云原生AI平台的加速与实践
Posted 容器魔方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生AI平台的加速与实践相关的知识,希望对你有一定的参考价值。
前言:12月19日,在 Cloud Native Days China -云原生AI大数据专场,腾讯技术事业群高级工程师薛磊发表了《云原生AI平台的加速与实践》主题演讲。
演讲主要包含五部分的内容:
Kubernetes介绍
AI离线计算
AI场景下Kubernetes的不足
Kubeflow
-
星辰算力平台的架构
Kubernetes介绍
K8s是生产级的容器编排系统,它也是云原生应用最佳的一个平台,它的特点主要包括可移植性、可扩展性以及自我修复,可以自动部署,自动故障恢复,自动扩展。
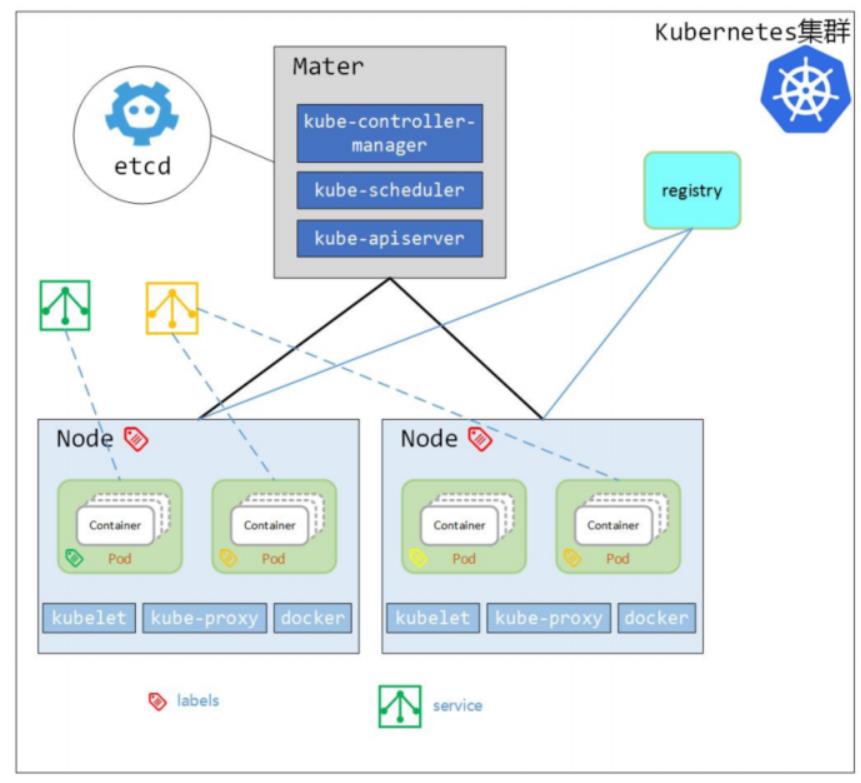
K8s通过多个组件完成了整个平台的构建,主要包含的角色有Mater节点、Node节点,Master节点包含control manager、调度器、apiserver以及etcd等,节点上面包含了容器kubelet。每个组件提供了单独的能力,所有的组件我们可以认为是与apiserver通信,发现自己的工作,并且做一些额外的修改,然后提交到apiserver。所以它整个的框架是即插即用的,并且具有良好的扩展性。因此,对于我们而言在AI平台上面也可以基于K8s的架构进行额外的开发。
AI离线计算

典型的AI场景
典型的AI计算框架
1)Tensorflow
TensorFlow 是由 Google Brain 团队为深度神经网络(DNN)开发的功能强大的开源软件库,于 2015 年 11 月首次发布,在 Apache 2.x 协议许可下可用。
有非常好的社区支持,在Github社区中非常活跃。
支持所有流行语言,如 Python、C++、Java、R和Go
可以在多种平台上工作,甚至是移动平台和分布式平台
-
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。 -
2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:
a. 具有强大的GPU加速的张量计算(如NumPy)
b. 包含自动求导系统的深度神经网络
分布式AI计算
为什么要分布式AI计算?
