Flink 和 Iceberg 如何解决数据入湖面临的挑战
Posted Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 和 Iceberg 如何解决数据入湖面临的挑战相关的知识,希望对你有一定的参考价值。
摘要:阿里巴巴技术专家胡争在 4 月 17 日上海站 Meetup 分享,文章内容为借助 Flink 和 Iceberg 来尝试解决数据入湖的相关挑战,帮助业务同学更加高效地聚焦在自身的业务挑战上。内容包括:
数据入湖的核心挑战
Apache Iceberg 介绍
Flink 和 Iceberg 如何解决问题
社区 Roadmap

一、数据入湖的核心挑战
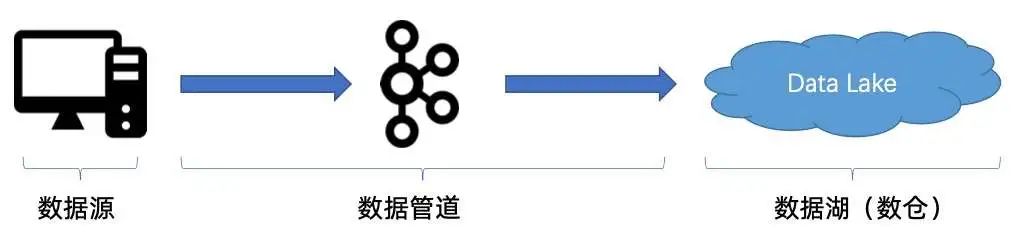
1. Case #1:程序 BUG 导致数据传输中断
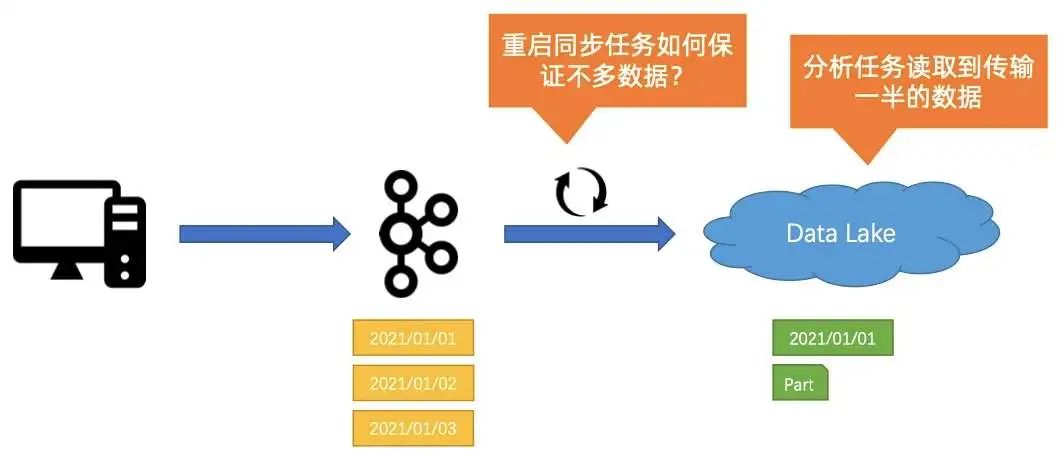
首先,当数据源通过数据管道传到数据湖(数仓)时,很有可能会遇到作业有 BUG 的情况,导致数据传到一半,对业务造成影响;
