python 爬虫学习练习爬取电影小说
Posted ruichow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫学习练习爬取电影小说相关的知识,希望对你有一定的参考价值。
没事百度了很多爬虫内容,主要是为了学习关于爬虫基础知识。因此借鉴参考了不少的内容,由于并不熟悉pyquery的爬虫框架,只能不断的尝试去研究一番才行。对于小白,定位信息的难度看的有些懵,只能去不断试验和尝试。
1、用百度来练习一下,熟悉一下爬虫框架pyquery使用方法
首页a标签的内容,可以通过浏览器去获取css定位信息
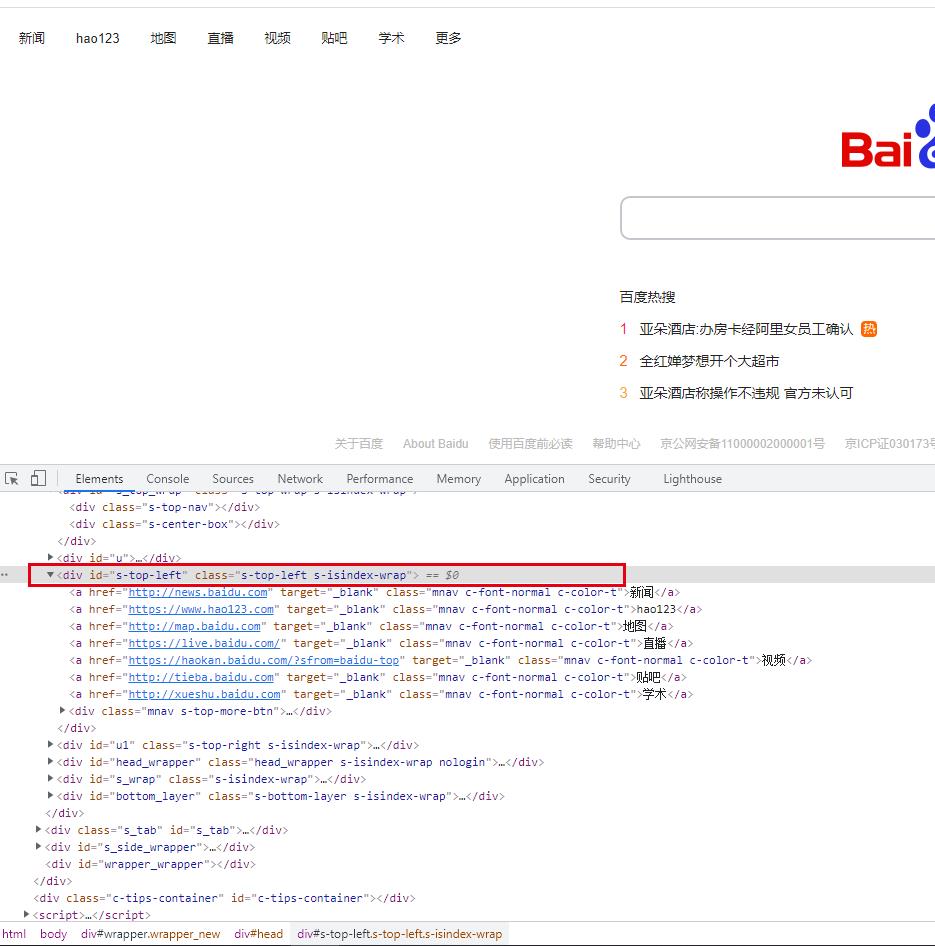
具体的爬取练习,比较简陋,为了更加明确的去获取想要的信息
import requests from pyquery import PyQuery as pq headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) \' \'Chrome/92.0.4515.126 Safari/537.36\', \'HOST\': \'www.baidu.com\'} url = \'http://www.baidu.com\' try: response = requests.get(url, headers=headers) if response.status_code == 200: # 由状态码判断返回结果 html = response.text doc = pq(html) for i in doc: print(doc(\'title\').text()) # 显示页面title信息 print(doc(\'div#s-top-left a\').text()) # 显示百度页面左上角a标签信息 except BaseException as e: print(e)
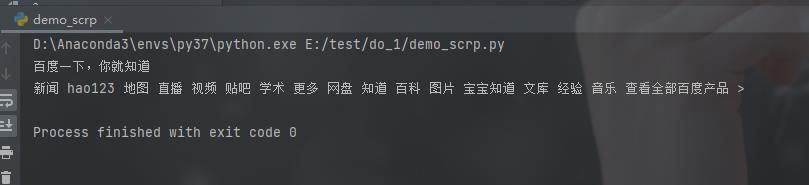
运行的结果如下所示:
2、直接上代码,爬取豆瓣TOP250
import csv import time from pyquery import PyQuery as pq import requests # 获取电影信息并写入到CSV文件中 def getDBMovie(baseurl): headers = { \'Host\': \'movie.douban.com\', \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/86.0.4240.111 Safari/537.36\' } try: html = requests.get(baseurl, headers=headers).text html = pq(html) mvList = html(\'.item\').items() for item in mvList: num = item.find(\'.pic