Hadoop怎么了,大数据路在何方?
Posted 数据仓库与Python大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop怎么了,大数据路在何方?相关的知识,希望对你有一定的参考价值。
导读:近期Hadoop消息不断,众说纷纭。本文以Hadoop的盛衰变化为楔子聊下大数据分析的发展现状和未来趋势。

00 15秒钟简缩版
-
巅峰已过,正在成为遗留系统 -
Hadoop和分布式数据库在同一个赛道上,Hadoop在这个赛道上目前并无优势
-
大数据市场是 SQL市场,是分布式数据库市场 -
基础分析如BI、交互查询等技术已经成熟 -
高级分析(机器学习)下沉,向数据库内嵌分析方向发展 -
高级分析(机器学习)主要问题不在分析而在数据本身
01 Hadoop 巅峰已过几多年,正在成为遗留系统
-
Hadoop 栈过于复杂,组件众多,集成困难,玩转代价过高 -
Hadoop 创新速度不够(或者说起点过低),且缺乏统一的理念和管控,使得其众多组件之间的集成非常复杂 -
受到Cloud技术的冲击,特别是类S3对象存储提供了比HDFS更廉价、更易用、更可伸缩的存储,撬动了Hadoop的根基HDFS -
对 Hadoop 期望过高,Hadoop发迹于廉价存储和批处理,而人们期望Hadoop搞定大数据所有问题,期望不匹配造成满意度很低 -
人才昂贵,且人才匮乏
-
Hadoop还有没有前途?Hadoop发展历史和未来方向解读 -
Hadoop 气数已尽:逃离复杂性,拥抱云计算 -
超越云计算:对数据库管理系统未来的思考 -
Big Data Is Still Hard. Here’s Why -
Big Data Will Get By (but> Cloudera and Hortonworks merger means Hadoop’s influence is declining -
From data ingestion to insight prediction: Google Cloud smart analytics accelerates your business transformation -
Hadoop is Dead. Long live Hadoop (中文翻译:Hadoop已死,Hadoop万岁) -
Hadoop Has Failed Us, Tech Experts Say -
Hadoop Past, Present, and Future -
Hadoop: Past, present and future(又一个) -
Hadoop runs out of gas -
Hadoop Struggles and BI Deals: What’s Going On? -
Hitting the Reset Button> Is Hadoop officially dead -
Mike Olson> More turbulence is coming to the big-data analytics market in 2019 -
Object and Scale-Out File Systems Fill Hadoop Storage Void -
The Decline of HADOOP and Ushering An Era of Cloud -
The elephant’s dilemma: What does the future of databases really look like? -
The Future of Database Management Systems is Cloud! -
The history of Hadoop -
Why is Hadoop dying?

