二叉树常有,三叉数有木有呢?
Posted B座17楼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉树常有,三叉数有木有呢?相关的知识,希望对你有一定的参考价值。
内心cosplay:两条腿的人常见,三条腿的蛤蟆少有?
有兴趣的童鞋可以翻开之前大喵历史文章。讲述如何制定一条最省钱的高铁出行路线,满足几个边界条件:
1、游遍线路规划的目的地城市,而且只经过一次。
2、最关键是次序,目的地城市先后抵达的次序最优方案:高铁票价总和最低。
正如上面高铁站点映射为图论节点Tries的连通性表达,数据结构选择字典似乎完美,但这还并不是最优。
因为二叉树很好,但并不完美,并允许进一步改进。在这篇文章中,我们将重点讨论它们的一个变种--三元搜索树,它以搜索性能换取存储节点子节点的更高内存效率。
mlarocca / AlgorithmsAndDataStructuresInAction
高级数据结构的实现
Tries有什么问题?
Tries为许多基于字符串的操作提供了极好的性能。但由于它们的结构,它们要为每个节点存储一个子节点数组(或一个字典)。很快就会变得很昂贵:一个有n个元素的trie的边的总数可以在|∑|*n和|∑|*n*m之间任意摆动,其中m是平均字长,取决于常见前缀的重叠程度。
我们可以在节点的实现中使用关联数组,特别是字典,从而只存储非空的边。例如,我们可以从一个小的哈希表开始,并随着我们添加更多的键而增长它。但是,当然,这种解决方案是有成本的:不仅是访问每条边的成本(这可能是散列字符的成本,加上解决密钥冲突的成本),还有在增加新边时调整字典大小的成本。
此外,任何数据结构都有它所需要的内存开销:在Java中,每个空的HashMap需要大约36个字节,加上每个条目存储的大约32个字节(不考虑每个键/值的实际存储),再加上4个字节的集合容量。
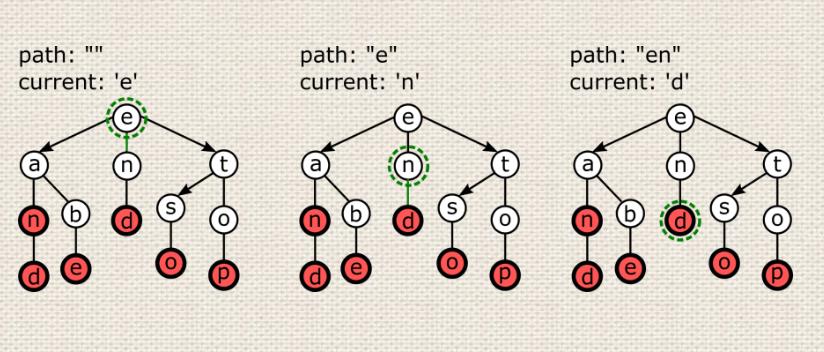
一个可以帮助我们减少与尝试节点相关的空间开销的替代解决方案是三元搜索三角(TST)看看一个TST的例子,存储了以下单词。
["an", "and", "anti", "end", "so", "top", "tor"]
只有填充的(红色)节点是 "关键节点",对应存储在树上的词,而空(白色)顶点只是内部节点。
与tries类似,TST中的节点也需要存储一个布尔值,以标记关键节点。
你可以发现,相对于三叉戟而言,第一个区别是TST在节点中存储字符,而不是在边上。
事实上,每个TST节点正好存储了三条边:通往左、右和中间的孩子。
这个名字中的 "三元搜索 "部分应该有印象,对吗?事实上,TST的工作方式在某种程度上与BST类似,
只是有三个链接而不是两个。这是因为它们将一个字符与每个节点联系起来,在遍历树的过程中,我们将根据输入字符串中的下一个字符与当前节点的字符的比较情况来选择探索哪个分支。
与BST类似,在TST中,一个节点N的三条出线划分了其子树中的键;如果N,持有字符c,其在树中的前缀(从TST的根到N的中间节点路径,我们将看到)是字符串s,那么以下不变量成立。
所有存储在N的左子树中的键sL以s开头,比s长(以字符数计),并且在词典上小于s+c:sL < s+c(或者,换一种说法,sL的下一个字符在词典上小于c:如果|s|=m,sL[m] < c)。
所有存储在N的右子树中的键sR以s开始,比s长,并且在词典上大于s+c:sR>s+c。
这一点最好用一个例子来说明:看看上面的图形,并试着为每个节点计算出可以存储在其3个分支中的子字符串的集合。
左边的分支包含所有在词法排序中第一个字符在'e'之前的键:因此,只考虑英文字母中的小写字母,'a'、'b'、'c'、'd'中的一个。
最后是右边的分支,它包含所有以'f'到'z'字母开头的键。
当我们遍历一个TST时,我们跟踪一个 "搜索字符串",就像我们对tries所做的那样:对于每个节点N,它是可以存储在N中的字符串,它是由从根到N的路径决定的。
