云原生应用性能优化之道(附免费电子书分享)
Posted 漫谈云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生应用性能优化之道(附免费电子书分享)相关的知识,希望对你有一定的参考价值。
本文整理自前段时间我在 A2M 人工智能与机器学习创新峰会上的同名分享。
何为云原生
什么是云原生并没有一个统一的定义,比较权威的是 CNCF 的定义:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
云原生技术促进基础设施、系统架构乃至应用架构面向动态的云进行设计,提高整个系统的可用性、可靠性以及弹性扩展能力。伴随着云原生技术的普及,我们越来越多的看到基础设施的云化、系统架构的云原生化以及应用程序的容器化等。
典型云原生应用
一个典型的云原生应用如下图所示,通常包括云平台、容器平台、微服务平台、Devops平台以及应用微服务:
云原生挑战
从云原生技术的落地情况来看,它的优点非常明显:
-
应用容错性更好 -
服务发现更为简单 -
管理和维护更方便 -
整个系统不同模块的耦合性明显降低 -
自动化发布和频繁变更也成为现实
但这些优点不是本文的重点,本文的重点是云原生应用落地时的问题,特别是性能问题。
虽然云原生技术带来了上述的各种优点,但云原生落地时采用的诸如容器、微服务、服务网格等各种技术也会带来很多的挑战。从性能的角度来说,最典型的三个问题有:
-
服务间依赖复杂:单体应用到微服务简化了每个微服务自身的维护,但是也带来了更多的服务间调用,直接依赖和间接依赖变得复杂。 -
应用性能下降:不同模块间的调用不再依赖共享内存或共享代码库,而变成了网络调用,带来一定的调用开销。同时不合理的应用架构也可能会带来性能下降,并且导致问题的定位困难。 -
服务治理困难:每个微服务都要有自己的路由、分流、熔断、降级机制,这就导致微服务治理无法统一,复杂度失控。
接下来,我们来看怎么解决这些挑战。
优化一:依赖优化
针对服务间依赖复杂的问题,可以从下面这三个点出发,来优化应用依赖:
-
适度微服务拆分 -
规范API接口 -
统一配置管理
1. 适度微服务拆分
拆分微服务之前,我们先来想一下,微服务拆分是为了解决哪些问题?
-
职责不清 -
相互耦合:代码耦合、数据库耦合、缓存耦合等等 -
无法独立发布 -
公共依赖冲突
有了这些问题,在拆分时也就有了更好的依据。针对这些问题,也就有了相应的拆分方法:
-
按职责划分微服务,把相同职责的模块或相同业务的模块划分到同一个微服务中(业务微服务)。对于通用痛点,下沉成为基础微服务。 -
模块解耦,每个模块使用独立的数据存储,禁止相互之间直接通过数据库进行交互。 -
独立发布,每个微服务独立打包、独立发布,避免影响其他模块。 -
独立依赖,针对公共依赖冲突的问题,可以将模块的依赖独立开来,比如使用独立的代码仓库。
2. 规范 API 接口
不同微服务之间可以按照需要使用不同的编程语言和编程框架,但微服务之间的 API 接口需要统一的规范,以保证每个微服务可以独立更新发布(这儿实际上是提升发布性能)。这些规范包括:
