加载多(spring-petclinic 启动加载约 12000+ classes)
-
依赖外部数据越少
3 客户案例
阿里巴巴搜索推荐 Serverless 平台
潮牌秒杀SAE极致弹性
五 总结
重磅首发 | 承载亿级流量的开发框架,闲鱼Flutter技术解析与实战大公开
以上是关于探究 Java 应用的启动速度优化的主要内容,如果未能解决你的问题,请参考以下文章