机器学习之Kd树-DBSCAN聚类算法概述
Posted 51Testing软件测试网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之Kd树-DBSCAN聚类算法概述相关的知识,希望对你有一定的参考价值。
出品|51Testing软件测试网
机器学习中各式各样的聚类算法层出不穷,包括层次聚类、系统聚类、K中心聚类、DBSCAN聚类等等。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,它最大的优点是能够把具有足够高密度的区域划分为簇,并在具有噪声的空间中发现任意形状的聚类,因而被广泛应用。
传统DBSCAN聚类算法采用穷举搜索进行数据的划分,通过在聚类过程中多次遍历待划分数据得到划分结果。这种算法称为蛮力算法,时间复杂度达到了O(n2),数据量较少时可以在较短时间内完成数据划分。
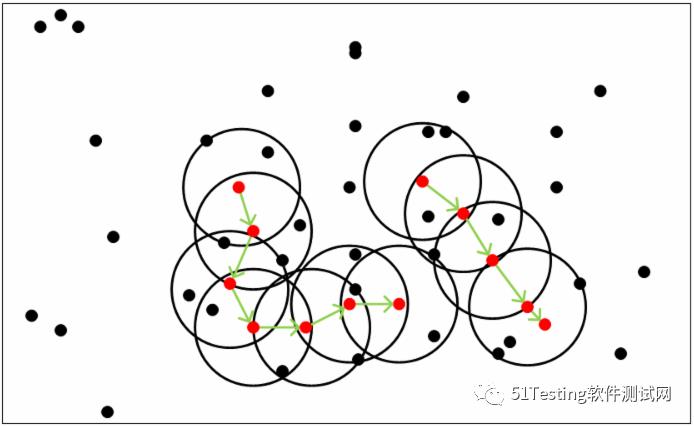
Kd-树是K-dimension tree的缩写,是对数据点在k维空间划分的一种数据结构,主要应用于多维空间关键数据的搜索。
本质上说,Kd-树就是一种平衡二叉树。所以它的增加、删除、查询时间复杂度都是O(logn)。
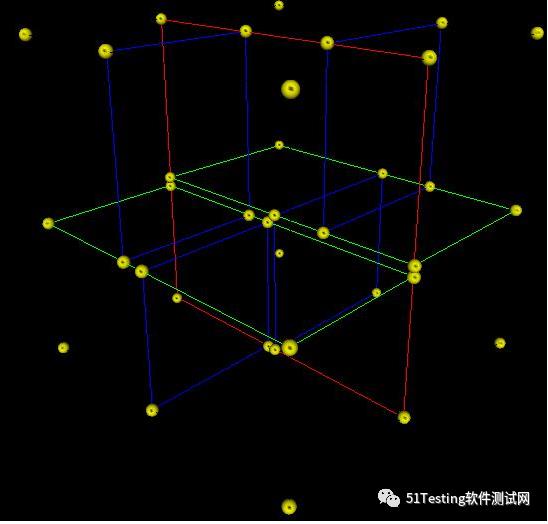
首先必须搞清楚的是,kd-树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。
想像一个三维空间,kd-树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:
为了解决传统DBSCAN聚类算法的低效率问题,我们将Kd-树数据结构与该算法相结合,在进行聚类之前,先对待聚类数据创建Kd-树,使用空间搜索算法更高效地进行数据划分。
整个数据划分流程图如下图示:
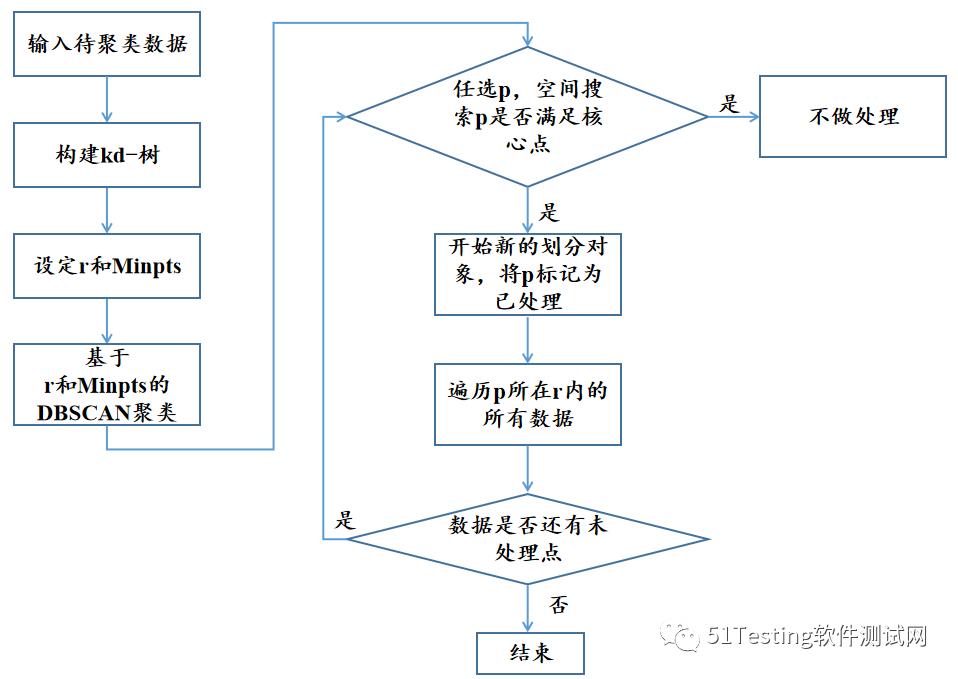
通过流程图我们可以知道,Kd-树DBSCAN聚类算法会首先对待聚类数据创建kd-树,然后通过空间搜索算法检查数据中每点的r邻域来搜索簇。
如果点p的r邻域包含的点多于MinPts,则创建一个以p为核心对象的新簇。通过迭代的聚集从这些核心对象直接密度可达的对象来达到数据划分的目的。
当没有新的数据点可以添加到任何簇时,算法结束。
Kd-树创建伪代码:
kdtree (list of points pointList, int depth){// Select axis based on depth so that axis cycles through all valid valuesvar int axis := depth mod k;// Sort point list and choose median as pivot elementselect median by axis from