最近面试小心被问 Dubbo3.0!
Posted Java编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最近面试小心被问 Dubbo3.0!相关的知识,希望对你有一定的参考价值。
来自公众号:yes的练级攻略
最近不是 Dubbo3.0 正式发布了嘛,我也推了阿里巴巴中间件发的那篇文章,但是私下还是有小伙伴让我用大白话说说和之前版本到底有哪些不同。
今天这篇就来唠唠。对了,最近面试的小伙伴要小心被问这些新的特性或者版本,面试官用来考察你是不是“紧跟潮流”。
就像之前我写的 ,这种热点很容易在当下被问,特别是当候选人对相关知识点说的头头是道时,有能力的面试官会问你新的版本或者特性,一问三不知,很大程度表明你前面哪些说的就是背的。
关于 Dubbo3 的很多细节我还没深入研究,所以这篇先说说大方向上的东西。
Dubbo3 主基调,云原生
首先什么是云原生 ?
CNCF(云原生计算基金会) 定义如下:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
简单说就是服务上云,然后基于云提供的一些容器、服务网格、不可变基础设施来隐藏分布式架构的复杂度,将一些非业务关键技术下沉,使得复杂的非业务的开发从程序员手中解放出来。
你可能还不是很清晰,我拿应用之间的通信,这个非功能性需求的发展来举个例子:
在最早期的时候通信是和业务耦合在一起的,由业务开发来编写通信和业务代码。
后来就把这些通信相关的代码抽离出来,成为一个公共组件,这样业务开发们不需要编写和维护通信相关代码,只需要调用这个公共组件即可,公共组件由专门的组件开发人员来负责。
但是,虽说我们业务程序员不需要开发这些公共组件,但是使用上还是有成本的,我们需要了解公共组件的一些接口特性,并且引入使用它们。
所以就想着把这些公共组件再剥离出来,使之不与业务应用所处同一个进程,让它对业务完全透明(当然有些还是需要引入轻sdk的),这个其实就叫边车代理。
在原来的车旁边挂个斗,这就是边车啦。
由边车来进行透明可靠的通信,并进行路由、限流、容错等等。
但是呢,如果服务多了边车也会贼多,运维人员肯定顶不住分管这么多边车,所以需要把边车代理统一管理,也就是需要有个代理管理器来管理这些边车,所以就组成了以下这幅图。
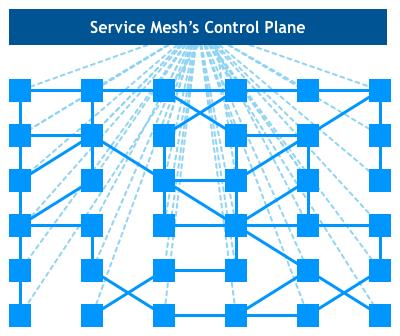
这样的架构其实就是服务网格 (Service Mesh),也称之为微服务3.0版本。
而以上的服务网格功能由云来提供,类似这样的基础能力下沉到云上,我们平日就开发业务,其他的啥都不用管,应用直接扔到云上,便拥有了以往需要自行编程的超多非功能需求的能力,这就是云原生的目的。
至此,想必你已经明白了什么叫云原生,而 Dubbo3 的口号就是全面拥抱云原生,下一代发展的方向呀,必须得跟上!
所以 Dubbo3 主基调就是在不改变之前实践的前提下,遵循云原生的思想,使 Dubbo 能更好的复用云原生所提供的基础能力,抱紧时代的大腿。
让我们来看看 Dubbo3 做了哪些升级吧。
Dubbo 与容器生命周期对齐
有些同学可能对容器、K8S这块不太熟悉,没关系,我就简略讲下,阅读应该没啥障碍。
云原生的发展离不开近年来容器和容器编排的起飞,K8S公认的容器调度平台一哥,而 Dubbo 想要融入云原生,就必须得支持 K8S 的调度。
Pod 的生命周期与服务调度相关,Kubernetes 底层基础设施定义了严格的组件生命周期事件(probe),所以 Dubbo 首先得做到生命周期的对齐。
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元
基于 Dubbo 的 SPI 机制,内部实现了多种探针,基于 Dubbo QOS 运维模块的 HTTP 服务,使容器探针能够获取到应用内对应探针的状态。
大白话说就是通过实现探针让容器知道 Dubbo 现在是否存活着、是否处于就绪状态,还有启动时的检测等,这几个状态是需要被 K8S 知道的,这样 K8S 才可以跟踪容器不同的状态来管理和编排 Pod。
以上的操作,高级点就叫生命周期的对齐咯。
Kubernetes Service
我们都知道 Dubbo 有注册中心,比如用 Zookeeper 来实现。
也就是通过标准的 Kubernetes Service API 定义来进行服务定义与注册,这样把非功能性需求更加下沉了。
Proxyless Mesh
从前文可知,Dubbo 接入 mesh 会有边车的存在,而 Dubbo 框架自身又有一些服务治理的功能,这部分功能和边车会有所重复。
那不好因为这个把以前实现的那些功能砍了吧?