em\').text() # 此处括号内容是css定位元素信息 title = item.find(\'.title\').html() link = item.find(\'.pic a\').attr(\'href\') star = item.find(\'.rating_num\').text() # print(num, title, link, star) # 打开文件并写入信息 with open(\'doubanMoive.csv\', \'a\', encoding=\'utf-8\', newline=\'\') as f: csv_write = csv.writer(f) csv_write.writerow([num, title, link, star]) except BaseException as e: print(e) # 创建存储的csv文件,并添加表头:序号、电影名称、链接、评分 def createFile(): with open(\'doubanMoive.csv\', \'w\', encoding=\'utf-8\', newline=\'\') as f: csv_write = csv.writer(f) csv_write.writerow([\'序号\', \'电影名称\', \'链接\', \'评分\']) # def saveFile(num, title, link, star): # with open(\'doubanMoive.csv\', \'a\', encoding=\'utf-8\', newline=\'\') as f: # csv_write = csv.writer(f) # csv_write.writerow([num, title, link, star]) if __name__ == \'__main__\': createFile() for page in range(0, 250, 25): base_url = \'http://movie.douban.com/top250?start={}\'.format(page) getDBMovie(base_url) time.sleep(3) # 设置一下时间,不然ip很容易被douban封掉
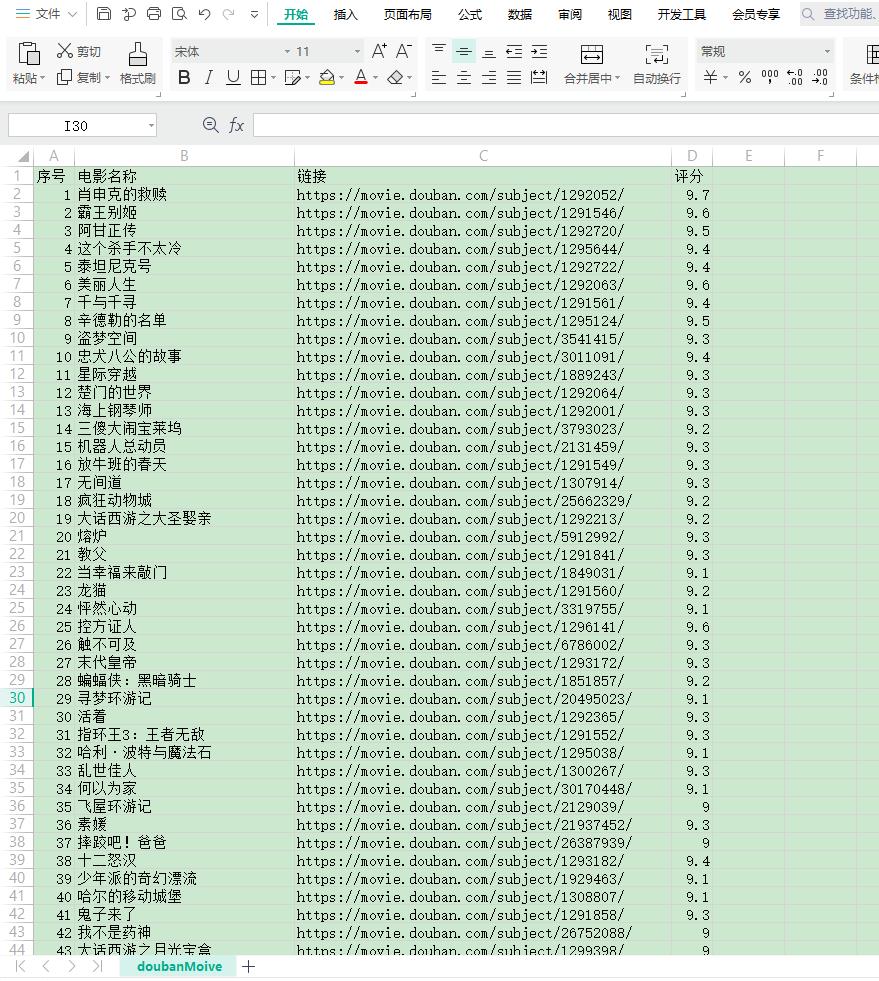
看一下CSV文件内容:
由于获取的信息比较少,可以再次进行优化,应该是可以获取更多的信息
3、爬取小说
在爬取小说的时候,问题最大的应该就乱码的问题了。所以需要注意的地方,应该是编码了。
这里使用的爬虫框架是BeautifulSoup