第二个问题是当遇到这种情况的时候,如何重起作业,并保证数据不重复也不缺失,完整地同步到数据湖(数仓)中。
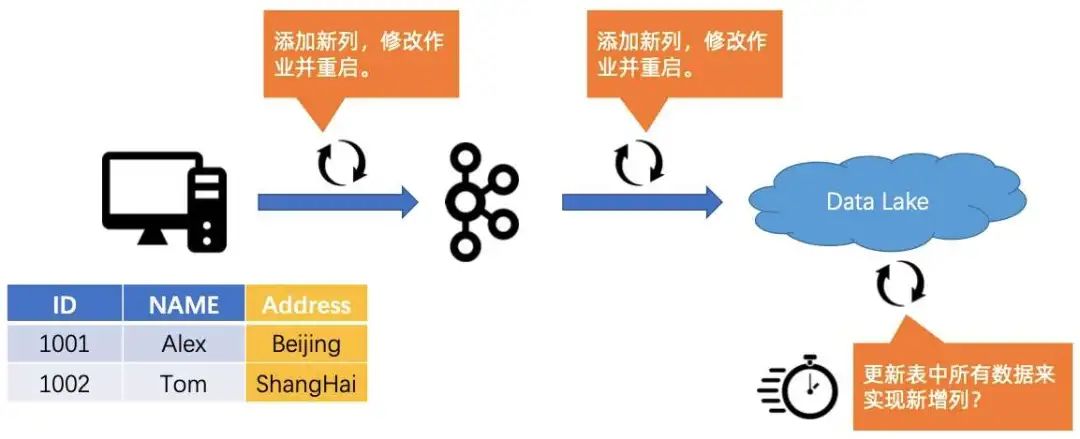
2. Case #2:数据变更太痛苦
数据变更
首先,我们需要把 Source 表加上一个列 Address,然后再把到 Kafka 中间的链路加上链,然后修改作业并重启。接着整条链路得一路改过去,添加新列,修改作业并重启,最后把数据湖(数仓)里的所有数据全部更新,从而实现新增列。这个过程的操作不仅耗时,而且会引入一个问题,就是如何保证数据的隔离性,在变更的过程中不会对分析作业的读取造成影响。

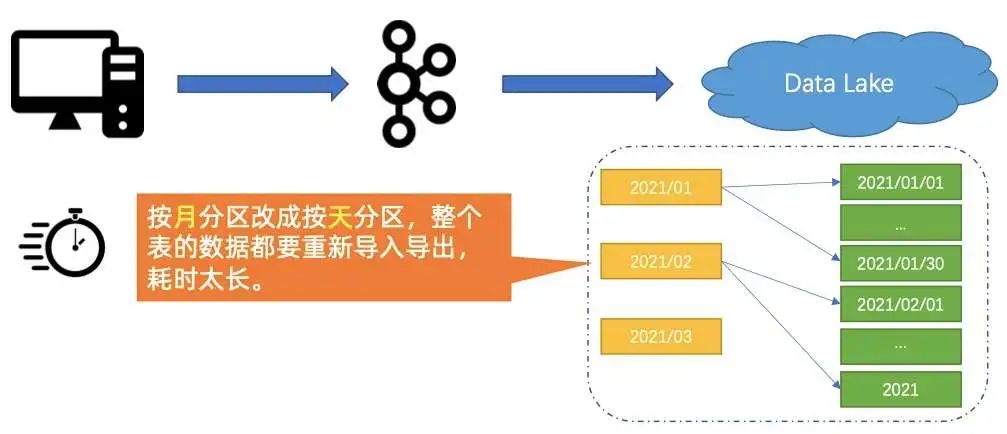
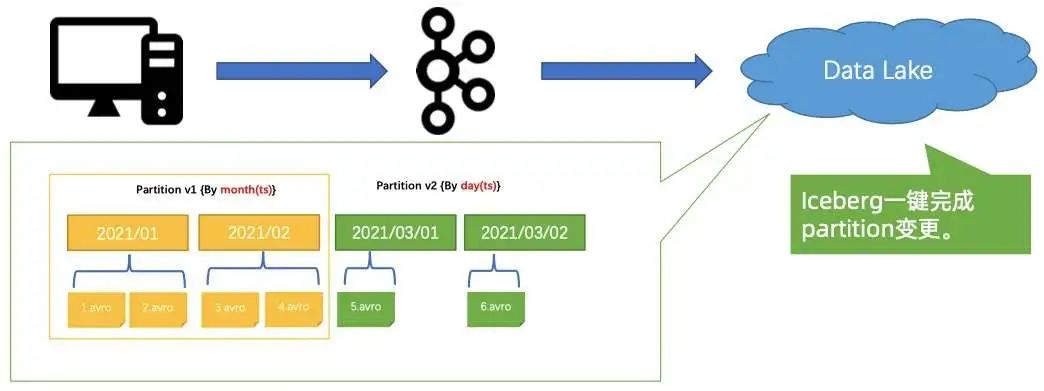
分区变更
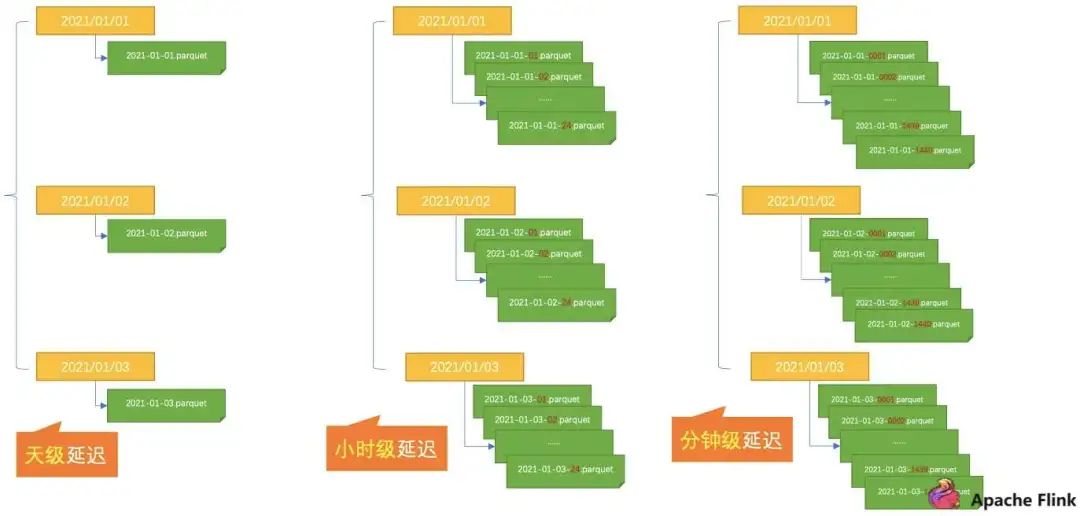
如下图所示,数仓里面的表是以 “月” 为单位进行分区,现在希望改成以 “天” 为单位做分区,这可能就需要将很多系统的数据全部更新一遍,然后再用新的策略进行分区,这个过程十分耗时。
