四两拨千斤,如何做到自然语言预训练加速十倍
Posted 微软研究院AI头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四两拨千斤,如何做到自然语言预训练加速十倍相关的知识,希望对你有一定的参考价值。
编者按:随着自然语言处理中的预训练成为研究领域的热点,预训练的成本与计算代价也成为了大家在研究过程中必须考虑的现实问题。本文将会介绍多种在训练模型过程中提高效率,降低成本的方法,希望能对大家的研究有所帮助。
近年来,自然语言处理中的预训练成为了研究领域的热点,著名的 GPT-3 也掀起了一波新的浪潮。但是众所周知,训练这样大规模的模型非常消耗资源:即使在维基百科数据上训练一个简单的 BERT-Base 模型,都需要用许多 GPU 训练1-2周,且不说购买 GPU 的开销,光是电费就需要数万美金。这样的消耗只有工业界的几个大公司才可以实现,极高的门槛限制了相关方向的探索以及整体发展。
为了降低预训练的准入门槛,微软亚洲研究院机器学习组的研究员们从机器学习中的不同角度出发,针对预训练的不同侧面分别提出了加速方法。具体而言,研究员们提出了基于 Transformer 的新结构 TUPE,针对 BERT 设计了数据高效利用的策略,以及扩展了类似人类学习的预训练任务。其中前两项工作已被新鲜出炉的 ICLR 2021 接收。这些方法既可以独立使用,也可以结合起来使用,从而可以达到更大的加速比。原来需要10天的训练,现在只要一天就可以完成!
位置表征(Positional Embedding)大家都知道,但这个设计真的高效、合理吗?
由于 Transformer 在结构上不能识别来自不同位置的词语,所以模型一般需要用位置表征来辅助。其中最简单的做法就是在输入词向量上直接加位置表征,但词向量和位置向量相加是不是一个正确的选择呢?词向量的加减操作可以保持语义,但位置向量本身是不具备语义的,两者相加会不会让模型更难学呢?在第一层对 Transformer 的注意力分布(attention weight)进行展开可以得到:
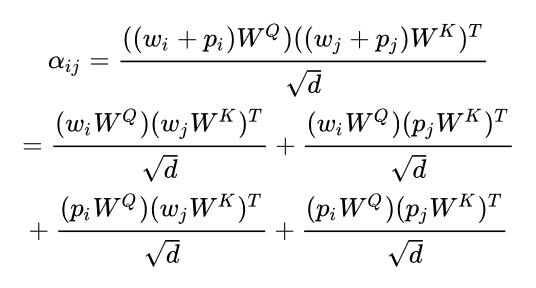