-
统一服务注册和发现 -
统一认证鉴权 -
RESTful API -
幂等(请求执行的结果不依赖于执行次数)
3. 统一配置管理
配置特别是动态配置管理是确保微服务变更快速生效的核心步骤,而涉及多个微服务时就需要一个统一的平台把它们集中管理起来。配置管理通常需要提供以下功能:
-
配置中心 -
监控告警 -
动态降级 -
流量切换
Istio 案例
Istio 案例(Simplified Istio[1]):
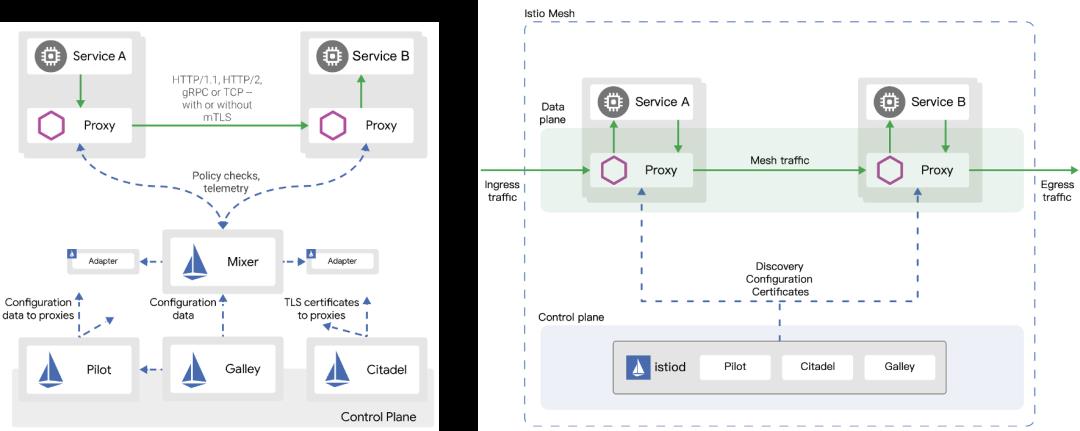
Istio 1.4:
-
架构优先:职责清晰 -
问题 -
安装配置复杂,性能差 -
Mixer 负责请求前置检查、配额管理以及遥测,每次请求都需要 Mixer 的远程调用,这就带来了性能开销,也是当时Istio最大的问题。 -
优化:在 Envoy 中增加 mixer filter,对 Mixer 策略进行缓存
Istio 1.4 -> 1.5 架构变迁:
-
架构简洁,部署和升级更为便捷 -
去掉 Mixer,降低遥测延迟,降低50%的延迟和CPU消耗 -
进程外的扩展替换为为Envoy WASM,删除了很多不必要的CRD,简化了用户用户使用体验 -
合并控制平面组件到单体应用 istiod 内部,降低了安装、配置和问题诊断的复杂度
Istio 是一个很好的从微服务回归单体应用的案例。在没有量化的性能度量之前,各种性能优化不仅没能从根本上解决性能问题,还导致可维护性、复杂性、问题诊断等变得极为复杂。而新的架构在吸收用户反馈和性能度量的基础上,简化架构的同时,不仅提升了性能,还大大简化了用户体验。
二、云原生应用性能优化
说完了依赖优化,接下来看看应用自身的性能下降问题该如何解决。这包括以下三个方面:
-
过早优化是万恶之源 -
性能评估 - 性能度量和监控 -
性能优化 - 提升应用性能
1. 过早优化是万恶之源
“过早优化是万恶之源”,我非常赞同这一点,过早优化之所以不可取,主要是以下几个原因:
-
复杂性提升 -
降低可维护性 -
阻碍新功能特性
一方面,优化会带来复杂性的提升,降低可维护性;另一方面,需求不是一成不变的。针对当前情况进行的优化,很可能并不适应快速变化的新需求。这样,在新需求出现时,这些复杂的优化,反而可能阻碍新功能的开发。
所以,性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化。
2. 性能评估 - 性能度量和监控
我们解决性能问题的目的,自然是想得到一个性能提升的效果。为了评估这个效果,我们需要对系统的性能指标进行量化。
-
性能度量
在进行量化时需要注意,不要局限在单一维度的指标上,你至少要从应用程序和系统资源这两个维度,分别选择不同的指标。比如,以 Web 应用为例:
-
应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能。 -
系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况。
-
二八原则
