为啥HDFS副本数大于3,还一直处于复制中
Posted 架构与英文
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥HDFS副本数大于3,还一直处于复制中相关的知识,希望对你有一定的参考价值。
问题背景:客户现场运维人员发现HDFS集群上有51936个blocks一直处于复制中,持续几天一直没有减少。
问题猜想:由于hdfs复制数据的速度非常快,5万多个blocks应该在几个小时就结束了,但现场却持续了2天,初步猜想原因有两个:
1. HDFS Web 界面显示异常;
2. HDFS磁盘空间满了导致数据没地方复制。
由于现场的HDFS未处于safemode模式,且磁盘空间也是充足的,所以只能判断是HDFS Web 界面显示异常导致。
问题分析:查看HDFS当前的blocks是3百多万,可以按目录进行健康检查,分别执行hdfs fsck /目录进行检查。如果所有目录的检查结果的missing blocks均是0的话,就可以判断是hdfs界面显示的问题了。为了尽量较少业务的运行,从业务使用少的数据目录开始健康检查。
步骤一、 首先检查的是spark-history、mr-history、user目录
检查spark-history、mr-history目录时,missing blocks均为0,然后开始检查user目录,最终发现了问题。结果如图:
步骤二、 从上图红色框圈住的地方可以看出,正是这个目录下的blocks发生了缺失,不是HDFS web界面导致。“Target Replicasis 10 but found 6 live replicas”这句话说明这些目录的blocks需要10个副本但是只找到了6个,当前集群的datanode个数也是6,也就是还有4个副本永远不会被复制,正解释了为什么blocks会一直处于复制中的原因。
问题来了,明明hdfs设置的是dfs.replication=3,哪来的10副本?
步骤三、 从目录路径/user/testa/.staging/job_*可以看出这是MapReduce或者Spark分布式任务执行过程中产生的临时目录,任务执行结束就消失了,任务异常中止就会一直存在。查阅资料确定MapReduce的临时路径参数yarn.app.mapreduce.am.staging-dir, 查看配置正是/user目录,和上图的目录完全吻合,其主要存储任务需要的依赖jar和临时计算数据。再继续分析,发现MapReduce有一个设置临时目录副本数的参数mapreduce.client.submit.file.replication=10。查阅资料这个参数的作用是,当集群规模比较大,且启动的map和reduce数量较多时,可充分利用数据本地性这一特性提高性能。 Spark的临时副本配置参数是 spark.yarn.submit.file.replication=3,可以排除。
种种迹象表明,该参数mapreduce.client.submit.file.replication很大可能是导致问题的原因。因此需要进行复现验证:
复现验证:测试集群提交一个MapReduce任务,观察中间执行过程的missing blocks是否存在。
1、MapReduce管理页面点击服务检查提交MapReduce任务;
任务执行前检查missing blocks=0
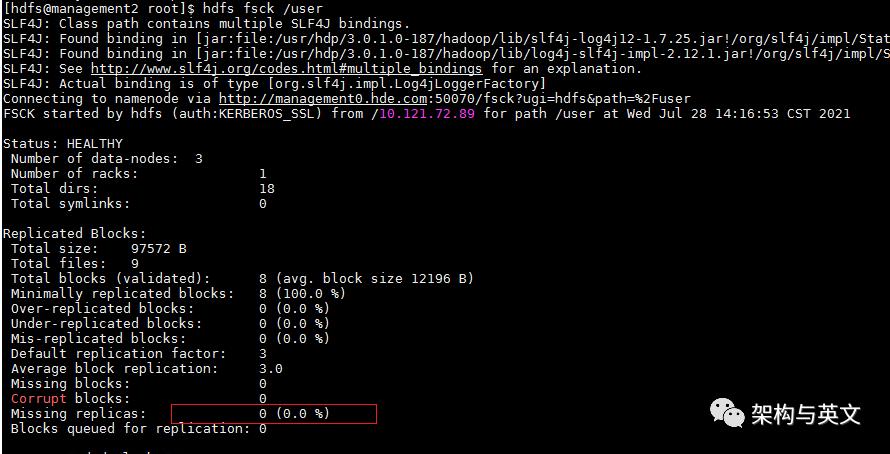
2、任务执行过程中执行:hdfs fsck /user 服务监控检查;
可以看到此时已经有missing blocks,且出现了“Target Replicasis 10 but found 3 live replicas”
3、任务结束后再次执行:hdfs fsck /user 服务监控检查;
此时任务正常结束,missing blocks=0
4、设置mapreduce.client.submit.file.replication=3,重复执行上述3步,missing block一直为0;
从复现结果看确实是mapreduce.client.submit.file.replication=10导致。
解决方法:mapreduce.client.submit.file.replication=10(默认值)导致的问题。修改这个参数的值小于DataNode节点个数,使副本可以全部落盘。
对于历史已提交异常结束的任务可通过两个方法处理:
1、直接删除目录,但缺点是后面如果分析异常application会找不到历史记录。
2、通过hdfs dfs –setrep 3 –R –w /user强制设置为3副本。
问题结论:
1、部分blocks副本数大于3是mapreduce.client.submit.file.replication=10导致。
2、一直处于复制中是因为mapreduce.client.submit.file.replication > N ( DataNode ) ,一个DataNode上只能有一个副本;
以上是关于为啥HDFS副本数大于3,还一直处于复制中的主要内容,如果未能解决你的问题,请参考以下文章
Datanodes 处于活动状态,但我无法将文件复制到 HDFS [Hadoop 2.6.0 - Raspberry Pi Cluster]