所以就搞了个 Proxyless Mesh,抛弃边车,直接让 Dubbo SDK 与控制面(Control Plane)交互。
当然,也有提供选择接受边车的部署的轻 SDK 模式。
应用级服务发现
之前 Dubbo 的实现是接口级别的服务发现。
比如你现在有个用户服务,用户服务里面有 100 个接口,那么这 100 个接口都会被记录到注册中心里。
假设这个用户服务部署了 100 个实例,那么注册中心就有 100*100 个用户服务接口的记录,这还只是一个服务呢。
所以成百上千个服务过来,这元数据就会膨胀的夸张,注册中心和客户端的内存压力就很大,所以这样的实现在大规模微服务架构体系下,是有瓶颈的。
所以把服务发现从接口级别改为应用级别,这样可以大大降低内存的占用。

上图表示接口规模在平均场景和极限场景下,把服务发现粒度从接口改为应用级别,分别有 60% 和 90% 的内存优化。
并且像 Spring Cloud 和 K8s 都是基于应用级别的注册发现,所以想要支持异构连接,就必须支持应用级别分服务发现。
所以 3.0 版本是这样实现的:
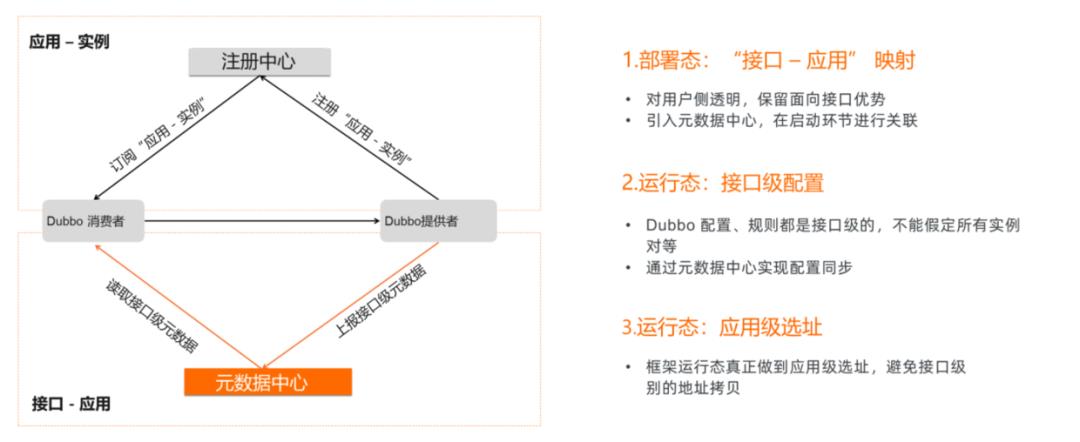
让注册中心只保存应用-实例的关系,接口级别的元数据弄了个元数据中心。
Triple协议
看到这个我在想,之后是不是就是 quadra,然后再 penta kill ?哈哈。
言归正传,Dubbo2.0 协议在云原生时代来说,不够通用。
协议头没有足够的空间容纳Mesh等网关组件(网关需要识别)。
如果要实现,就必须完整的解析协议才能获取到所需要的调用元数据,这样性能不佳。
并且生态之间不互通,别人不好解析你自定义的二进制协议,简单来说就是不够通用,其他生态也没有想法来适配一个 RPC 框架。
所以 Dubbo 3.0 选择了 HTTP2 + Protocol Buffer 的形式来实现新的协议——Triple,也基于此丰富了请求模型,除了 Request/Response 模型,还支持 Streaming 和 Bidirectional(双向流式通信),适配了更多的场景。
最后
总结一下3.0关键几点:
-
借助SPI实现相关探针,使得生命周期可以被容器感知,即生命周期与容器对齐。 -
接入 Kubernetes Service API,使得注册中心相关功能下沉,而不用额外利用ZK等第三方注册中心。 -
将接口级别的服务发现改成应用级别,解决了大规模微服务架构体系下,元数据膨胀的瓶颈,并对其市面常见的发现级别,便于异构的实现。 -
升级通信协议为Triple,选择了 HTTP2 + Protocol Buffer 的形式,丰富了请求模型。
暂时分享到这里啦,大致过了一遍,里面很多细节我还没深入研究,等我之后研究过了再出一篇细节点的。
不过,这篇虽说是粗略过一遍,但是前置知识点还是很多的,比如容器、K8S、HTTP2、Protocol Buffer等等。
这些东西不清楚,估计 get 不到上面 Dubbo3.0 的这些点。
而且这些东西又不是三两句话能说清的,所以对前置知识点不清晰的小伙伴建议去查查资料,这些还是很重要的。
之后有时间我会写写相关的。
如果你碰上有水平的面试官,很容易问这类新特性的问题,因为他们是在一直关注着前线的,当然这也不是决定性因素,只是能答出来会比较加分~
参考:
-
https://dubbo.apache.org/zh/docs/v3.0/ -
https://mp.weixin.qq.com/s/5loawrCyKmN4HhK1lzy0Rw -
https://www.cnblogs.com/alisystemsoftware/p/13559704.html
我是yes,从一点点到亿点点,我们下篇见。
以上是关于最近面试小心被问 Dubbo3.0!的主要内容,如果未能解决你的问题,请参考以下文章