从上面展开的公式里,可以发现两个问题:第一,中间两项引入了词语和位置信息的交叉,但没有理由说某个位置和某个词一定有很强的关联(论文中有详细的实验分析也表明了中间两项有一定的冗余),第二,第一项和第四项分别计算词与词、位置与位置的关联,但他们采用了相同的参数化函数 (W^Q 和 W^K),从而限制了注意力表达能力。
为了解决上述两个问题,微软亚洲研究院的研究员们做了一些简单的改动:
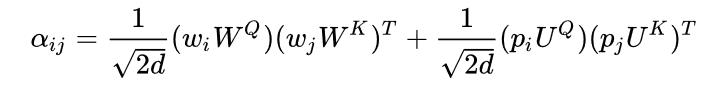
简单来说,就是去掉了位置 (position) 和文本( token) 之间的交叉,同时用了不同的变换矩阵。需要注意的是,在多层的 Transformer 模型里,比如 BERT,上面公式的第二项在不同层之间是共享的。因此,这里仅需要计算一次,几乎没有引入额外的计算代价。
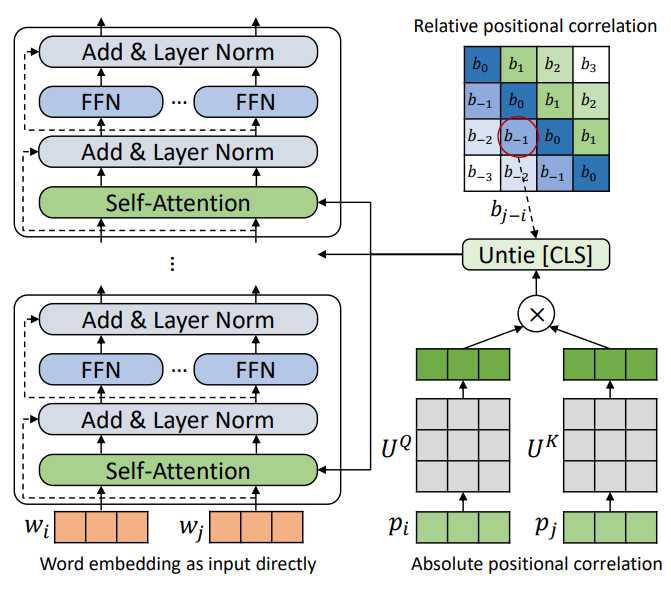
图1:整体 TUPE (Transformer with Untied Positional Encoding) 结构
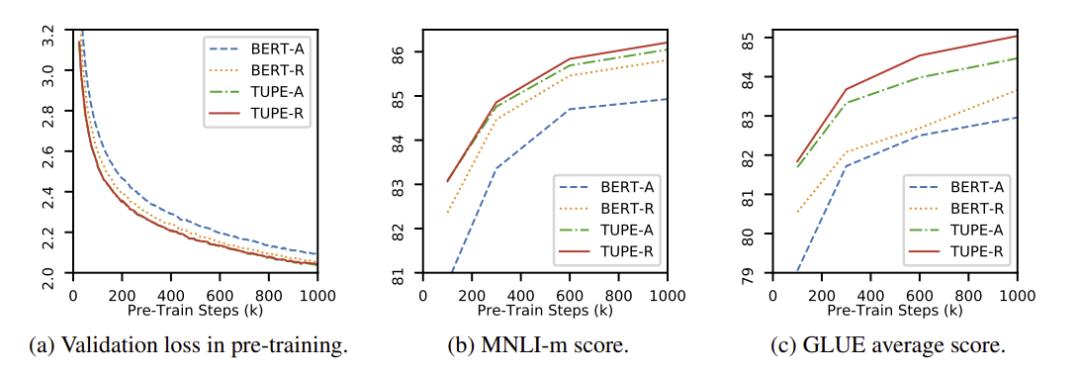
图2:实验结果
另外,研究员们还特殊处理了 [CLS] token 的位置,使其不会因太过关注局部而忽略了整个句子的信息,整体 TUPE (Transformer with Untied Positional Encoding)结构如图1所示。实验结果如图2,可以看到,该方法不仅最后比基线要好很多,并且可以在 30% (300k-step) 的时候,就达到基线在 1000k-step 时的效果。
TUPE 的完整工作请见:
https://openreview.net/forum?id=09-528y2Fgf
众所周知,在语言数据集中,单词通常具有非常长尾的分布,即大量的单词在整个数据集中都具有很低的出现频率。而这些低频词的词向量,往往训练质量都不佳。这些低质量的词向量,给模型理解整句训练语句造成了困难,进而拖慢了整个模型预训练的速度。
举例来说,如图3所示,如果「COVID-19」是一个低频词,做完形填空的人如果对其含义一无所知的话,那么想要填对合适的词是十分困难的,类似的问题也会发生在自然语言预训练的过程中。

图3:低频词例
