HDFS——写文件中的异常处理
Posted hncscwc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS——写文件中的异常处理相关的知识,希望对你有一定的参考价值。
记得看过一本书,里面是这么写的,软件开发中的二八原则,80%的时间运行的是正常流程,20%的时间是异常流程。而实际代码中,80%的代码是在处理异常逻辑,而正常流程只占20%。
由此可见,异常处理是很重要的一块内容。
本文就以原生的JAVA客户端为例,聊聊HDFS里写文件过程中的异常处理。
先来简单回顾下HDFS的写文件流程,如下图所示:
客户端向NN申请block,NN处理请求后需要将操作写入JN中。随后,客户端向DN建立连接发送数据,最后向NN同步block的信息。详细流程戳。
整个流程中,JN、NN、不同的DN出现异常,均可能导致写异常或失败。
【JN异常】
假如在客户端addBlock之前,JN就出现了异常,那么addBlock会失败,因此block会写失败。
而假如在客户端成功addBlock后,JN出现了异常,例如停止所有的JN,会怎样呢?
实测发现,首先两个NN均未重启,但都停止提供服务,其用于rpc通信的端口也没有处于监听状态。其次,客户端一开始并没有报错,还在持续的向dn写入数据,从DN节点的rbw目录中,可以观察到block文件大小在持续递增,也就是说文件在不断的写入。
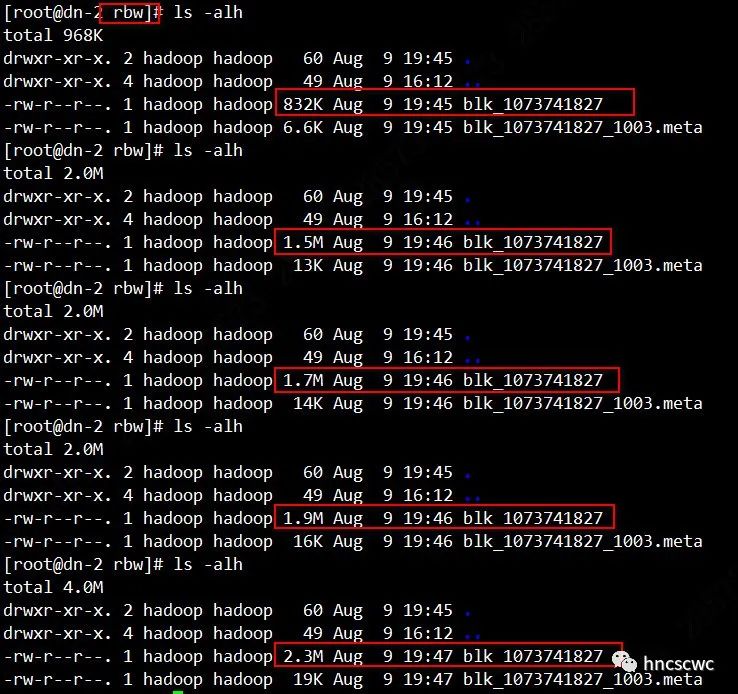
但再次申请block时,出现无法连接NN的异常报错,因此无法继续写入新的block。
另外需要注意的是:该测试中,写动作恰好在客户端续租约的周期内完成的,因此一个block能完整写完。

但是,如果写过程中遇到了自动续租约的流程,由于NN已经不再提供服务,因此客户端续约会失败,而失败后的处理逻辑就是停止写文件。
在此之后,重新启动JN,NN恢复正常,通过命令下载文件,文件的大小、内容与已写入的完全一致。

结论:只要租约未到期,客户端就可以持续写入直到写完当前block,再次申请新的block时会报错,而已经写入的内容等JN恢复后,可以准确读取出来。
【NN异常】
由于NN有HA机制,当Active NN出现异常后,standby的NN会自动提升为新的Active接管提供服务,因此只要不是两个NN同时出现异常,就都可以正常读写。
如果两个NN均出现了问题,那么情况就和上面的JN异常一样了(JN都异常了,NN不提供服务)。
【DN异常】
首先,客户端分两种情况感知DN的异常。这个异常包括DN进程异常,DN所在节点网络异常,或者DN节点存储数据的磁盘异常。
一种是直接与客户端连接的DN异常,客户端通过socket的读写失败,从而感知到该DN的异常。
另一种是非直接与客户端连接的DN异常,与客户端直接连接的DN在给客户端的ack包中会携带异常DN的序号,客户端在处理ack包的时候就能感知哪个DN异常了。
尽管感知DN异常的方式不一样,但异常的处理逻辑都是一样的。
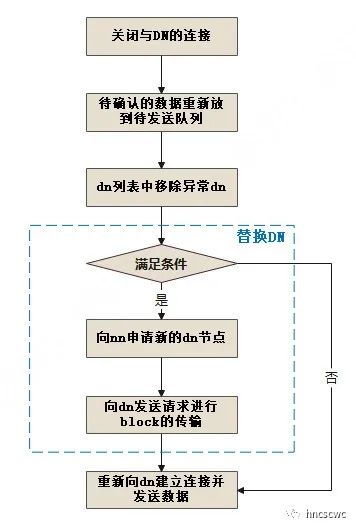