3. Case #3:越来越慢的近实时报表?
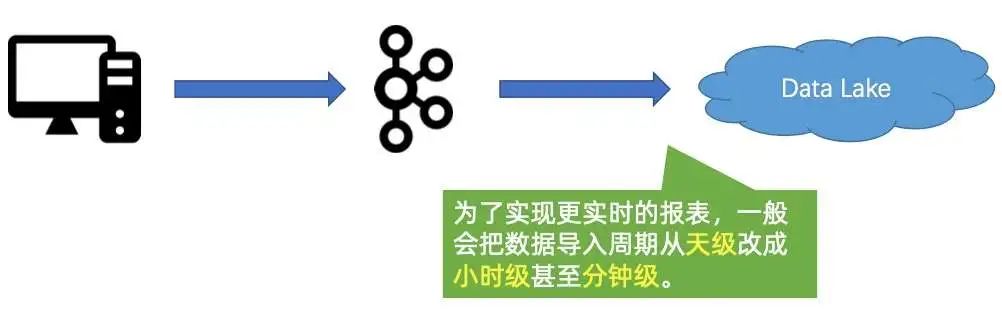
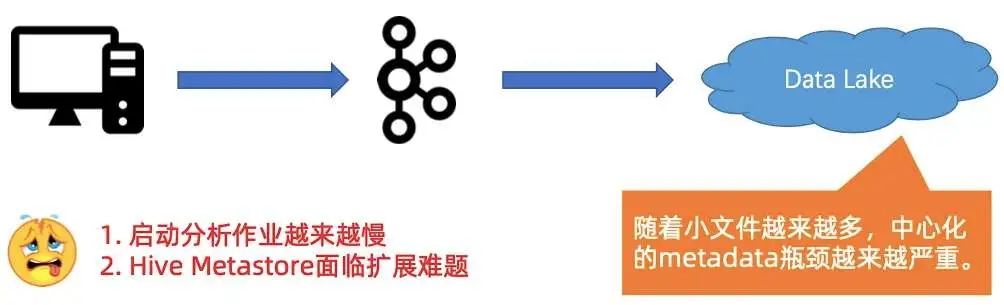
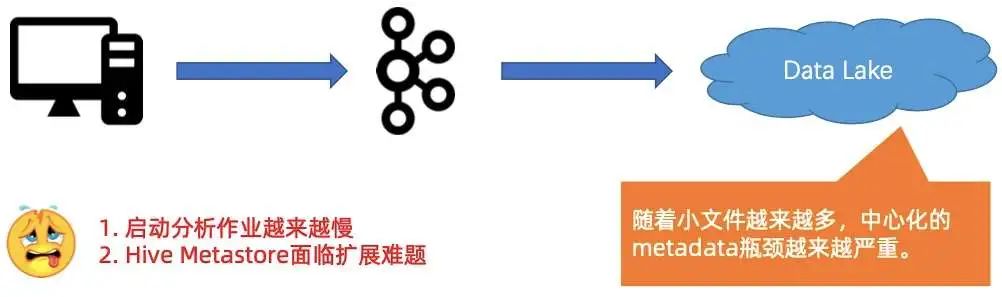
第一个压力是,启动分析作业越来越慢,Hive Metastore 面临扩展难题,如下图所示。
-
随着小文件越来越多,使用中心化的 Metastore 的瓶颈会越来越严重,这会造成启动分析作业越来越慢,因为启动作业的时候,会把所有的小文件原数据都扫一遍。 -
第二是因为 Metastore 是中心化的系统,很容易碰到 Metastore 扩展难题。例如 Hive,可能就要想办法扩后面的 mysql,造成较大的维护成本和开销。
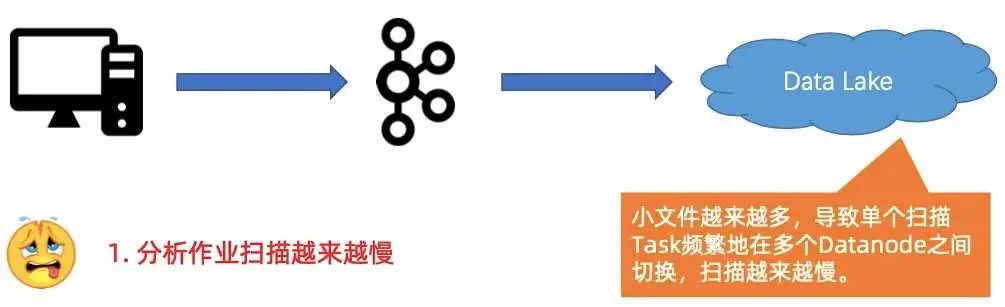
第二个压力是扫描分析作业越来越慢。
随着小文件增加,在分析作业起来之后,会发现扫描的过程越来越慢。本质是因为小文件大量增加,导致扫描作业在很多个 Datanode 之间频繁切换。
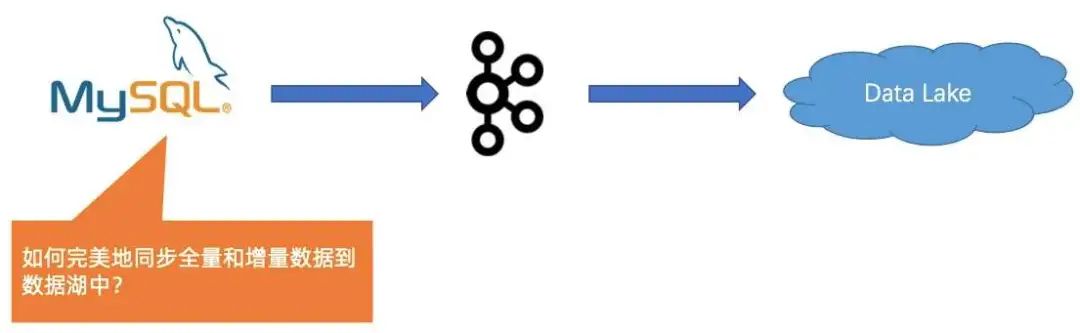
4. Case #4:实时地分析 CDC 数据很困难
