在DOS命令行里敲下javac之后计算机都发生了什么?
Posted IT服务圈儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在DOS命令行里敲下javac之后计算机都发生了什么?相关的知识,希望对你有一定的参考价值。
作者丨立体的萌
来源丨程序员架构(ID:chengxuyuanjg)
引子
我在学习java的时候,老师介绍了一种记事本编程的方式,记事本只能写代码,不能编译和运行,这时候就需要手动运行,打开DOS命令行,定位到相应的目录,输入“javac 类名.java”就完成了编译,再输入“java 类名”就运行了。
我先说一点,这里的记事本可不是文本文档!而是指的Editplus、notepad++等软件,当然用记事本也不是绝对不行,我记得老师说早期java 面试考察首先代码的能力就是直接用的文本文档,不过,我这里并不建议用,原因无他,太难用了!
这是手动编译,Eclipse、IDEA等IDE都会自动帮我们编译和运行,那么,java都是怎么编译代码的呢?
java语言?java虚拟机?
需要先明细两个很重要的概念:java语言规范和java虚拟机规范,千万注意,这俩可不是一回事,虽然学习java就必不可少学习JVM,就如同我们学习驾驶也要学习交通法规,但是你不能说驾驶技术等于交通法规,这是两回事。
驾驶技术都是针对不同种类的汽车,C1的技术与A1的技术肯定是有差距的,但是交通法规则是针对所有的交通工具,java语言规范只针对java,但是java虚拟机规范不仅仅是针对java了。
因为不仅仅是java运行在java虚拟机上,还有Kotlin、Scala、Clojure、Groovy、Jython、JRuby、Ceylon、Eta、Haxe……都是运行在java虚拟机上的语言。
java语言规范有自己的词法和词法解析规则,比如简单类型和引用类型、类型转换、名字作用域等,java虚拟机规范有自己的词法和词法解析规则,比如堆、栈、垃圾收集等。
javac是一种编译器,他的工作就是建立java语言规范和java虚拟机规范字之间的桥梁,就如同一名翻译官,把java语言规范翻译成java虚拟机规范。
正是因为有了javac,我们写的java源代码才能转换成虚拟机能看懂的字节码(当然了,对于人来说字节码上的内容简直就是火星文)JVM再把字节码转化成对人类更加不友好的机器语言,高级语言的繁荣都是建立在编译器的基础之上的!
javac,我们来啦!
javac,我们来啦!
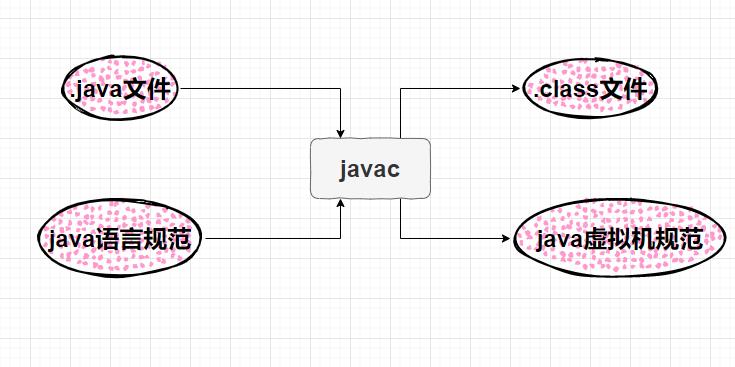
javac是一种编译器,javac的工作原理包含于编译原理的工作原理,在这里需要复习一下编译原理。
第一步:读取源代码。以一个字节为一节进行读取,然后提取出语法关键字:if、else、while等,这就好比你给我说了一句话,我都听见了。
第二步:词法分析。提取出法语关键字之后,还要对提取出来的语法关键字进行识别:看哪些是合法的,这叫做从源代码中找出规范化的Token流,这就好比我听出来你的话中的主语、谓语等。
第三步:语法分析。这一步就是检查组合在一起的关键字是不是符合java语言规范,这就好比我在检查你说的话有没有语法错误,如果把“我吃饭”说成“我饭吃”就是不对的。
语法分析的结果会生成一个符合java语言规范的抽象语法树(一种结构化的语法表达形式),它的作用在于把语言的主要词法都用一个结构化的形式组织在一起,这棵树的神奇之处在于我们还可以按照新的规则重新组织。
第四步:语义分析。这是个化繁为简的过程,就好比把“不应而而而”翻译成“不应该用而,而你却用了而”。
第五步:生成字节码。通过字节码生成器来生成字节码。
这是javac的基本结构:
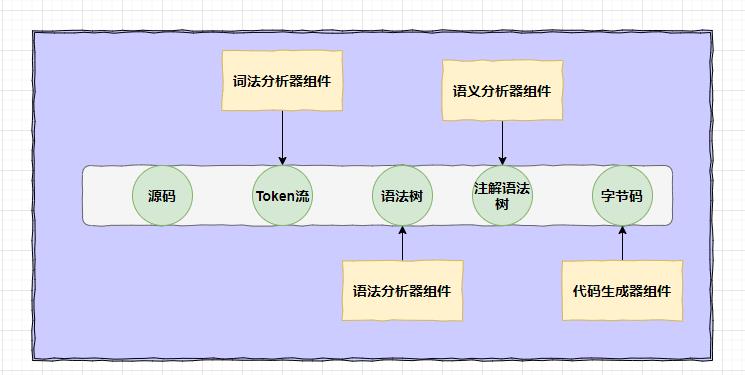
词法分析器
来一段幼儿园代码:
package compile;
public class cffx{
int a;
int c=a+1;
}
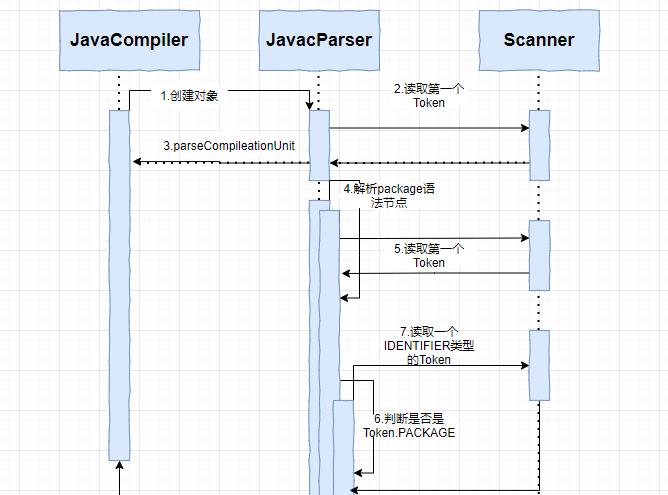
Javac关于词法分析器的接口类是com.sun.tools.javac.parser.Lexer,它的默认实现类是com.sun.tools.javac.parser.Scanner,Scanner会逐个读取java源代码的字符,ScannerFactory和ParserzFactory分别生成了两个接口的实现类:Scanner和JavacParse,前者具体读取和归类不同词法,后者则负责检查哪些词符合java语言规范;