如上图所示,异常处理的流程为:
首先客户端会关闭当前与DN的连接。
接着将待确认的数据重新放回到待发送列表中。
接着从DN列表中移除异常DN。
然后进行替换DN的处理
具体包括先判断是否满足替换DN的条件,如果满足条件,则向NN请求增加一个DN,NN分配一个合适的DN并返回给客户端,客户端将新的DN放到DN列表末尾,并以当前DN列表中的第一个DN为源,向其他DN进行block数据的同步,也就是保证传输之前的数据一致性。
最后向DN列表中的首个DN发起连接重新进行数据传输的动作。
上面所说的替换DN需要判断是否满足条件,具体来说,受下面几个配置项的影响。
dfs.client.block.write.replace-datanode-on-failure.enable
是否启用替换DN的处理机制,默认值为true,也就是启用DN替换机制。
如果是false,当DN异常后,客户端移除异常的DN后使用剩余的DN继续进行写操作。
dfs.client.block.write.replace-datanode-on-failure.policy
替换DN的具体策略,仅当启动替换DN时该配置项才生效。可选的策略包括:
ALWAYS:始终执行替换DN的动作。
NEVER:始终不进行替换DN的动作。
DEFAULT:默认策略,(1)移除异常后的DN列表个数大于block副本数除2(即副本数中还有多数的节点是非异常的),(2)如果是append或hflushed添加的block,并且副本数大于DN列表数。
当副本数大于3并且满足上述任意条件时,执行替换DN的处理。
dfs.client.block.write.replace-datanode-on-failure.replication
允许的最小失败次数,如果配置为0,那么如果找不到可替换的DN时,会抛出异常。
另外还有一个细节,前面提到了替换DN后,选择一个DN作为源,向其他DN同步源DN上已经存储的block数据,接着客户端再重新进行数据传输。
那么,可能会出现这么一种情况。
例如:客户端发送序号为3的packet时,DN1出现了异常,此时客户端还未收到序号为3的packet的ack,因此放入待发送队列中,等完成DN替换后,继续进行发送,而DN2中实际已经将序号为3的已经写入的本地,那么再次收到客户端发送的序号为3的packet是否会有问题呢?
对于这个问题,DN2收到packet后,执行同样的逻辑流程,先继续向后面的DN进行转发,但是在真正写入时,判断本地文件中的block数据的偏移位置是否大于发送过来的packet数据在block中的偏移位置,如果本地的偏移位置更大,意味着该packet数据实际已经接收过了,实际处理时就不再进行本地的写入动作。
【总结】
本文总结了写过程中,不同服务模块出现异常的后的现象与处理机制。实际上,不同的客户端实现有不同的逻辑,例如看过的一个golang客户端实现就没有DN异常后替换DN的逻辑处理,
好了,本文就介绍到这里了,原创不易,点赞,在看,分享是最好的支持, 谢谢~
以上是关于HDFS——写文件中的异常处理的主要内容,如果未能解决你的问题,请参考以下文章