首先从源端来看,比如要将 MySQL 的数据同步到数据湖进行分析,可能会面临一个问题,就是 MySQL 里面有存量数据,后面如果不断产生增量数据,如何完美地同步全量和增量数据到数据湖中,保证数据不多也不少。
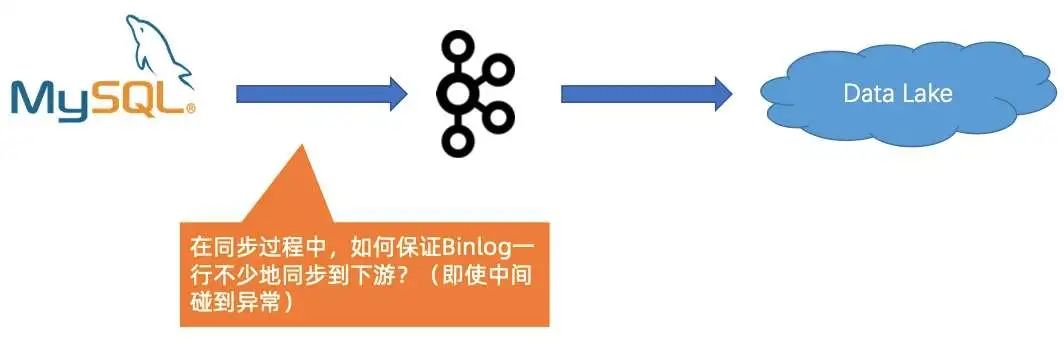
此外,假设解决了源头的全量跟增量切换,如果在同步过程中遇到异常,如上游的 Schema 变更导致作业中断,如何保证 CDC 数据一行不少地同步到下游。
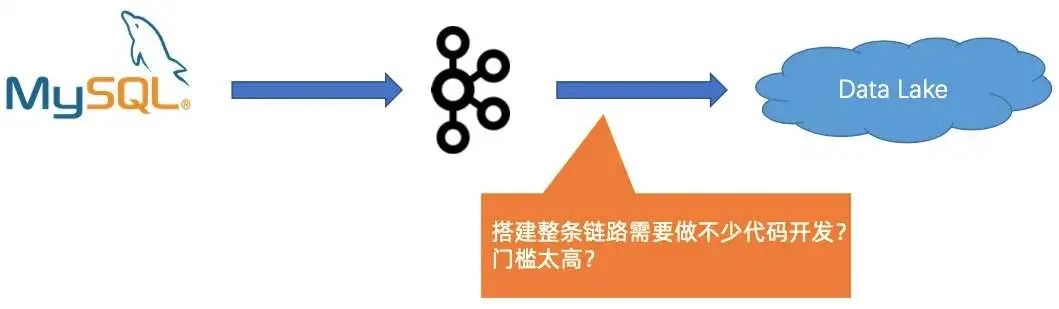
整条链路的搭建,需要涉及源头全量跟同步的切换,包括中间数据流的串通,还有写入到数据湖(数仓)的流程,搭建整个链路需要写很多代码,开发门槛较高。
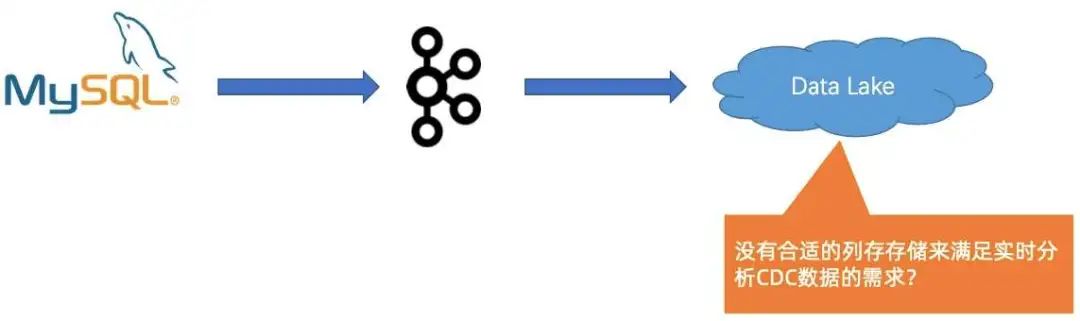
最后一个问题,也是关键的一个问题,就是我们发现在开源的生态和系统中,很难找到高效、高并发分析 CDC 这种变更性质的数据。
5. 数据入湖面临的核心挑战
数据同步任务中断
-
无法有效隔离写入对分析的影响; -
同步任务不保证 exactly-once 语义。
端到端数据变更
-
DDL 导致全链路更新升级复杂; -
修改湖/仓中存量数据困难。
越来越慢的近实时报表
-
频繁写入产生大量小文件; -
Metadata 系统压力大, 启动作业慢; -
大量小文件导致数据扫描慢。
无法近实时分析 CDC 数据
-
难以完成全量到增量同步的切换; -
涉及端到端的代码开发,门槛高; -