The old way of thinking about Hadoop is dead — done, and dusted. Hadoop as a philosophy to drive an ever-evolving ecosystem of open source technologies and open data standards that empower people to turn data into insights is alive and enduring.
译文:你所认为的传统的Hadoop已经死了,确实如此。但Hadoop作为一门哲学,推动不断发展的开源技术生态系统和开放数据标准,使人们能够将数据转化为洞察力,这门哲学是充满活力和持久的。
——Arun C Murthy
02 Hadoop 市场是数据仓库市场,然而在这个市场里目前并不占优势
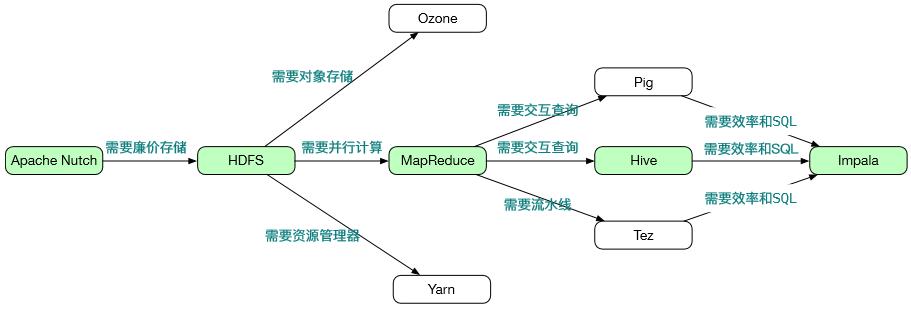
-
Apache Nutch是Hadoop一哥Doug Cutting 写的开源网页爬虫。为了存储海量网页,Nutch需要一个分布式存储层。受Google GFS论文的启发,Doug 设计了一个开源GFS实现,成为后来的 HDFS。相比于当时昂贵的磁盘阵列和SAN,HDFS提供了廉价、高可靠且可扩展的存储;
-
分布式存储层解决后,Nutch需要能适应分布式环境的并行计算模型。受Google MapReduce 论文的启发,Doug 设计了开源版的MapReduce。HDFS和MapReduce解决了大数据的存储和计算问题,受到当时受困于大数据问题的大型互联网公司的追捧,很快 Hadoop 吸引了大量的开发者,成为 Apache 顶级项目; -
Hadoop解决了有无问题。很快人们发现MapReduce复杂度很高,即使技术实力强大如Facebook都很难写出高效正确的MapReduce程序。此外除了解决批处理问题,人们需要Hadoop能解决其遇到的交互式查询任务。为此,Facebook 开发了Hive,该项目快速流行起来,到现在还有很多用户。Facebook当时更是高达95%的用户使用Hive而不是裸写MapReduce程序。 -
由于Hadoop 不是为交互式处理而设计,Hive 效率低,并发度也低。此外Hive不支持标准SQL,使得和其他产品的集成困难重重。为此Cloudera开发了Impala。Impala 实际上是一款分布式 MPP(大规模并行处理) 数据库。
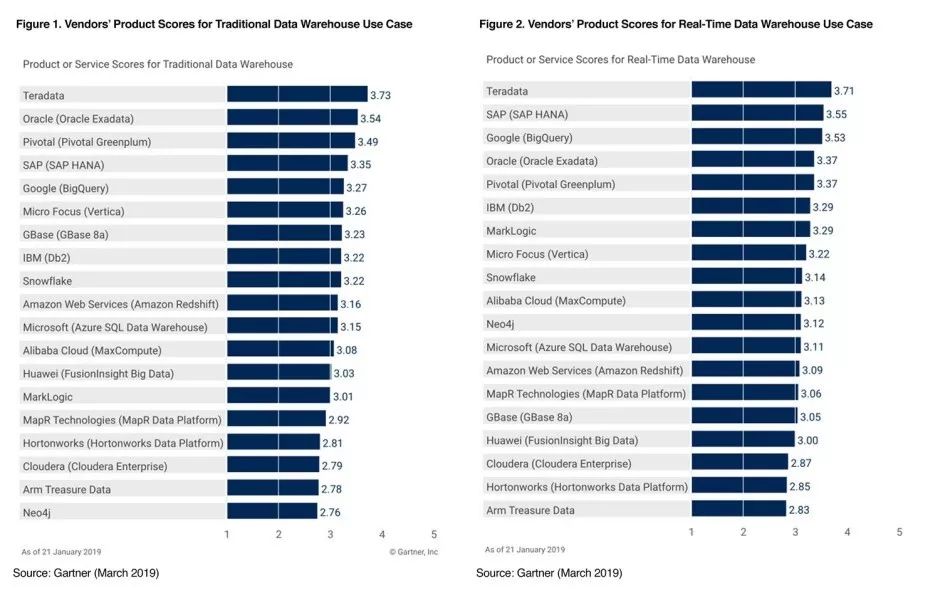
For several years now, Cloudera has stopped marketing itself as a Hadoop company, but instead as an enterprise data company.
03 大数据分析市场当前是 SQL 市场

04 高级数据分析之难点不在分析而在数据本身
05 总结


还想看点啥?
戳戳戳!!!
2.
3.
4.
5.
6. 实践 |
7.

截图仅为文章部分示例

学习小密圈 限50人
Q: 关于数据治理,你还想了解什么?
更多精彩,请戳"阅读原文"到"大厂案例"查看
!关注不迷路~ 各种福利、资源定期分享!
以上是关于Hadoop怎么了,大数据路在何方?的主要内容,如果未能解决你的问题,请参考以下文章