将单机变成多机,分布式训练提高训练速度
拆分数据集
典型的分布式AI计算的架构:
TensorFlow PS-Worker
Horovod
两种方式的异同:
1)分布式AI计算框架:TensorFlow PS-Worker
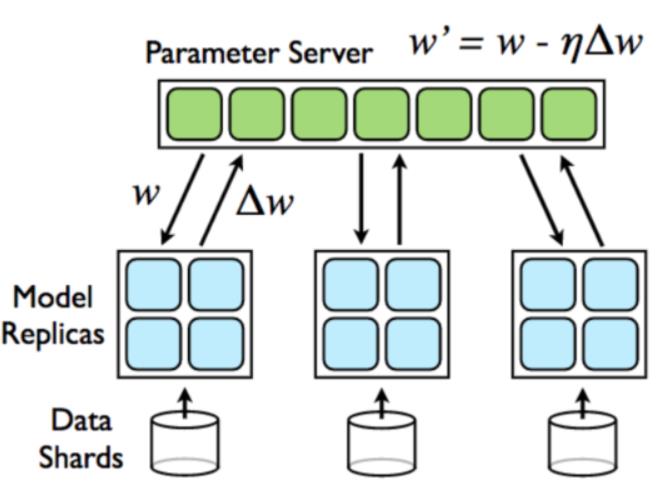
-
参数服务器Parameter Server和工作节点(简称为 worker)代表两种不同的工作类型; -
不同领域的训练任务对 Parameter Server和 worker 有不同的需求,这体现在 Kubernetes 中就是配置难的问题; -
以 TensorFlow 为例,TensorFlow 的分布 式学习任务通常会启动多个 PS 和多个worker,而且在 TensorFlow 提供的最佳实 践中,每个 worker 和Parameter Server 要求传入不同的命令行参数;
2)分布式AI计算框架:Horovod
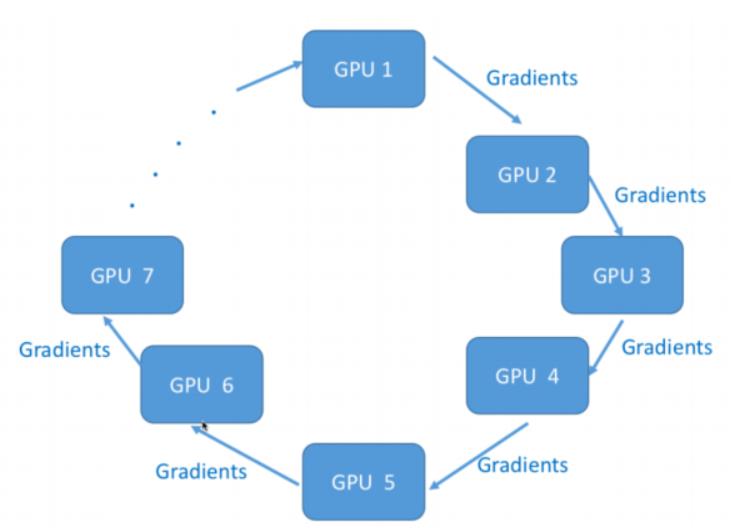
-
Horovod 是 Uber 开源的针对TensorFlow 的分布 式深度学习框架,旨在使分布式深度学习更快速,更 易于使用。 -
Horovod 吸取了 Facebook 的 Training ImageNet in 1 Hour(一小时训练 ImageNet) 论文与百 度 Ring Allreduce 的优点,为用户实现分布式训练 提供帮助。该项目主要是想能够轻松采用单个 GPU TensorFlow 程序,同时也能更快地在多个 GPU 上 成功地对其进行训练。
AI 场景下Kubernetes的不足
AI场景下K8s局限性 – 多机训练管理
多机训练任务创建
MPI任务如何管理生命周期、配置训练参数以及 环境
TensorFlow任务如何设置端口、角色以及环境
多机训练任务生命周期管理
部分节点故障,容错与否
训练出错或结束任务状态管理
AI场景下K8s局限性 – 调度
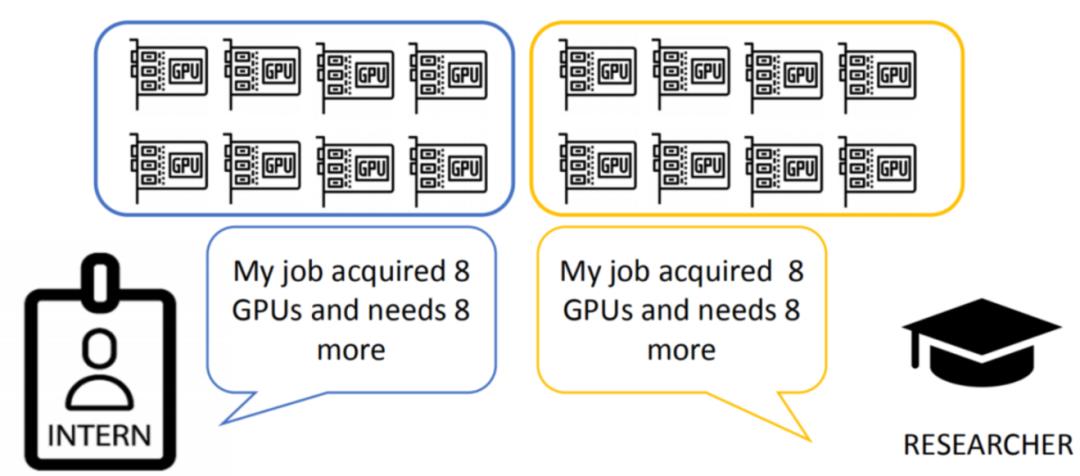
Defros无法进行批量调度,但在多机的场景下,是需要多机调度的。比如上图左边是一个实习生,右边是一个研发人员,他们各自需要16张卡,也就是两台机器16张卡去完成一个训练任务,该怎么办?
