TiDB 在小米的落地及云原生探索丨PingCAP DevCon 2021 回顾
Posted PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB 在小米的落地及云原生探索丨PingCAP DevCon 2021 回顾相关的知识,希望对你有一定的参考价值。
本文根据 PingCAP DevCon 2021 上来自小米的数据库研发工程师刘子东的分享整理而成,介绍了 TiDB 在小米的落地以及小米在云原生领域的探索。
现状
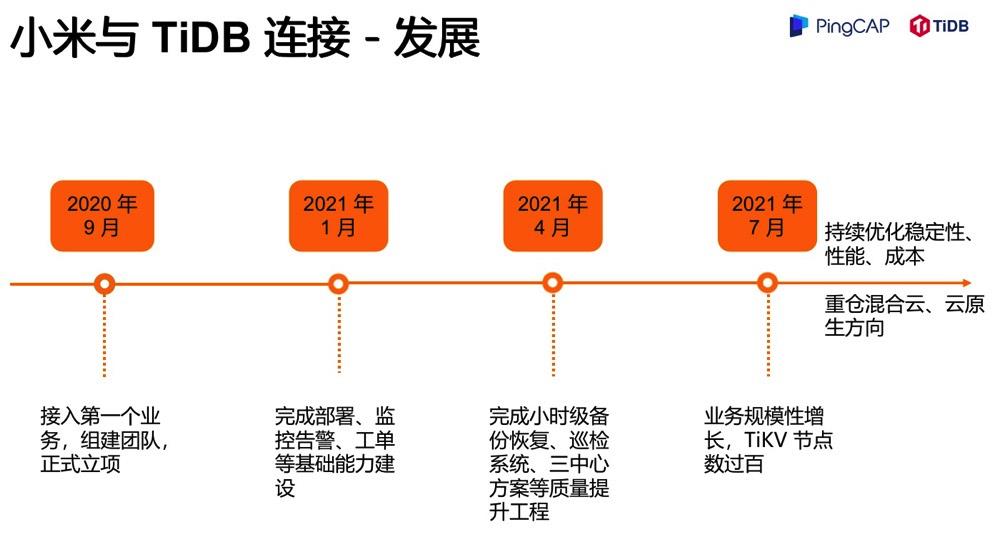
发展
挑战
点赞
第一个是社区支持非常友好,文档非常完善,因此我们的接入非常快速。我之前也讲了,其实仅仅一个季度的时间,我们就把整个以前看来各种高大上的平台做好,可以对业务提供服务了。
第二个是完善的数据库周边生态,降低了运维的成本。我们知道一个数据库产品的落地需要有自动化部署、监控告警、运维管理平台等一系列基建,得益于 TiDB 社区良好的可观测性和丰富的生态组件如 TiUP / BR / Dashboard 等等,我们很轻松的完成了相关建设,极大降低了运维成本,减轻了运维压力。
第三个,跨机房,多机房容灾,异地多活这个话题也是一个很深的话题。我们真正实践起来发现 TiDB 在跨机房上表现得非常优秀,很容易落地三中心的计划。对于一些需要异地容灾的业务来说,TiDB是一个很好的选择。