开源界缺乏高效的存储系统。
二、Apache Iceberg 介绍
1. Netflix:Hive 上云痛点总结
■ 痛点一:数据变更和回溯困难
-
不提供 ACID 语义。在发生数据改动时,很难隔离对分析任务的影响。典型操作如:INSERT OVERWRITE;修改数据分区;修改 Schema; -
无法处理多个数据改动,造成冲突问题; -
无法有效回溯历史版本。
■ 痛点二:替换 HDFS 为 S3 困难
-
数据访问接口直接依赖 HDFS API; -
依赖 RENAME 接口的原子性,这在类似 S3 这样的对象存储上很难实现同样的语义; -
大量依赖文件目录的 list 接口,这在对象存储系统上很低效。
■ 痛点三:太多细节问题
-
Schema 变更时,不同文件格式行为不一致。不同 FileFormat 甚至连数据类型的支持都不一致; -
Metastore 仅维护 partition 级别的统计信息,造成不 task plan 开销;Hive Metastore 难以扩展; -
非 partition 字段不能做 partition prune。
2. Apache Iceberg 核心特性
通用化标准设计
-
完美解耦计算引擎 -
Schema 标准化 -
开放的数据格式 -
支持 Java 和 Python 完善的 Table 语义
-
Schema 定义与变更 -