from bs4 import BeautifulSoup import requests url = \'https://www.17k.com/chapter/3038645/38755562.html\' headers = { \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/92.0.4515.134 Safari/537.36\' } page_req = requests.get(url, headers=headers) html = page_req.text.encode(\'iso-8859-1\') # 编码信息 尝试使用utf8,看到的信息都是乱码 bf = BeautifulSoup(html, \'html.parser\') texts = bf.find_all(\'div\', class_=\'readAreaBox content\') # 带入了标题等信息 # texts = bf.find_all(\'div\', class_=\'p\') # 章节信息 print(texts[0].text) # print(type(texts)) # print(texts[0].text.replace(\'\\xa0\' * 8, \'\\n\\n\')) # 页面字段处理 # 写入到文件中 # with open(\'demo_scrap.txt\', \'a\', encoding=\'utf-8\') as f: # f.write(texts[0].text)
看一下运行的效果图:
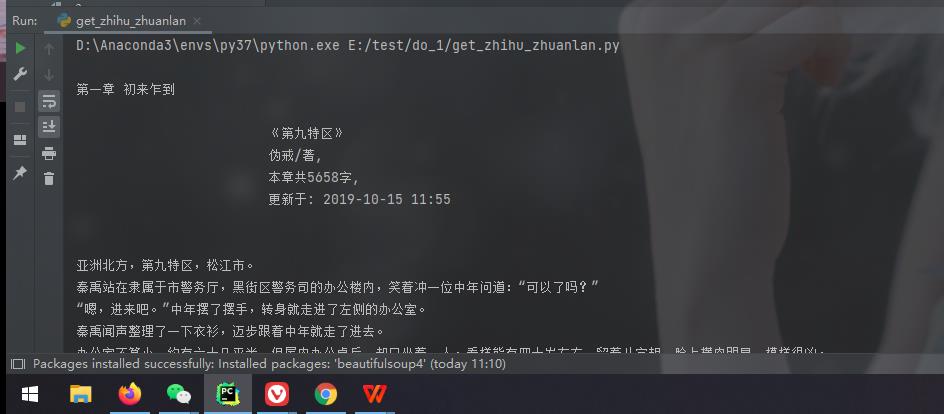
爬取了另一个小说网站
from bs4 import BeautifulSoup import requests url = \'https://www.biqooge.com/0_1/1.html\' headers = { \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/92.0.4515.134 Safari/537.36\' } page_req = requests.get(url, headers=headers) html = page_req.text.encode(\'iso-8859-1\') bf = BeautifulSoup(html, \'html.parser\') texts = bf.find_all(\'div\', id=\'content\') # print(texts[0].text) print(texts[0].text.replace(\'\\xa0\' * 8, \'\\n\\n\'))
效果如下:
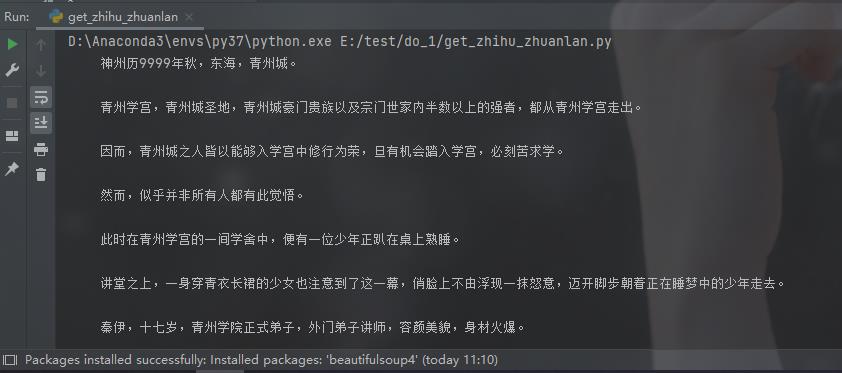
各种大胆的尝试,不过也有些网站无法爬取到数据。对于爬虫,总体感觉和使用自动化框架selenium有些共通的部分,如果使用selenium,估计就不会被识别为爬虫的机器人了,这是一个思路。哈哈
还需要去慢慢尝试使用不同的框架去获取到自己想要看到数据才行,分享一下实验结果,欢迎各位大神来一起来讨论,谢谢!
以上是关于python 爬虫学习练习爬取电影小说的主要内容,如果未能解决你的问题,请参考以下文章