归并排序过程详解
Posted Python开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归并排序过程详解相关的知识,希望对你有一定的参考价值。
作者丨alg-flody
https://blog.csdn.net/daigualu/article/details/78399168
 归并简介
归并简介
归并排序,英文名称是MERGE-SORT。
它是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
算法的核心概念—二路归并
若将两个有序表合并成一个有序表,称为二路归并。
二路归并
比较 a[i] 和 b[j] 的大小,若 a[i]≤b[j],则将第一个有序表中的元素a[i]复制到 r[k] 中,并令i 和 k 分别加上1;否则将第二个有序表中的元素b[j]复制到r[k] 中,并令 j 和 k 分别加上1;如此循环下去,直到其中一个有序表取完;然后再将另一个有序表中剩余的元素复制到 r 中从下标 k 到下标t的单元。这个过程,请见下面的例子演示。
二路归并演示
如下图所示,初始状态时,a序列[2,3,5]和b序列[2,9]为已排序好的子序列,现在利用二路归并,将a和b合并为有序序列 r,初始时,i指向a的第一个元素,j指向b的第一个元素,k初始值等于0。说明,r中最后一个元素起到哨兵的作用,灰色显示。
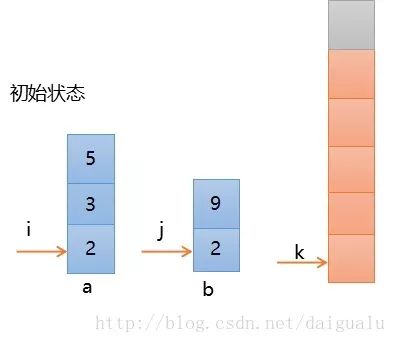
第一步,比较a[i]和b[j],发现相等,如果规定相等时,a的先进入r,则如下图所示,i, k分别加1,为了形象化,归并后的元素不再绘制。
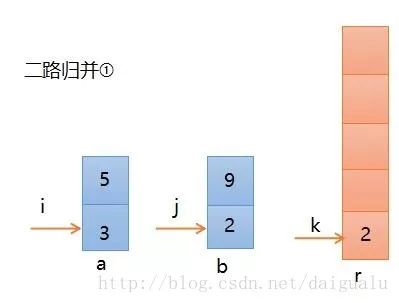
第二步,继续比较,此时b[j]小,所以b的元素2进入r,则如下图所示,j, k分别加1,
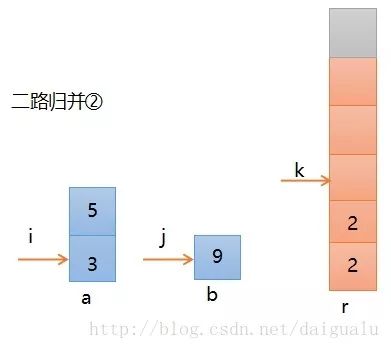
第三步,继续比较,此时a[i]小,所以a的元素3进入r,则如下图所示,i, k分别加1,
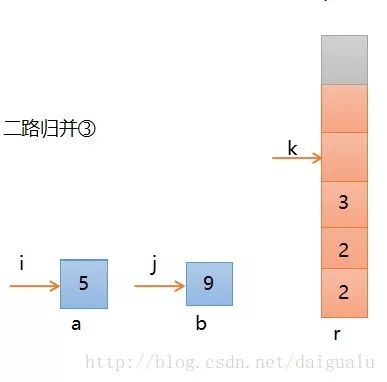
第四步,继续比较,此时a[i]小,所以a的元素5进入r,则如下图所示,i, k分别加1,此时序列a的3个元素已经归并完,b中还剩下一个,这个可以通过k可以看出,它还没有到达个数5。
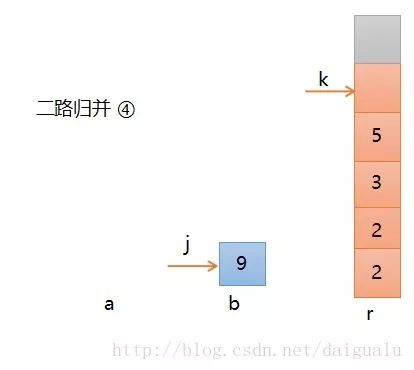
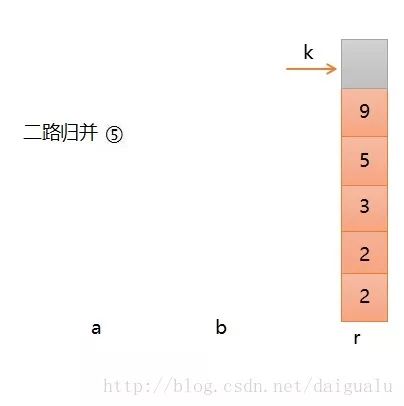
第五步,将序列b中的所有剩余元素直接放入r中即可,不用做任何比较了,直至b变空,二路归并结束。
总体思路
归并排序的算法我们通常用递归实现。
先把待排序区间 [s,t] 以中点二分;
接着把左边子区间排序;
再把右边子区间排序;
最后把左区间和右区间用一次归并操作合并成有序的区间 [s,t] 。
过程模拟
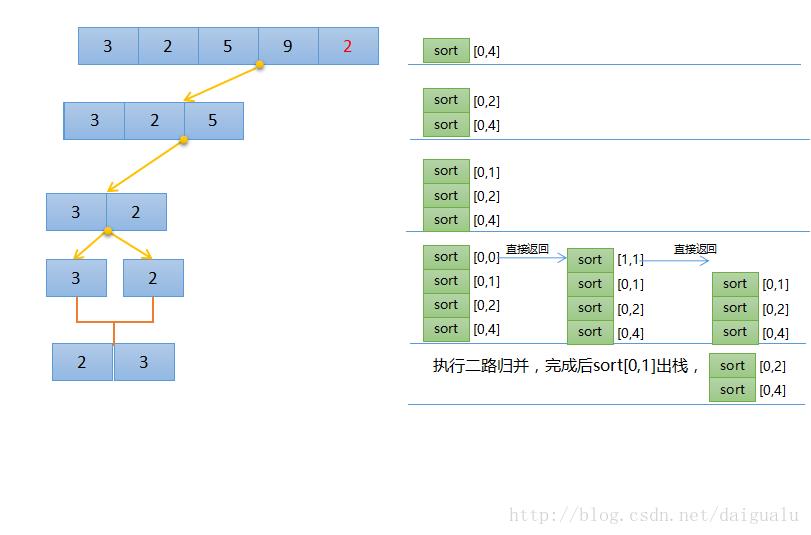
下图演示的是归并排序递归版,第一次执行二路归并时的示意图,注意观察右图的栈的入栈顺序,可以看到sort的入栈顺序,当执行一次merge时,一定是有2个sort返回并有序了,如下图,sort[0,0]和sort[1,1](递归返回的条件是start小于end)都返回了,然后执行到merge,执行完merge后,sort[0,1]出栈,此时的栈顶为sort[0,2]函数,可以看出它的前半部分已经计算完,只需要计算后半部分,即第二个sort,然后再次merge,再sort[0,2]出栈。