灵活的 Partition 策略 -
ACID 语义 Snapshot 语义 丰富的数据管理
-
存储的流批统一 -
可扩展的 META 设计支持 -
批更新和 CDC -
支持文件加密 性价比
-
计算下推设计 -
低成本的元数据管理 -
向量化计算 -
轻量级索引
3. Apache Iceberg File Layout

4. Apache Iceberg Snapshot View
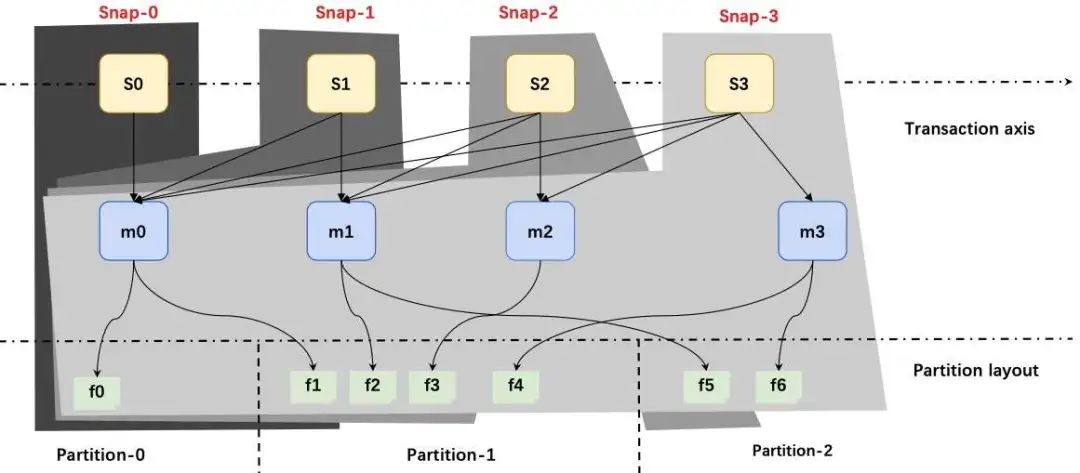
最上面黄色的是快照;
中间蓝色的是 Manifest;
最下面是文件。
5. 选择 Apache Iceberg 的公司

NetFlix 现在是有数百PB的数据规模放到 Apache Iceberg 之上,Flink 每天的数据增量是上百T的数据规模。
Adobe 每天的数据新增量规模为数T,数据总规模在几十PB左右。
AWS 把 Iceberg 作为数据湖的底座。
Cloudera 基于 Iceberg 构建自己整个公有云平台,像 Hadoop 这种 HDFS 私有化部署的趋势在减弱,上云的趋势逐步上升,Iceberg 在 Cloudera 数据架构上云的阶段中起到关键作用。
苹果有两个团队在使用:
-
一是整个 iCloud 数据平台基于 Iceberg 构建; -
二是人工智能语音服务 Siri,也是基于 Flink 跟 Iceberg 来构建整个数据库的生态。