他们可能在某一个时间点同时下发一个任务,并且下发的任务转化后为两个pod,每个pod都是8张GPU卡,他们可能遇到场景是各自都有一个pod被调度,但是另外一个pod没有被调度成功,导致饿死的状况。这虽然是一个比较极端的资源情况,但如果存在就会导致各自都无法释放,只能等各自超时的一段时间,再重新下发。但如果他们又同时下发,可能会一直死锁在这里,这是K8s目前无法解决的。
Kubeflow
Kubeflow可以很好的管理多机任务,Kubeflow的名字比较简单,为Kubernetes + TensorFlow,是一个机器学习工具包,是运行在K8s之上的一套技术栈,这套技术栈包含了很多组件,组件之间的关系比较松散,我们可以配合起来用,也可以单独用其中的一部分。
Kubeflow组件
Kubeflow提供了众多组件,涵盖了机器学习的方方面面:
-
Central Dashboard:Kubeflow的dashboard看板页面 -
Metadata:用于跟踪各数据集、作业与模型 -
Jupyter Notebooks:一个交互式业务IDE编码环境 -
Frameworks for Training:支持的ML框架
a. TensorFlow
b. Horovod/MPI
c. MXNet
d. PyTorch
Hyperparameter Tuning:Katib,超参数服务器
Pipelines:一个ML的工作流组件,用于定义复杂的ML工作流
Tools for Serving:提供在上对机器学习模型的部署
常用的Operator
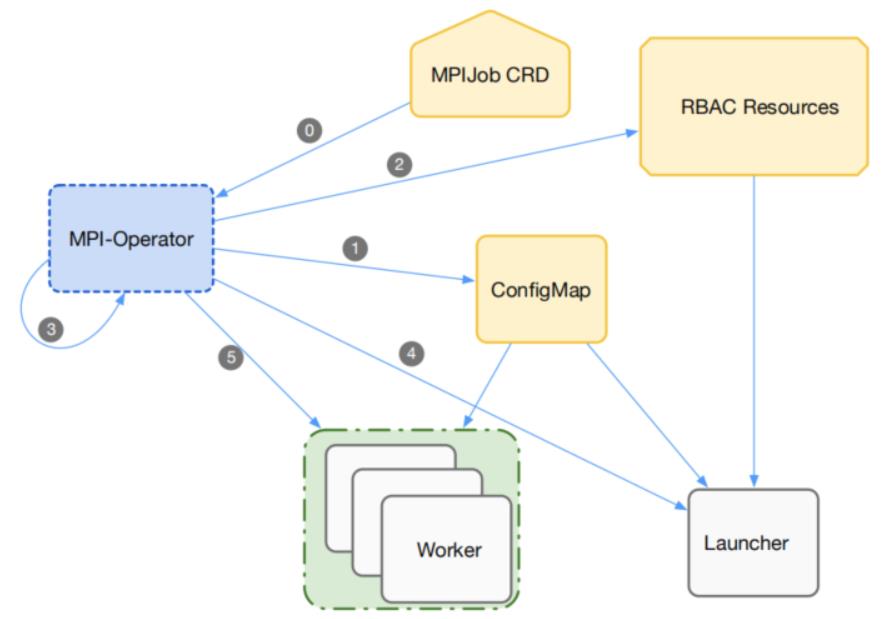
1)Kubeflow – MPI-operator
-
为Horovod/MPI多机训练准备的Operator -