从上面的例子可以看出,TST的一个特殊性是,一个节点的子节点有不同的含义/功能。
中间的子节点是在字符匹配时跟随的。它将一个节点N(其路径从根部形成字符串s)连接到一个包含所有以s开头的存储键的子树。
而一个节点的左边和右边的子节点,则不会让我们的路径前进。如果我们在从根到N的路径中找到了i个字符(即在从根到N的遍历过程中我们遵循了i个中间链接),而我们遍历了一个左边或右边的链接,当前搜索字符串的长度仍为i。
上面你可以看到一个例子,说明当我们跟踪一个右边的链接时会发生什么。
与中间链接不同的是,我们不能更新搜索字符串,所以如果在左半边的当前节点对应于 "和 "字,在右半边的突出显示的节点,其字符是't',对应于 "ant":
注意,没有穿越前一个节点的痕迹,持有'd'(因为也没有根节点的痕迹,就像我们没有穿过它,因为我们的路径已经穿越了一个从根到当前节点的左边链接)。
左右链接,换句话说,对应于一个共同的前缀之后的分支点:例如,对于 "ant "和 "and",在前两个字符之后(在同一路径中只能存储一次),我们将需要进行分支,以存储两个备选方案。
哪一个得到中间的链接,哪一个得到左边或右边的链接?这不是事先确定的,只取决于它们被插入的顺序:先到先得!"。
在上图中,
"and
"显然被存储在
"anti "
之前。
好吧,TSTs看起来是tries的一个很酷的替代品,但是对于学习和实现一个新的数据结构来说,它的用例和我们工具箱中另一个已经测试过的、工作正常的数据结构一样,是不够的,对吗?所以,我们应该多谈谈为什么我们可能想选择TST。
那么,现在问题来了:这样的TST要创建多少个链接(和节点)?
为了回答这个问题,假设我们要存储n个平均长度为w的钥匙。
我们需要的最小链接数将是w+n-2:这是当所有的词共享一个长度为w-1的前缀时,我们有一个从根部开始的|w-2|字符(和|w-1|节点)的中间节点路径,然后我们将在最后一个字符处分支n次(正好有一个中间链接,加上n-1个左/右链接)。这种边缘情况的一个例子如下图所示,n=5,w=4。
最坏的情况发生在没有两个词有共同的前缀时,我们需要在根部进行分支,然后对于每个词我们会有w-2个中间链接,总共有n*(w-1)个链接。如下图所示,n=5,w~=4。
现在我们对如何建立这些树有了一个概念,在下一节,我们将仔细看看搜索。
所有其他的操作都可以用同样的方式从tries中派生出来,并且可以从成功/不成功的搜索开始实现,或者稍微修改一下搜索。
从性能上讲,一个搜索命中或一个搜索失误,在最坏的情况下,需要穿越从根到叶的最长路径(没有回溯,所以最长的路径是对最坏情况下的成本的可靠衡量)。
这意味着搜索最多可以进行|A| * m个字符的比较(对于完全倾斜的树),其中|A|是字母表的大小,m是搜索的字符串的长度。由于字母表的大小是一个常数,我们可以认为对于长度为m的字符串来说,成功搜索所需的时间是O(m),而且只与三角形的同源物有一个常数的差异。
同样可以证明的是,对于一个存储n个键的平衡TST,搜索失误最多需要O(log n)个字符的比较(这与大的字母表有关,如果|A| * m > n)。
对于删除:它可以作为一个成功的搜索,然后进行一些维护(在回溯过程中进行,它不影响渐近分析),因此它的运行时间在最好的情况下也是O(m),而对于不成功的删除则是摊销的O(log(n))。
最后补充一点:这也是一次搜索(无论成功与否),然后创建一个最多有m个节点的节点链。那么,其运行时间也是O(|A|*m)。
TSTs是tries的有效替代方案,在运行时间上以稍差的常数换取有效的内存节省。
两者都遵循相同的接口,并允许有效地实现一些有趣的字符串集的搜索。
然而,TST的实现方式允许在内存(可能比存储相同字符串集的trie所需的内存少得多)和速度之间进行权衡,这两种数据结构都有渐进行为,但TST比tries慢一个恒定系数。
在本系列的下一篇文章中,我们将谈论TSTs的Java实现,所以请继续关注,因为最有趣的材料还在后面。
以上是关于二叉树常有,三叉数有木有呢?的主要内容,如果未能解决你的问题,请参考以下文章