词法分析过程由JavacParser的parseCompilationUnit函数来完成:
public JCTree.JCCompilationUnit parseCompilationUnit(){
int pos=S.pos();
JCExpression pid=null;
String dc=S.docComment();
JCModifiers mods=null;
List<JCAnntation>packageAnnotations=List.nil();
if(S.token()==MONKEYS_AT)
//解析修饰符
mods=modifiersOpt();
if(S.token()==PACKAGE){
//解析Package声明
if(mods!=null){
checkNoMods(mods.flags);
packageAnnotations=mods.annotations;
mods=null;;
}
S.nextToken();
pid=qualident();
accept(SEMT);
}
ListBuffer<JCTree> defs=new ListBuffer<JCTree>();
boolean checkForImports=true;
while(S.token()!=EOF){
if(S.pos()<=errorEndPos){
//跳过错误字符
skip(checkForImports,false,false,false);
if(S.token()==EOF){
break;
}
if(checkForImports&&mods==null&&S.token()==IMPORT){
defs.append(importDeclaration());
//解析import声明
}else{
//解析class类 主体
JCTree def=typedeclaration(mods);
if(keepDocComments&&dc!=null&&docComments.get(def)==dc){
dc==null;
}if(def itoplevelnstanceof JCExpressionStatement)
def=((JCExpressionStatement)def).expr;
defs.append(def);
if(def instanceof JCClassDecl)
checkForImports =false;
mods=null;
}
}
JCTree.JCComplilationUnit toplevel=F.at(pos).TopLevel(packageAnntations,pid,defs.toList());
attach(toplevel,dc);
if(defs.elems.isEmpty())
storeEnd(toplevel,S.prevEndPos());
if(keepDocComments)
toplevel.docComments=docComments;
if(KeepLineMap)
toplevel.lineMap=S.getLineMap();
return toplevel;
}
}
我们直接手动编译,通过调用com.sun.tools.javac.main.Main的compile函数来编译:
public static int compile(String[] args){
com.sun.tools.javac.main.Main compiler=
new com.sun.tools.javac.main.Main("javac");
return compiler.compile(args);
}
词法分析器的结果就是把这个类中的所有的关键字匹配到Token类的所有项的任何一项;
语法分析器
前面说过语法分析器的作用就是组件语法树,每个语法树上的节点都是
每个语法树节点都会实现一个接口(xxxTree),这个接口又继承自com.sun.source.tree.Tree接口;
每个语法节点都是com.sun.tools.javac.tree.JCTree的子类,并且会实现第一节点中的xxxTree接口类,这个类的名称类似于JCxxx;