多机任务分为多种角色
a. Launcher
b. Worker-N
每个任务通过特定的RBAC
每个任务会设置rsh_agent以及hostfile
Launcher中init-container会等worker就位后
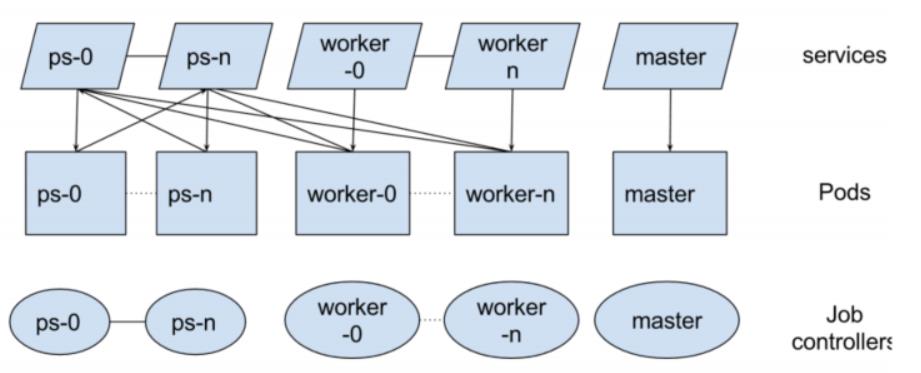
2)Kubeflow – TF-Operator
-
提供TensorFlow原生PS-worker架构 的多机训练 -
推荐将PS和worker一起启动 -
通过service做服务发现 -
在社区中最早期的Operator
星辰算力平台的架构
它为私有云的一个离线计算平台,我们大概托管几万张计算卡,包含多个集群,功能注意有异地多集群统一管理、公司内多租户隔离、高低优混合调度,来保证闲时的资源被充分利用以及高效的启停技术和共享存储。
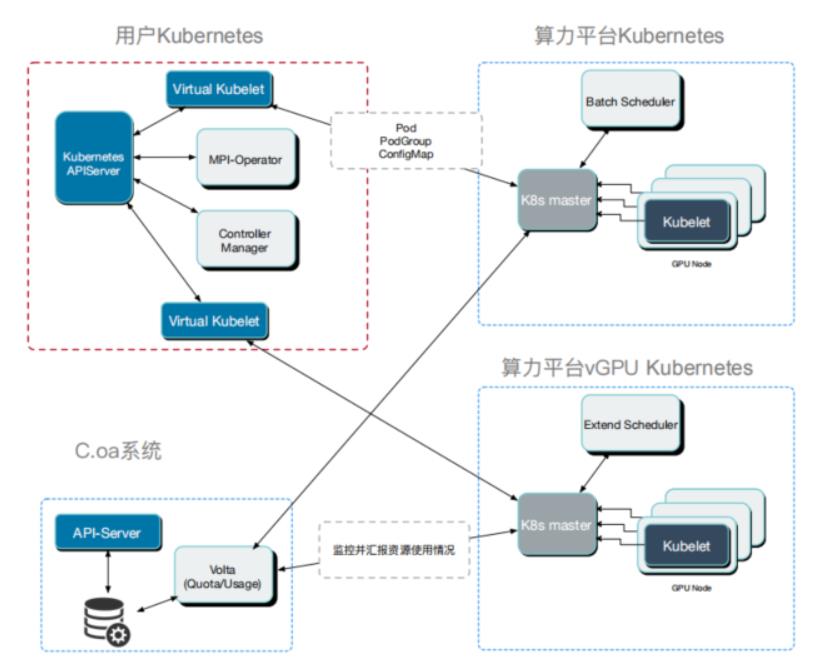
流程图
-
通过Virtual-Kubelet将多个地域的Kubernetes集群联邦到一个集群,作为虚拟节点 -
底层集群支持批量调度 -
依托于tkestack的vcuda技术支持GPU虚拟化 -
用户的管理controller/operator部署在用户Kubernetes集群管理资源对象
星辰算力平台架构——Virtual Kubelet
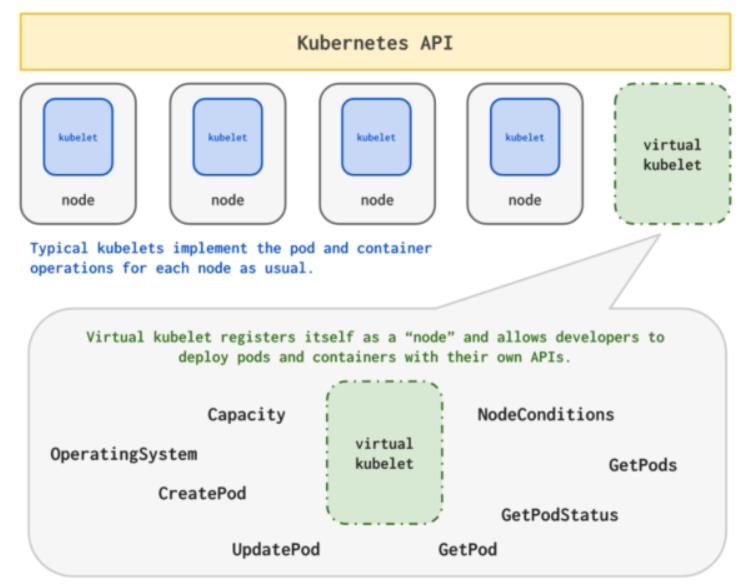
由于它本身的定位,因此只提供给了几种简单的接口,比如:
Pod相关的增删改查操作
Pod/容器的logs/exec接口
节点状态汇报
我们将其扩展应用到多集群的场景,也就是将两个集群级联到一 起,这一创新性的做法也是来自于GPU算力平台团队,扩展了上面简单的接口到如下资源:
ConfigMap