由此,微软亚洲研究院的研究员们提出了为低频词词动态记笔记的方法 Taking Notes on the Fly(TNF),记录历史上出现过稀有词的句子信息,从而使得当模型再见到该低频词的时候,对其的理解能够更加充分。如图3所示,研究员们希望模型能够从笔记「The COVID-19 pandemic is an ongoing global crisis」(COVID-19 是一场持续发生的全球危机)推测出「COVID-19」与生命有关,从而更容易理解任务得出上述完形填空问题的答案「lives」(生命)。
具体说来,TNF 维护了一个笔记词典。在这个笔记词典中,每一个低频词都存有一个上下文表征向量(Contextual representation)来作为笔记。当该词出现时,TNF 从笔记词典中取出其的上下文表征向量,与其词向量一起构成模型在该位置的输入,同时也更新笔记上针对这个词的内容。如图4所示:
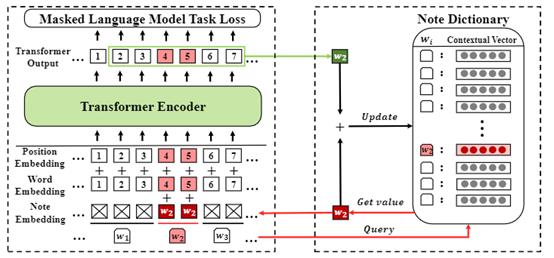
图4:TNF 的训练过程
研究员们将 TNF 应用到了两个著名且有效的语言预训练方法 BERT 和 ELECTRA 上进行实验,同时也在 GLUE 上对预训练的模型进行了精调,然后对比。实验结果表明,在两个预训练方法上,当 TNF 与基线达到相同的实验结果时,TNF 的训练时间仅仅为基线的40%(见图5)。
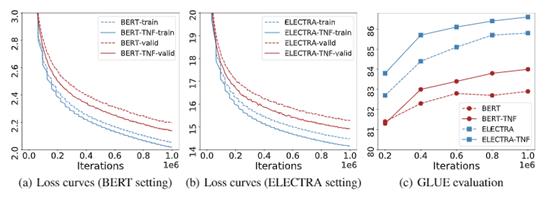
图5:TNF 的训练曲线
当 TNF 与基线训练相同的迭代更新次数时,TNF 在 GLUE 上的平均 GLUE Score 和大多数子任务上的表现均超过了基线。
TNF 的完整工作请见:
https://openreview.net/forum?id=lU5Rs_wCweN
目前许多预训练模型都会使用掩码语言模型任务,即遮挡住输入句子的一部分,让模型还原被遮挡的部分。该任务实际上相当于一个「完形填空」问题,但与考试中常见的完形填空不同,自然语言预训练中的完形填空备选项是整个词典。显然,即使对于人类来说,在没有备选答案的开放环境下,想要准确完成这个「完形填空」任务也是十分困难的。
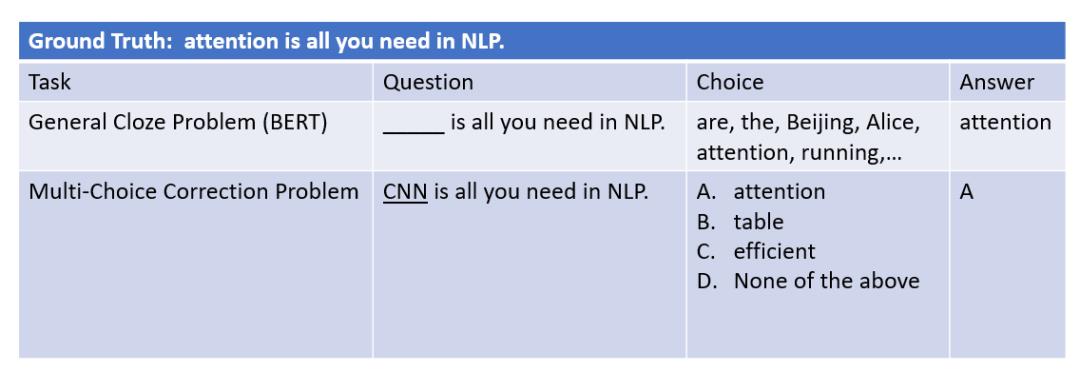
图6:单选题任务