所有的JCxxx类都会作为一个 静态内部类定义在JCTree类中。
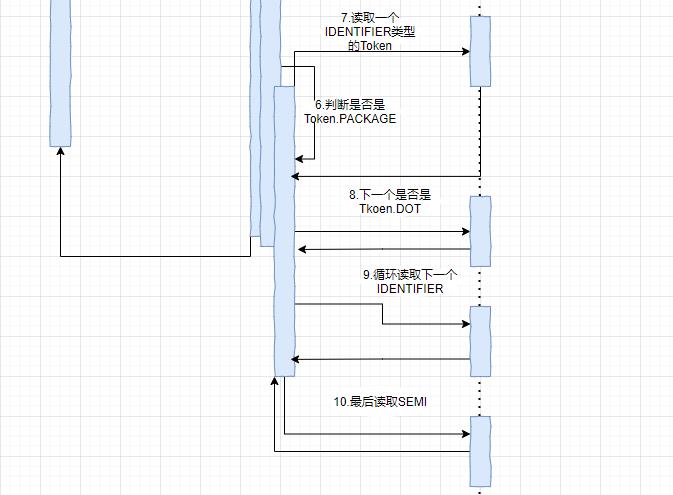
Package节点解析完成后进入while循环,首先解析importDeclaration,解析规则与package类似,先检查Token是不是Token.IMPORT,,如果是的话就用import语法规则来解析import节点,最后构造一个import语法树:
JCTree importDeclaration(){
int pos=S.pos();
S.nextToken();
boolean importStatic=false;
if(S.Token()==STATIC){
checkStaticImports();
importStatic=true;
S.nextToken();
}
JCExpression pid=toP(F.at(S.pos()).Ident(ident()));
do{
int pos1=S.pos();
accept(DOT);
if(S.token()==STAR){
pid = to(F.at(pos1).Select(pid,names.asterisk));
S.nextToken();
break;
}else{
pid=top(F.at(pos1).Select(pid,ident()));
}
}while(S.Token()==DOT);
accept(SEMI);
return top(F.at(pos).Import(pid,importStatic));
}
接着检查是否有static关键字,如果有的话就设置标识表示这个import语句是一个静态类引入,再解析第一个类路径,如果是多级目录的话,则继续读取下一个Token,并构造为JCFieidAccess节点(也是嵌套节点),如果最后一个Token是“*”,则设置这个JCFieldAccess 的Token名称为asterisk,import语句读取完最后一个分号的时候标志着一个import语句解析完成,把这个解析的语法节点作为子节点构造在新创建的JCImport节点中。
再接着就是类的解析,我以class为例:
JCClassDecl classDeclaration(JCModifiers mods,String dc){
int pos=S.pos();
accept(CLASS);
Name name=ident();
List<JCTypeParameter> typarams=typeParametersOpt();
JCTree extending =null;
if(S.token()==EXTENDS){
S.nextToken();
extending=parseType();
}
List<JCExpression> implementing=List.nil();
if(S.token()==IMPLEMENTS){
S.nextToken();
implementing=typeList();
}
List<JCTree> defs=classOrInterfaceBody(name,false);
JCClassDecl result =toP(F.at(pos).ClassDef(
mods,name,typarams,extending,implementing,defs
));
attach(result,dc);
return result;
}
语义分析器
有了前面两步,就已经搭起了一个大体的框架,剩下的就是往里面填充内容,比如:给类添加默认的构造函数、把一些常量进行合并处理等,还可以解除java的语法糖,语义分析完成之后就可以生成java字节码了,他具体是怎么工作的呢?
把在java类中的符号输入到符号表中主要由com.sun.tools.javac.comp.Enter类来完成:
第一步:把在所有类中出现的符号输入到类自身的符号表中,所有类符号、类的参数类型符号(泛型参数类型)、超类符号和继承的接口类型符号等都存储到一个未处理的列表中。
第二步:把这个未处理列表中的所有的类都解析到各自的类符号列表中,这个操作是在MemberEnter.complete()中完成的。
if((c.flags()& INTERFACE)==0&&!
