史上最全医疗自然语言理解任务基线发布!
Posted AI科技评论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了史上最全医疗自然语言理解任务基线发布!相关的知识,希望对你有一定的参考价值。
随着人工智能(AI)技术的不断发展,越来越多的研究者开始关注AI技术在医学健康领域的研究应用,其中加速AI技术发展的一个关键环节是标准数据集和科学评估体系的建立。
由中国中文信息学会医疗健康与生物信息处理专业委员发起的中文医疗信息处理挑战榜CBLUE[1]于今年4月份上线,该 benchmark 覆盖了8类经典的医学自然语言理解任务,是业界首个公开的中文医疗信息领域公开评测基准。
CBLUE上线后受到了产研界的广泛关注,目前已经吸引了300多支队伍参与打榜。近日,CBLUE工作组公开了论文[2]并开源了评测基准baseline[3]。本文对常见的医学自然语言理解任务以及模型方法做一个全面介绍。


任务介绍


CBLUE的全称是Chinese Biomedical Language Understanding Evaluation Benchmark,包括医学文本信息抽取、医学术语标准化、医学文本分类和医学问答4大类经典的医疗信息处理任务。
CBLUE为研究者们提供真实场景数据的同时,也为多个任务提供了统一的测评方式,目的是促进研究者们更加关注AI模型的泛化能力。

以下是各个子任务的简单介绍:

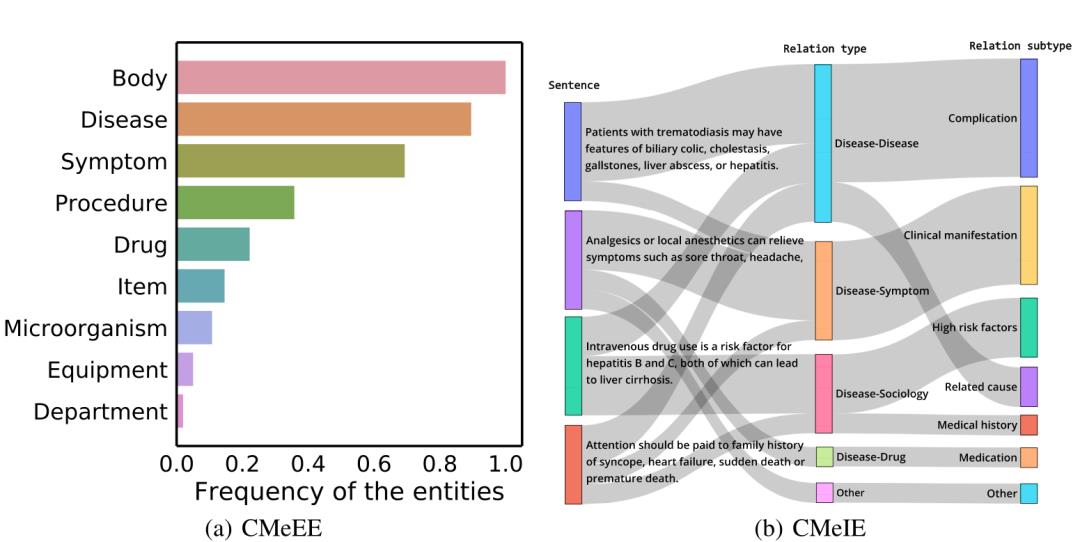
CMeEE(Chinese Medical Entity Extraction dataset):医学实体识别任务,识别出医学文本中的关键术语,如“疾病”、“药品”、“检查检验”等。
CMeIE(Chinese Medical Information Extraction dataset):医学关系抽取任务,即推断医学文本中两个实体之间的关系,如“类风湿性关节炎”与“关节压痛计数” 两个医学术语之间构成了“疾病-检查”的关系。实体识别和关系抽取是医学自然语言处理中非常基础的技术,可应用于电子病历结构化、医院数据治理、医学知识图谱建设等应用场景。
任务特点
CBLUE工作组对评测基准包含的8个任务做了特点总结:
方法介绍
以Bert[4]为代表,大规模预训练语言模型已经成为了NLP问题求解的新范式,因此CBLUE工作组也选择了11种最常见的中文预训练语言模型作为baseline来进行充分的实验,并对数据集性能进行了详尽的评估,目前是业界最全的中文医疗自然语言理解任务基线,可以帮助从业人员解决常见的医学自然语言理解问题。
11种实验的预训练语言模型简介如下:
综合RoBERTa和BERT-wwm优势的预训练模型;
性能评估&分析
下图为11种预训练模型在CBLUE上的基线表现:
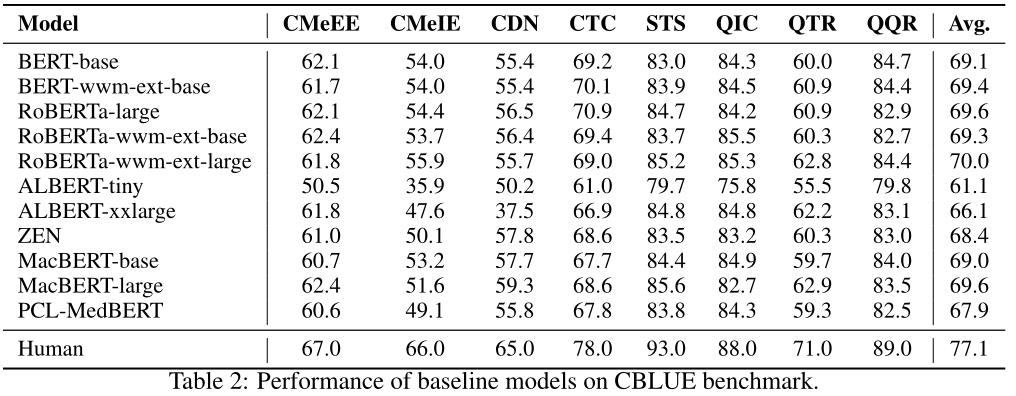
如上表所示,使用更大的预训练语言模型,可以获得更好的性能。在某些任务中,使用全词遮蔽的模型并不比其他模型表现好,例如CTC、QIC、QTR和QQR,这表明CBLUE中的任务具有一定的挑战性,需要更好的模型来解决。
此外,我们发现albert-tiny在CDN、STS、QTR和QQR的任务中实现了与基础模型相当的性能,说明较小的模型在特定的任务中也可能是有效的。
最后,我们注意到医学预训练语言模型PCL-MedBERT的性能不如预期的好,这进一步证明了CBLUE的难度,当前的模型可能很难快速取得出色的效果。
结束语
CBLUE挑战榜的目标是可以让研究人员在合法、开放、共享的理念下有效的使用真实场景的数据,通过多任务场景设置来让研究者们更加关注模型的泛化性能。同时也希望公开的基线评测代码能有效的促进医疗AI社区的技术进步。
希望在挑战榜上一展身手的小伙伴们,请在文末点击阅读原文,参加打榜,即可获赠天池定制礼品!
参考文献
[1].https://mp.weixin.qq.com/s/wIqPaa7WBgkxUGLku0RBEw
[2].https://arxiv.org/pdf/2106.08087.pdf
[3].https://github.com/CBLUEbenchmark/CBLUE
[4].Jacob Devlin, Ming-Wei Chang, KentonLee, and Kristina Toutanova. Bert: Pre-training of deep bidirectionaltransformers for language understanding. In NAACL-HLT, 2018.
[5].YimingCui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, and GuopingHu. Pre-training with whole word masking for chinese bert. arXiv preprintarXiv:1906.08101, 2019.
[6].YinhanLiu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy,Mike Lewis, Luke Zettlemoyer, and V eselin Stoyanov. Roberta: A robustlyoptimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[7].ZhenzhongLan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut.Albert: A lite bert for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942, 2019.
[8].ShizheDiao, Jiaxin Bai, Y an Song, Tong Zhang, and Y onggang Wang. Zen: pre-trainingchinese text encoder enhanced by n-gram representations. arXiv preprintarXiv:1911.00720, 2019.
[9].YimingCui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. Revisiting pre-trainedmodels for chinese natural language processing. arXiv preprintarXiv:2004.13922, 2020.
[10].https://code.ihub.org.cn/projects/1775
以上是关于史上最全医疗自然语言理解任务基线发布!的主要内容,如果未能解决你的问题,请参考以下文章