实际上,人类更容易完成选择题或判断题。在给定有限选项的条件下,任务的难度会极大降低。著名的「ELECTRA」模型使用的就是判断题任务,在前期设计的判断题容易,于是训练效率很高。随着模型的训练,判断题设计越来越难,模型可以一直得到有效的反馈。与 ELECTRA 稍有区别,微软亚洲研究院的研究员们给模型设计的预训练任务是 ABCD 单选题,并希望能够动态地调整单选题的难度。在早期学习中,设计简单的单选题,令模型完成相对简单的任务,从而加快学习进程,在后期则逐渐加大任务难度,从而获得更精细的结果。在这里可以通过设计不同难度的任务以及选项的个数调节任务的难度(选项越多任务越困难)。
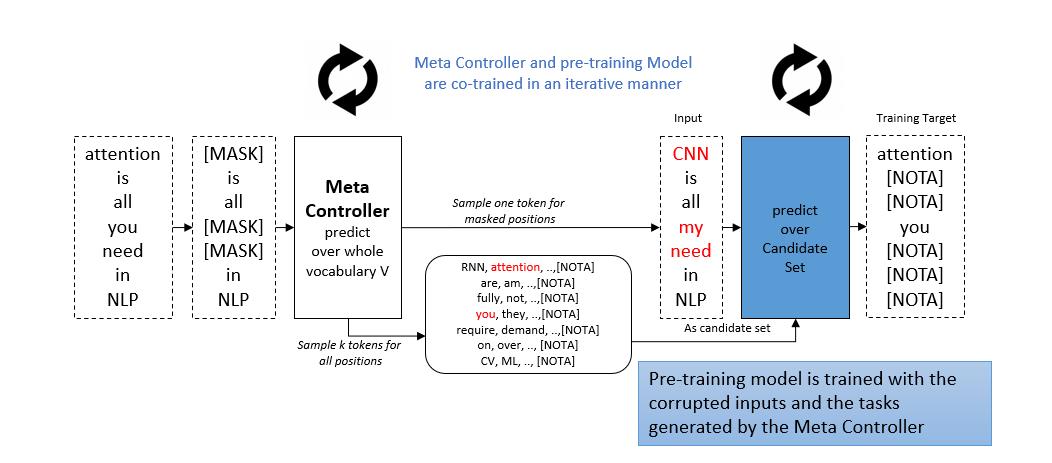
图7:使用元控制器进行预训练
为了达到训练任务从易到难的效果,一个能够出题的「元控制器」被提出,它能够自适应地改变多选题的难度。特别的是,这个元控制器是一个较小的 BERT,基于掩码语言模型进行预训练,并随着主模型一起训练迭代。对于每句话先对这句话进行遮挡,然后元控制器以遮挡后的语句作为输入,并输出被遮挡目标词相关的词例,这些词例将被用于构造备选答案。
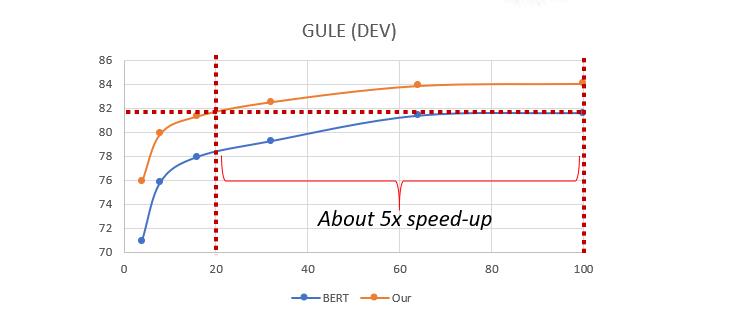
图 8:基于自适应多选题任务的预训练实验结果
可以看到,在训练初期,元控制器的训练并不充分,于是生成备选答案的质量不高,主模型可以在这些容易的任务上很快学习到正确的知识。在训练后期,元控制器的训练接近完成,可以生成高质量的备选答案,从而主模型可以在这些困难的任务上得到进一步的进化。
将这个元控制器应用到 BERT上,可以发现与原始 BERT 相比,训练速度提升了80%,即在下游任务 GLUE 上,用20%的计算开销训练得到的模型,可以与训练时间长5倍的 BERT 模型相匹配。
完整工作请见:
https://arxiv.org/abs/2006.05744
正如文章标题所言,通过对预训练模型及其训练过程进行仔细思考,完全可以用四两拨千斤的手段,降低预训练的成本与计算代价。大力出奇迹很重要,但大力出奇迹并不是科学研究的全部。
你也许还想看:
以上是关于四两拨千斤,如何做到自然语言预训练加速十倍的主要内容,如果未能解决你的问题,请参考以下文章
看MindSpore加持下,如何「炼出」首个千亿参数中文预训练语言模型?