“二八原则”,也就是说 80% 的问题都是由 20% 的代码导致的。只要找出这 20% 的位置,你就可以优化 80% 的性能。所以,我想表达的是,并不是所有的性能问题都值得优化。
-
关注整体
我们当然想选能最大提升性能的方法,这其实也是性能优化的目标。但要注意,现实情况要考虑的因素却没那么简单。最直观来说,性能优化并非没有成本。性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。也就是说,很可能你优化了一个指标,另一个指标的性能却变差了。
3. 性能优化 - 提升应用性能
常用的性能优化方法包括:
-
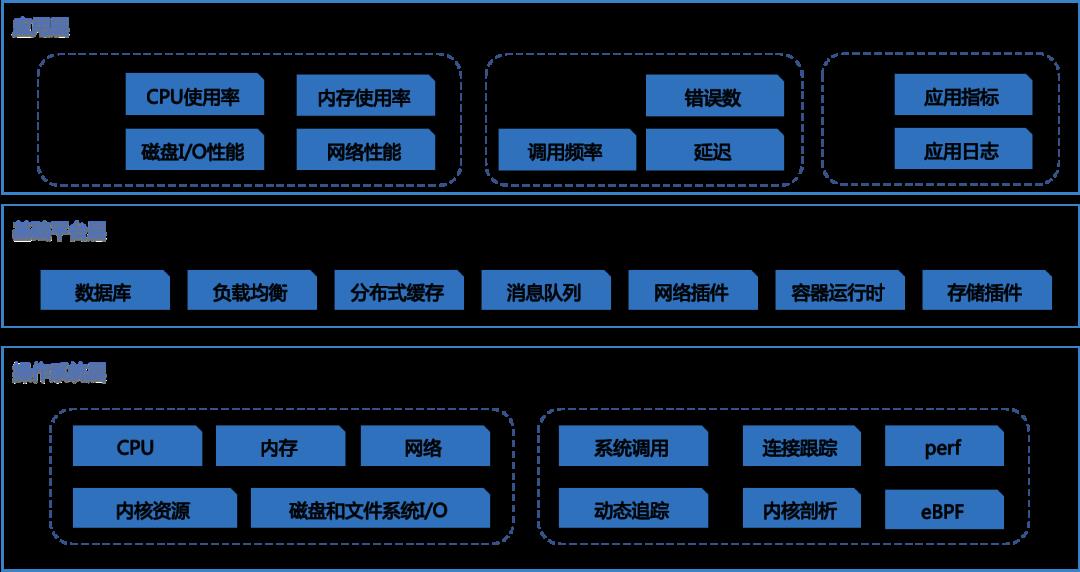
USE 法: 从系统资源瓶颈的角度来说,从使用率、饱和度以及错误数这三个方面,来优化 CPU、内存、磁盘和文件系统 I/O、网络以及内核资源限制等各类软硬件资源。 -
RED 法:请求量(Request rate)、错误(Error)、响应时间(Duration)。 -
异常优化:避免雪崩,一方面保护自己只接收可处理的请求,另一方面不要给其他服务DDOS。 -
在具体设计微服务时,可以参考著名的微服务十二要素原则。
以下就是微服务十二要素原则以及设计示例:
-
基准代码:一份基准代码,多份部署 - Github -
依赖:显式声明依赖关系 - Azure Devops -
配置:在环境中存储配置 - Configmap -
后端服务:把后端服务当作附加资源 - AzureDisk/Cosmos -
构建,发布,运行:严格分离构建和运行 - Devops -
进程:以一个或多个无状态进程运行应用 - Deployment -
端口绑定:通过端口绑定提供服务 - Service -
并发:通过进程模型进行扩展 - HPA/CA -
易处理:快速启动和优雅终止可最大化健壮性 - Health Check/Signal -
开发环境与线上环境等价 - AKS -
日志:把日志当作事件流 - Container Insight -
管理进程:后台管理任务当作一次性进程运行 - CronJob
容器性能优化案例
三、服务治理优化
回到前面说的第三个问题,服务治理困难。每个微服务都要有自己的路由、分流、熔断、降级机制,这就导致微服务治理无法统一,复杂度逐步失控。
要解决这个问题,可以从以下两个方面考虑:
第一个方面,在前面微服务拆分部分也提到过,这些都是所有服务都会碰到的通用痛点,理应下沉成为基础服务,作为容器 平台的基础能力,提供给所有应用。常见的服务治理策略包括服务发现、请求认证、容错限流、链路跟踪等。
第二个方面是 Devops,这是要实现频繁变更、独立部署、故障自动处理等必备的基础能力。一个 Devops 平台至少要提供持续集成、持续部署、监控平台、日志处理等几个基础功能。
这两个方面看起来跟性能优化不搭边,但实际上并不是的。这里提三个问题你就明白了:
1)在服务变更过程中,服务重启会不会导致服务可用性下降?2)当依赖服务出现性能问题的时候,能不能保证自身服务不被打垮?3)当出现故障的时候,能不能快速发现并且自动修复?