pointList;// Create node and construct subtreesvar tree_node node;node.location := median;node.leftChild := kdtree(points in pointList before median, depth+1);node.rightChild := kdtree(points in pointList after median, depth+1);return node;}
(左右滑动查看完整代码)
DBSCAN聚类算法伪代码:
DBSCAN(D, eps, MinPts)C = 0 //类别标示for each unvisited point P in dataset D //遍历mark P as visited //已经访问NeighborPts = regionQuery(P, eps) //计算这个点的邻域if sizeof(NeighborPts) < MinPts //不能作为核心点mark P as NOISE //标记为噪音数据else //作为核心点,根据该点创建一个类别C = next clusterexpandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心店扩展类别expandCluster(P, NeighborPts, C, eps, MinPts)add P to cluster C //扩展类别,核心店先加入for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问,if P' is not visitedmark P' as visited //进行访问NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别if sizeof(NeighborPts') >= MinPtsNeighborPts = NeighborPts joined with NeighborPts'if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别add P' to cluster CregionQuery(P, eps) //计算邻域return all points within P's eps-neighborhood
(左右滑动查看完整代码)
所以,各位机器学习、深度学习大佬们,不要再拘泥于传统DBSCAN聚类算法进行图像处理、数据分析啦,对于一个高分辨率图像,数以千百万级的像素点进行数据划分时,对于O(n2)的时间复杂度来说,传统算法带来的时间开销是相当大的。
为何不将数据结构Kd-树与其加以融合,在完全相同的聚类效果面前,花费时间更少的算法它不香吗?

以上是关于机器学习之Kd树-DBSCAN聚类算法概述的主要内容,如果未能解决你的问题,请参考以下文章