第四个,加密存储及传输的功能。透明数据加密 (Transparent Data Encryption),简称 TDE,是 TiDB 推出的一个新特性,应用在风控隐私集群上,极大简化了业务逻辑。
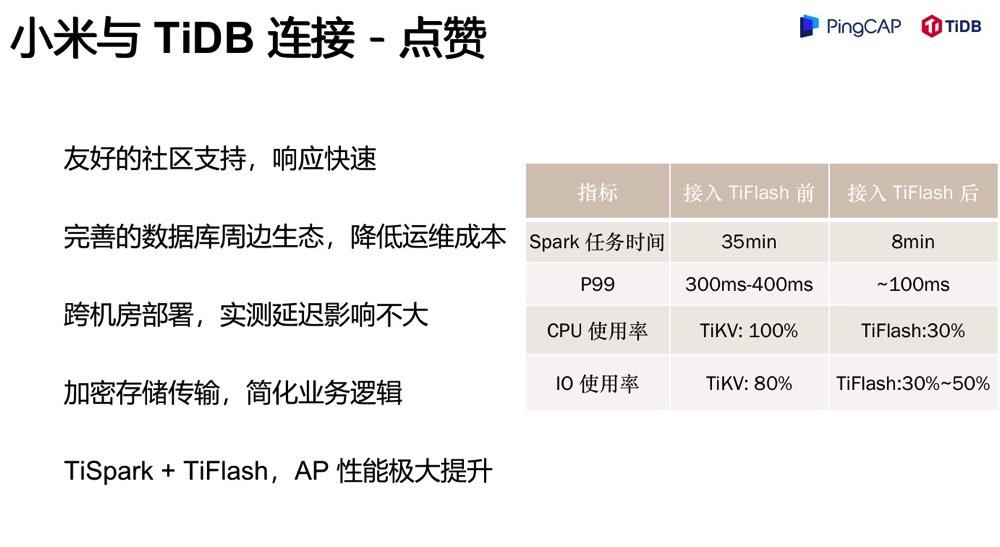
最后是说下 HTAP 的内容。我们内部也有一些 HTAP 的实践,右边这个指标是我们的一个核心业务做的 HTAP 的实践,我们之前通过 TiSpark 打在 TiKV 上的任务时间是在左边,我们换了 TiFlash 之后,我们可以看到,无论是从任务执行时间,还是 P99 延时、负载上,我们都提高了不只三倍。如果我们自己去优化这三倍的性能,需要投入的精力有多少,大家做过性能优化的应该都知道。TiFlash 的引入大大简化了我们的工作。
连接
前面我们提到,TiDB 丰富的生态,极大降低了我们的运维成本。取之社区,回馈社区。包括 TiDB 产品在内,很多生态产品我们都有提 patch。现在,小米团队是多个产品的 contributor,包括 dumpling、br、ticdc、tiup 等,TiDB 产品目前是 active contributor。
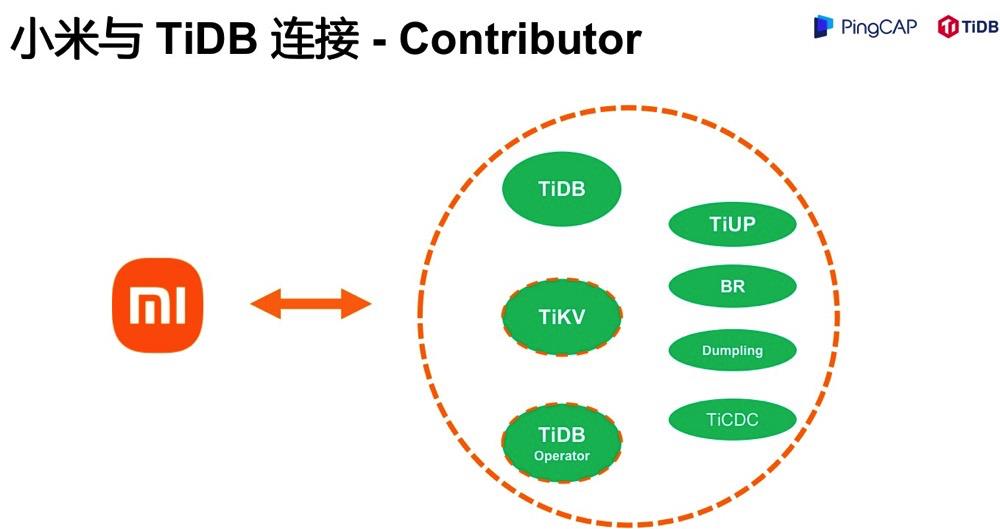
画虚线的产品 TiKV、TiDB Operator,虽然目前还不是 contributor,但是我们和 PingCAP 已经达成合作,后续将持续贡献 TiDB、TiKV、TiDB Operator 产品,同时也是符合我们持续性优化稳定性、性能及成本目标。