Github血泪教训
2020年7月13日 Github中断4小时。这个事故的原因比较简单,Pod 出现了不可用,Kubernetes尝试自动恢复失败,事故蔓延到整个集群,最终容量不足,服务不可用。
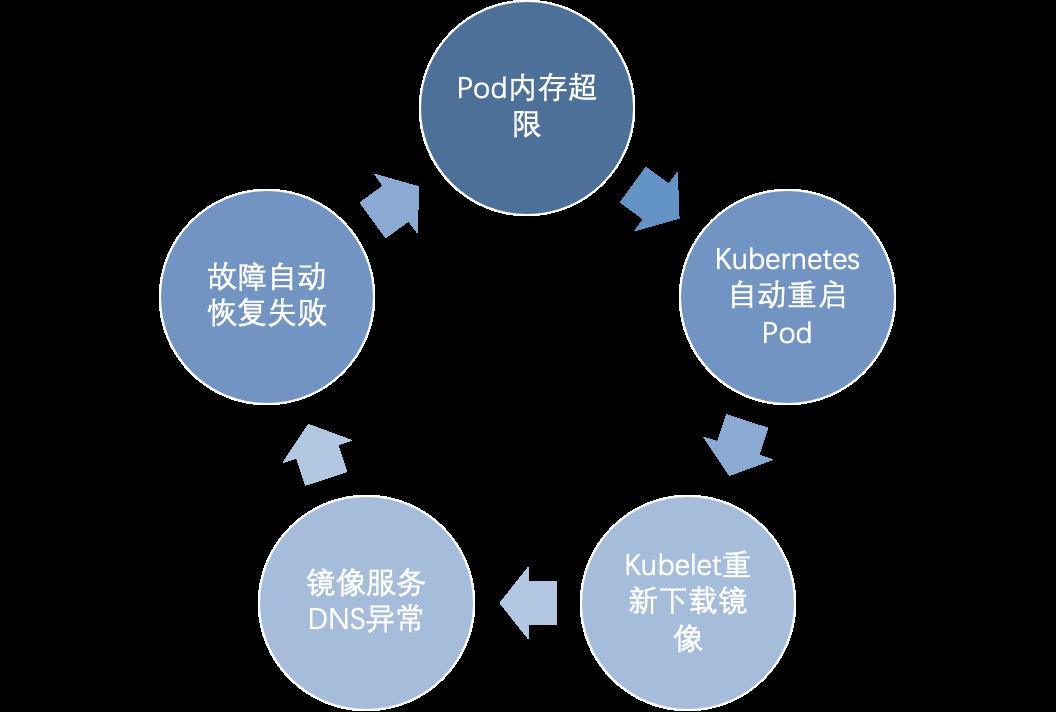
-
通常,Pod 不可用的时候,Kubernetes 会尝试自动恢复,这个是预期的行为。 -
由于镜像拉取策略设置成Always,容器重启的时候需要重新拉取镜像。 -
不幸的是,由于 DNS 服务当时正在维护,Kubernetes 无法正确解析镜像仓库,从而镜像无法拉取。 -
监控系统发现问题之后,尝试通过重新部署来恢复。但重新部署也失败了,并且导致问题在整个集群中蔓延。 -
最终的结果就是服务中断,知道 DNS 服务重启之后才恢复正常。
这些问题如何解决呢?Github 在事后总结[2]中给出了几个方案:
-
如果本地已经有镜像了,Pod重启不应该再去拉取 -
减少依赖,镜像缓存到 Node -
增强 DNS 服务可用性,越是基础服务越应该保证其可用性 -
重新评估自动恢复机制以避免异常导致的可用性降低
更多的性能优化方法可以参考极客时间专栏《Linux性能优化实战[3]》。
资料分享
最后分享几本免费的云原生和 Kubernetes 书籍:
参考资料
Simplified Istio: https://docs.google.com/document/d/1v8BxI07u-mby5f5rCruwF7odSXgb9G8-C9W5hQtSIAg/edit#heading=h.xw1gqgyqs5b
[2]Github事故总结: https://github.blog/2020-08-05-github-availability-report-july-2020/
[3]Linux性能优化实战: https://time.geekbang.org/column/intro/140
以上是关于云原生应用性能优化之道(附免费电子书分享)的主要内容,如果未能解决你的问题,请参考以下文章
阿里云联合平行云推出云XR平台,支持沉浸式体验应用快速落地 | 电子书免费下载
阿里云联合平行云推出云XR平台,支持沉浸式体验应用快速落地 | 电子书免费下载