TreeInfo.hasConstructors(tree.defs)){
List<Type> argTypes=List.nil();
List<Type> typarams=List.nil();
List<Type> thrown=List.nil();
long ctorFlags=0;
boolean based=false;
if(c.name.isEmpty()){
JCNewClass nc=(JCNewClass)env.next.tree;
if(nc.constructor!ctor=null){
Type superConstrType=types.memberType(c.type,nc.constructor);
argtypes =superConstrType.getParametetTypes();
typarams=superConstrType.getTypeArguments();
ctorFlags=nc.constructor.flags()&VARARGS;
if(nc.encl!=null){
argtypes =argtypes.pretend(nc.encl.type);
based=true;
}
thrown=superConstrType.getThrownType();
}
}
JCTree constrDef=DefaultConstructor(make.at(tree.pos),c,typarams,
argtypes,
thrown.ctorFlags,based);
tree.defs=tree.defs.pretend(constrDef);
}
代码生成器
万事具备,只欠东风,所有的该生成的都完成了,就差把结果显示出来了,javac通过调用com.sun.tools.javac.jvm.Gen遍历语法树:
第一步:把java方法中的代码块转化成符合JVM语法的命令格式,JVM的操作都是基于栈的;
第二步:按照JVM的文件组织格式把字节码输出到以class为扩展名的文件中;
public class Daima{
public static void main(String[] args){
int rt=add(1,2);
}
public static int add(Integer a,IntegeR b){
return a+b;
}
}
JVM都是通过栈来操作操作数的,所以要进行一个二元操作,先把a和b放到操作栈,再利用加法操作符执行加法操作,把结果放到操作栈的栈顶,然后把结果返回给调用者。
访问者模式
前面的四个步骤都涉及到了遍历语法树的操作,但是每次遍历语法树都会进行不同的处理动作,有的时候需要做进一步的处理,这是怎么实现的呢?答案就是访问者模式。
这是访问者模式的结构图:
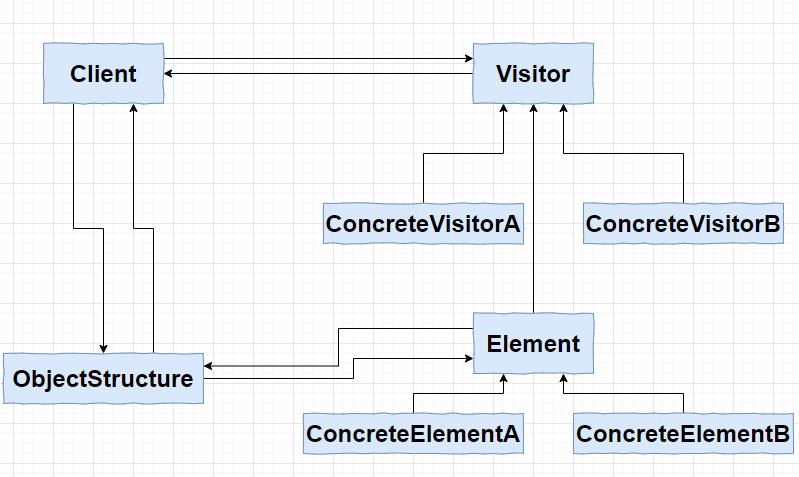
具体功能如下图所示:
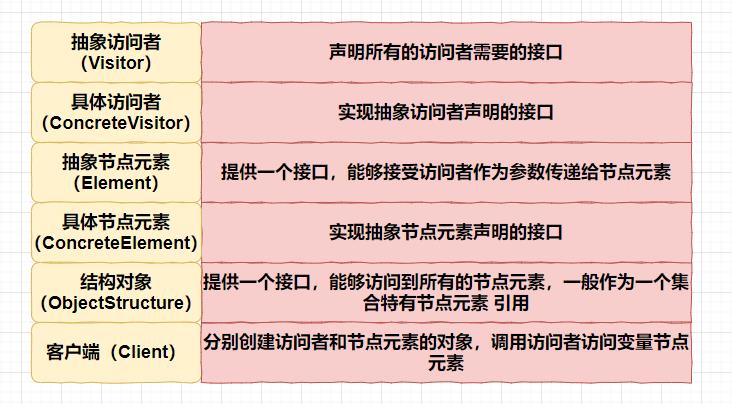
总结:
这就是javac编译器的工作原理,如果要评价20世纪关于软件的发明的话,我一定要把这个荣誉给编译器,正是因为有了编译器,我们才可以不用跟艰难晦涩的汇编语言甚至是更加不人性化的机器语言做开发,以编译器为基础的人性化的高级语言可以说为软件的前进做了一大步!
关于作者:
请作者吃糖

个人网址:https://blog.csdn.net/weixin_46107282
声明:本文为 程序员架构 原创投稿,未经允许请勿转载。

1、
2、
3、
4、

点分享
点点赞
点在看
以上是关于在DOS命令行里敲下javac之后计算机都发生了什么?的主要内容,如果未能解决你的问题,请参考以下文章