我们不仅仅是 DBA,还是研发工程师,都有代码层面了解产品的执拗,当然对生态产品的代码了解也有助于我们落地到业务中,同时反哺社区,帮助完善生态,也是开源社区所倡导的良性循环。
探索


云原生探索踩过一些小坑,这里技术细节比较多了。可以简单介绍一下,假如 PD-pod 假死,Operator 的控制逻辑就会失效。表面上是在 Running 的状态,但其实这个 pod 已经无法提供服务了,这个坑也很难受。还有一些分布式存储的调度问题、故障切换问题造成服务不可用的问题等。另外 Controller 的串行化设计也需要注意。我们知道 Controller 是把你的集群控制在一个期望的状态,但是这个串行化的控制逻辑会让你在扩容 TiDB 的时候,假如 TiDB 扩容不成功,TiKV 也无法扩容成功,这样的话就导致阻塞,导致你整个运维操作的失败。
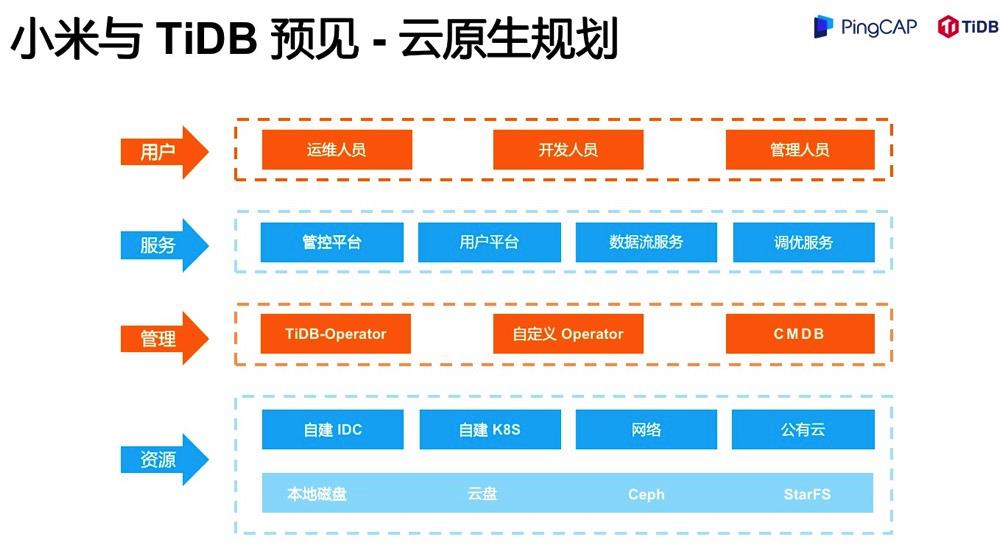
预见
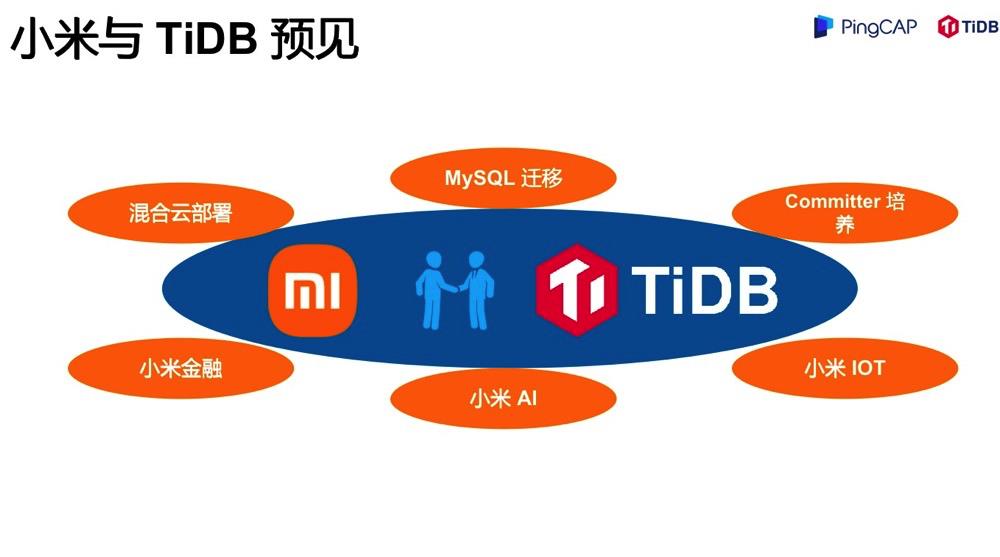
最后表达一下期望,我们已经和 TiDB 社区建立了深度的合作,我们会共同推进混合多云战略,推进核心业务的 MySQL 迁移,以及做一些 Committer 的培养。在内部也会继续推进 TiDB 落地到小米金融、小米 AI、小米 IoT 等多个业务场景。
以上是关于TiDB 在小米的落地及云原生探索丨PingCAP DevCon 2021 回顾的主要内容,如果未能解决你的问题,请参考以下文章