Secret
ServiceAccount
算力集群调度器
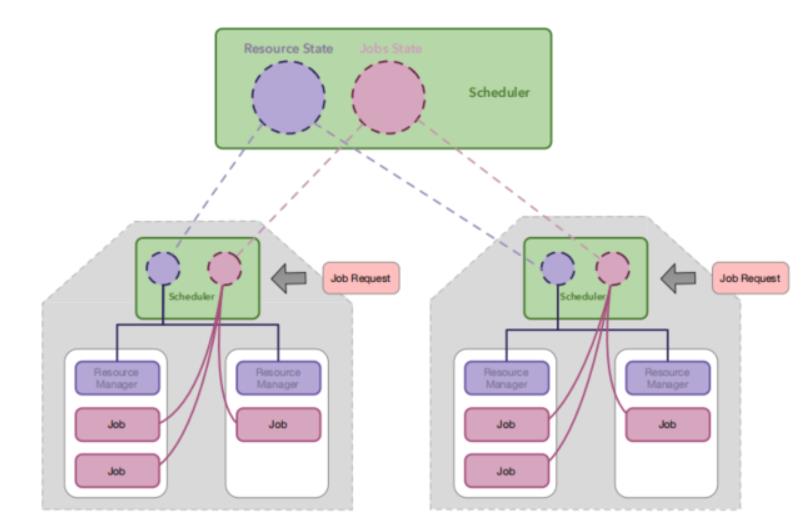
-
用户集群作为一级调度,保证选择合适的集群,也即Virtual-Kubelet对应的虚拟节点 -
转发到底层算力集群调度器,进行高效调度
AI场景下K8s局限性 – 调度
整体的架构是上层用于选集群,下层完成真正的批量调度工作。那么如何去支持批量调度来避免上面提到饿死的情况,我们引入了Volcano。
Volcano能满足我们的需求有:
1)批量调度
多个Pod从属于同一个任务
保证调度或不调度
防止饿死场景
2) 任务优先级
高低优任务区别
高优任务保证启动时延
低优弹性任务不占额度
3)优化
拓扑调度
Binpack——减少碎片
Image位置优先调度
使用了这种批量调度器后,比如上文提到的实习生和researcher,如果researcher的优先级比较高,他可以优先去调度,用16张GPU跑整体的任务。当他跑完之后,可以很顺利的释放这16张卡。然后实习生就可以跑他的16张卡的任务,来完成整个的训练。
节点优化
Nvidia-docker
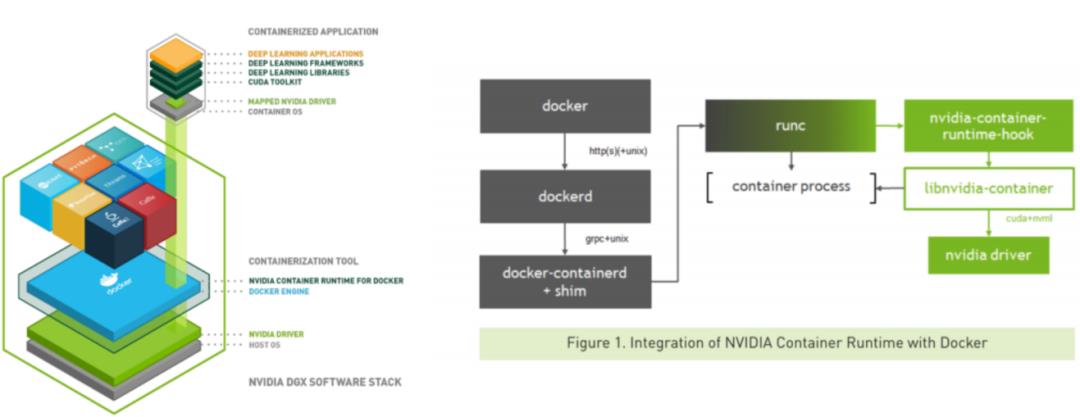
我们在做AI离线计算时,会用到Nvidia-docker,如果用Nvidia-docker,无外乎用如上图两种。简单来说,我们在运行的过程中,首先是给一个环境变量,用这个环境变量去查询,环境变量包含的可能是GPU ID,也有其他的字符串,有了字符串,就可以去查询驱动或者信息,查询完成后,将driver mount到容器里,完成这个部分的操作。
启动速度优化
固定GPU 驱动以及CUDA相关配置
减少nvidia-docker启动时查询次数