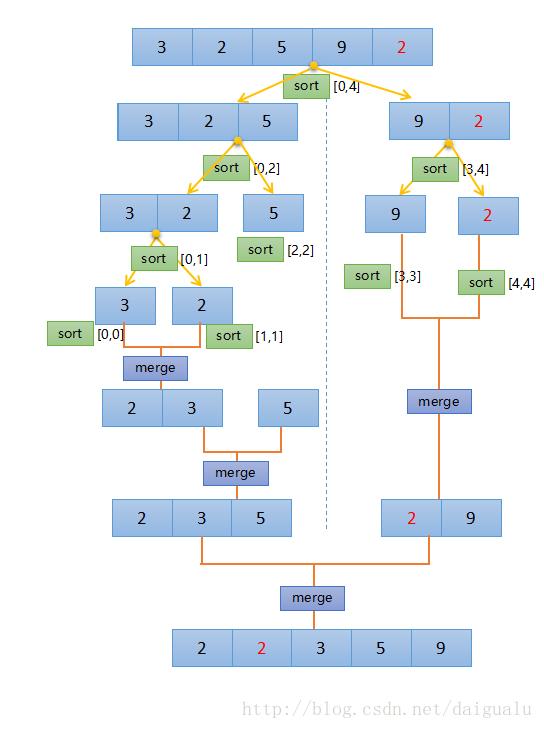
如下为上个例子的归并排序的完整示例,sort 和 merge 的示意图,可以看到最后一次merge,正是上面说到的二路 [2,3,5] 和 [2,9] 的归并排序,如果不熟的,可以回过头再看看。
算法评价
归并排序的时间复杂度为O(nlogn) ,因为递归每次按照一半分区,并且merge需要线性时间。最重要的是该算法中最好、最坏和平均的时间性能都是O(nlogn)。
归并排序的空间复杂度为O(n),会占用内存。
总之,归并排序虽然比较占用内存,但却是一种效率高且稳定的算法。
总结
归并排序的时间复杂度,在最坏,最好和平均都是O(nlogn),这是效率,性能非常好的排序算法。
只不过它需要占用 O(n)的内存空间,如果数据量一旦很大,内存可能吃不消,这是它的弱点和致命伤。而其他排序算法,比如快速排序,希尔排序,都是就地排序算法,它们不占用额外的内存空间。
python完整实现
def merge_sort( li ):
#不断递归调用自己一直到拆分成成单个元素的时候就返回这个元素,不再拆分了
if len(li) == 1:
return li
#取拆分的中间位置
mid = len(li) // 2
#拆分过后左右两侧子串
left = li[:mid]
right = li[mid:]
#对拆分过后的左右再拆分 一直到只有一个元素为止
#最后一次递归时候ll和lr都会接到一个元素的列表
# 最后一次递归之前的ll和rl会接收到排好序的子序列
ll = merge_sort( left )
rl =merge_sort( right )
# 我们对返回的两个拆分结果进行排序后合并再返回正确顺序的子列表
# 这里我们调用拎一个函数帮助我们按顺序合并ll和lr
return merge(ll , rl)
#这里接收两个列表
def merge( left , right ):
# 从两个有顺序的列表里边依次取数据比较后放入result
# 每次我们分别拿出两个列表中最小的数比较,把较小的放入result
result = []
while len(left)>0 and len(right)>0 :
#为了保持稳定性,当遇到相等的时候优先把左侧的数放进结果列表,因为left本来也是大数列中比较靠左的
if left[0] <= right[0]:
result.append( left.pop(0) )
else:
result.append( right.pop(0) )
#while循环出来之后 说明其中一个数组没有数据了,我们把另一个数组添加到结果数组后面
result += left
result += right
return result
if __name__ == '__main__':
li = [5,4 ,3 ,2 ,1]
li2 = merge_sort(li)
print(li2)
推荐↓↓↓
长
按
关
注
以上是关于归并排序过程详解的主要内容,如果未能解决你的问题,请参考以下文章