三、Flink 和 Iceberg 如何解决问题
回到最关键的内容,下面阐述 Flink 和 Iceberg 如何解决第一部分所遇到的一系列问题。
1. Case #1:程序 BUG 导致数据传输中断


2. Case #2:数据变更太痛苦
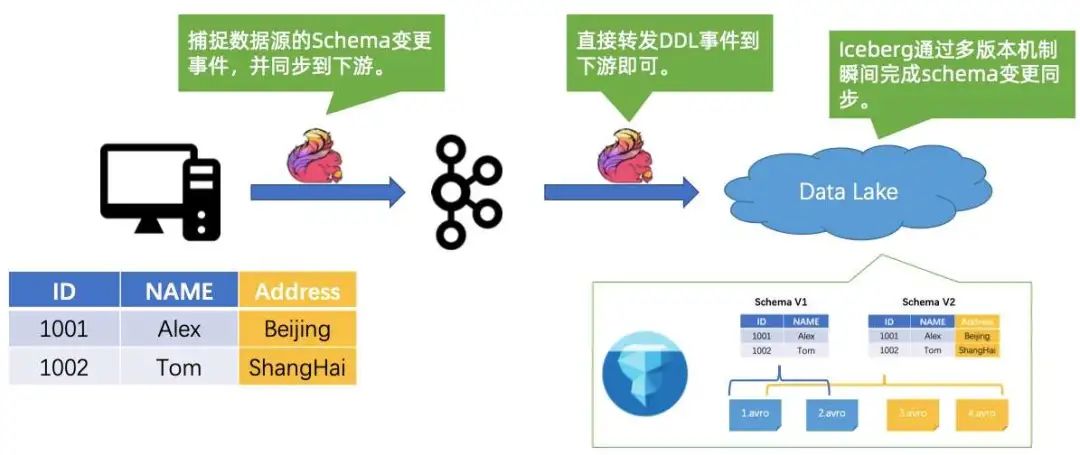
3. Case #3:越来越慢的近实时报表?

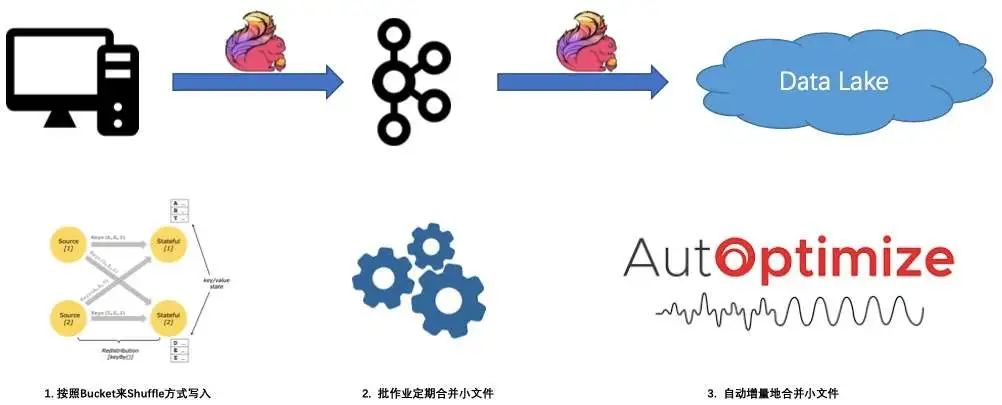
第一个方案是在写入的时候优化小文件的问题,按照 Bucket 来 Shuffle 方式写入,因为 Shuffle 这个小文件,写入的文件就自然而然的小。
第二个方案是批作业定期合并小文件。
第三个方案相对智能,就是自动增量地合并小文件。
4. Case #4:实时地分析CDC数据很困难
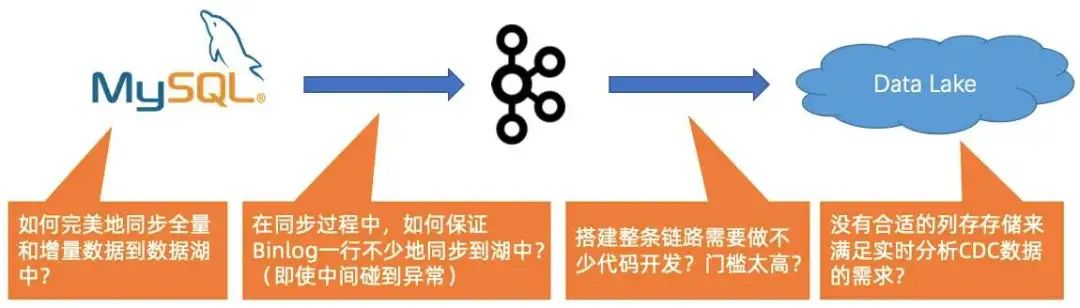
首先是是全量跟增量数据同步的问题,社区其实已有 Flink CDC Connected 方案,就是说 Connected 能够自动做全量跟增量的无缝衔接。

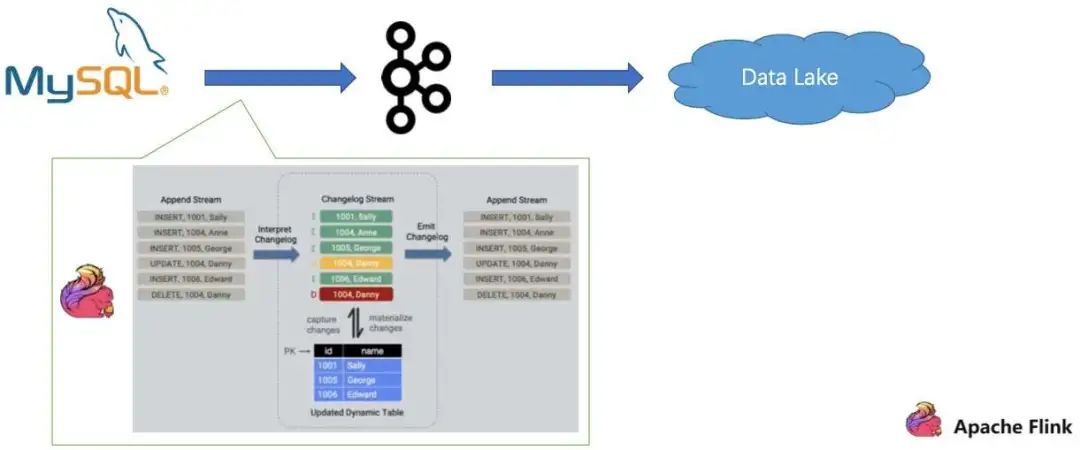
第二个问题是在同步过程中,如何保证 Binlog 一行不少地同步到湖中, 即使中间碰到异常。