提升Nvidia-docker的启动时间在40-50%,是在我们的环境下用v100测出来的效果。
节点GPU拓扑调度
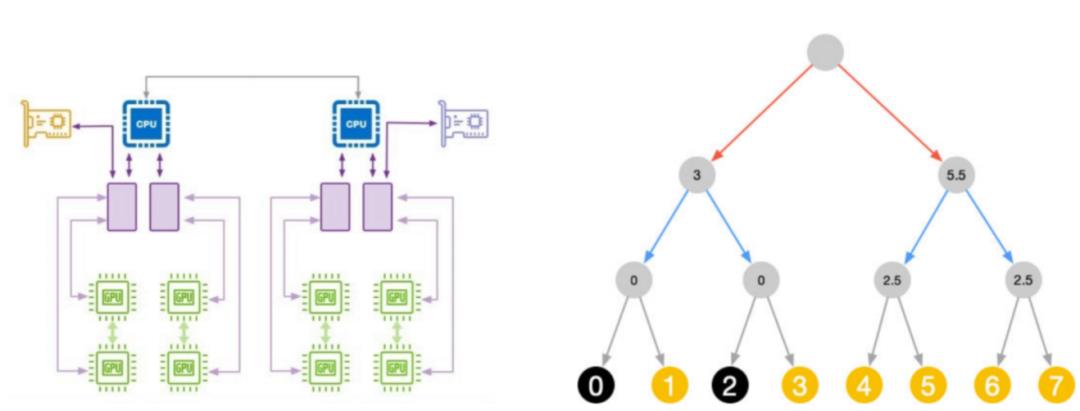
未来:AI System
AI System最近两年非常火,System for AI非常有特点,比如上文的场景特点、多机特点等。那基于这些特点,传统的软件架构是否可以满足我们的要求或者高效的满足我们的要求 ? 其实也有很多人去改进我们的软件,比如通信优化,在多级通信时,它构建的通信算法,无论是ps worker还是其他,我们可以基于一些通信硬件,去完成整个的通信优化以及我们如何针对以太网,去优化我们的通信算法,都是很多人关注的方向。
另外还有存储优化,我们在做 AI的过程中发现,其实一个很痛点的问题不是GPU的算力不够,而是其他的软件的能力不够,其他的软件能力主要集中在存储上面。比如在视觉领域更多是海量的小文件,像人脸的图片大概是几KB,几亿的这种级别,那如何进行共享存储以及构建一个存储系统去承载这些离线计算或这种深度学习,也是一个非常典型的方向,当存储的能力足够供给GPU的这种算力时,其实我们就要考虑更深层次的问题,可能是调度层面的优化。
另外一个非常大的方面为AI For System,我们有很多现成的调度器,Volcano里面可能是一些写好的策略,那么这些策略是否可以优化,怎么去优化?是否可以用AI优化这个问题?当然业界也探讨很多,但可能没有一个最好的方案,是否我们可以考虑往这方向去探索,这可能是 AI是无法解释的,但如果用AI应用到各个领域,也可能会有意想不到的收获。以上为我的一些看法,也欢迎大家探讨!

推荐阅读
戳阅读原文,观看演讲视频!
以上是关于云原生AI平台的加速与实践的主要内容,如果未能解决你的问题,请参考以下文章