对于这个问题,Flink 在 Engine 层面能够很好地识别不同类型的事件,然后借助 Flink 的 exactly once 的语义,即使碰到故障,它也能自动做恢复跟处理。
第三个问题是搭建整条链路需要做不少代码开发,门槛太高。
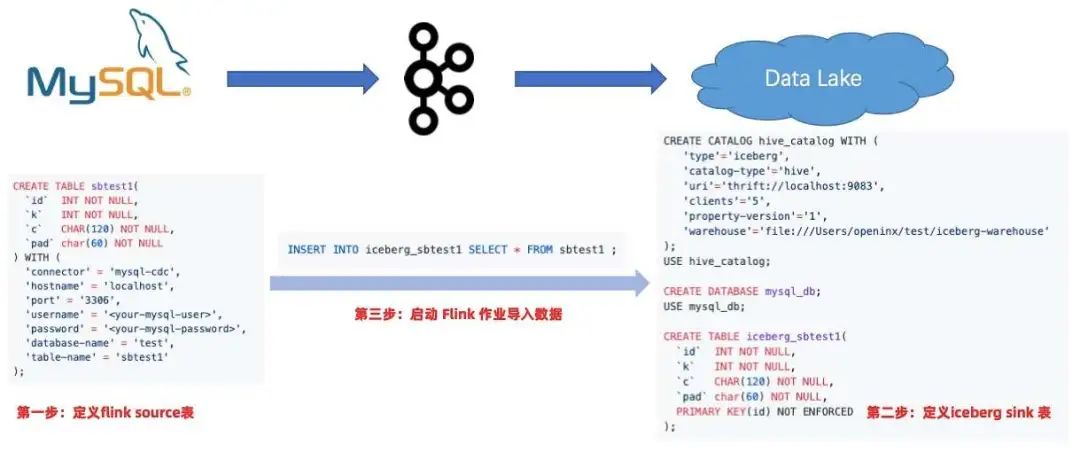
在用了 Flink 和 Data Lake 方案后,只需要写一个 source 表和 sink 表,然后一条 INSERT INTO,整个链路就可以打通,无需写任何业务代码。
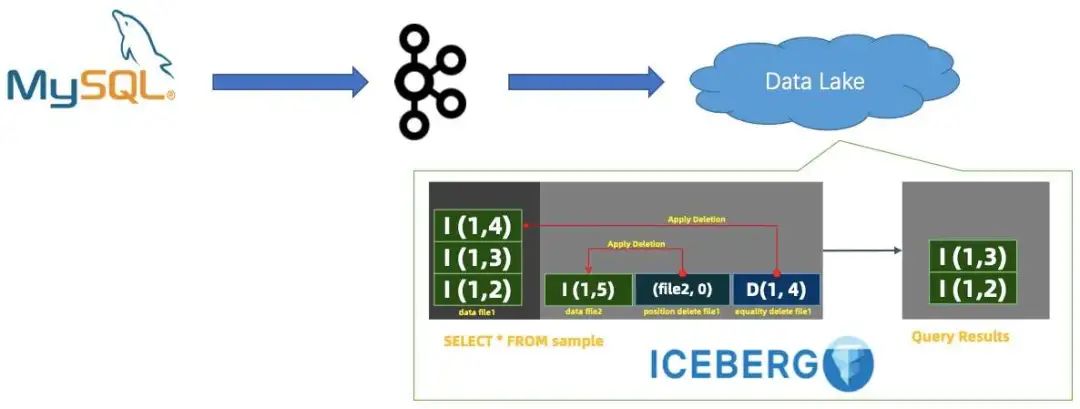
最后是存储层面如何支持近实时的 CDC 数据分析。
四、社区 Roadmap
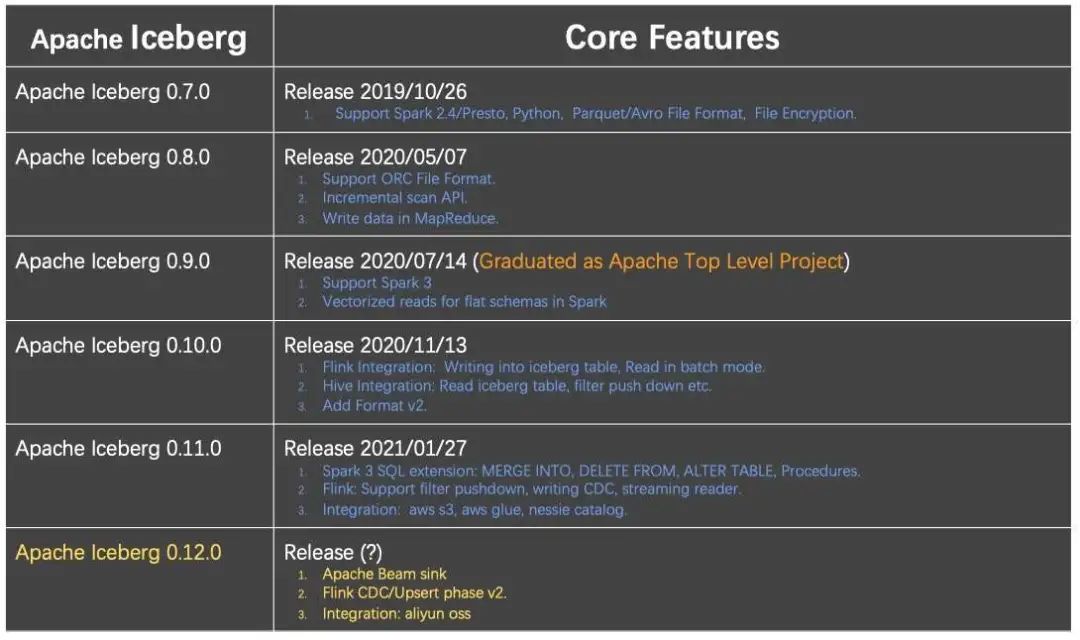
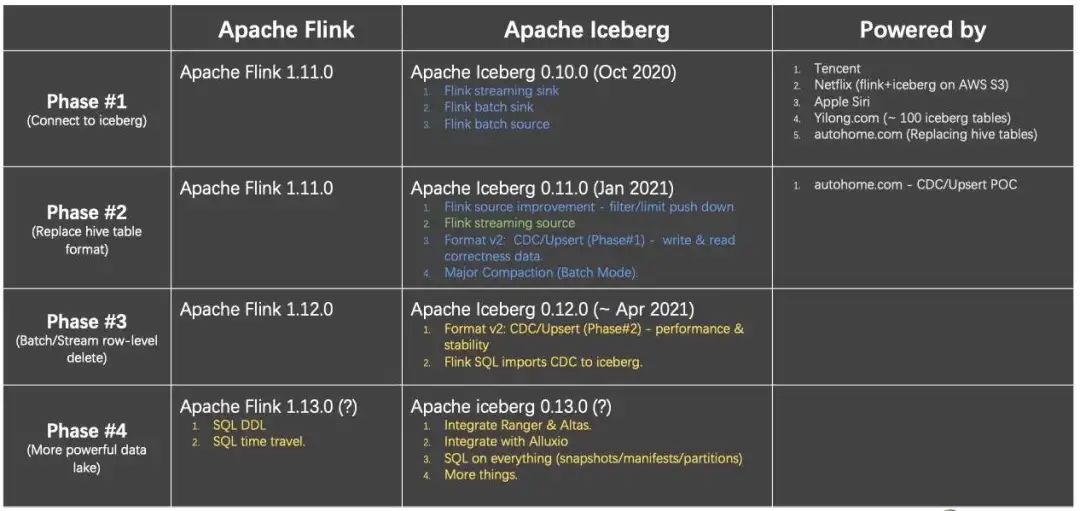
第一个阶段是 Flink 与 Iceberg 建立连接。
第二阶段是 Iceberg 替换 Hive 场景。在这个场景下,有很多公司已经开始上线,落地自己的场景。
第三个阶段是通过 Flink 与 Iceberg 解决更复杂的技术问题。
第四个阶段是把这一套从单纯的技术方案,到面向更完善的产品方案角度去做。

以上是关于Flink 和 Iceberg 如何解决数据入湖面临的挑战的主要内容,如果未能解决你的问题,请参考以下文章