图像识别基于卷积神经网络(CNN)实现垃圾分类Matlab源码
Posted 天天Matlab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别基于卷积神经网络(CNN)实现垃圾分类Matlab源码相关的知识,希望对你有一定的参考价值。
一、
一、垃圾分类
如何通过垃圾分类管理,最大限度地实现垃圾资源利用,减少垃圾处置量,改善生存环境质量,是当前世界各国共同关注的迫切问题之一。根据国家制定的统一标准,现在生活垃圾被广泛分为四类,分别是可回收物、餐厨垃圾、有害垃圾和其他垃圾。可回收物表示适宜回收和资源利用的垃圾,主要包括废纸、塑料、玻璃、金属和布料五大类,用蓝色垃圾容器收集,通过综合处理回收利用。餐厨垃圾包括剩菜剩饭、骨头、菜根菜叶、果皮等食品类废物,用绿色垃圾容器收集等等。但是随着深度学习技术的发展,为了简单高效地对生活垃圾进行识别分类,本篇文章将实现一种基于卷积神经网络的垃圾分类识别方法。该方法只需要对图像进行简单的预处理,CNN模型便能够自动提取图像特征且池化过程能够减少参数数量,降低计算的复杂度,实验结果表明卷积神经网络,能克服传统图像分类算法的诸多缺点,当然更为复杂的模型等待大家去实验研究。但是目前认为采用VGG或者global 池化方式可能效果更好一点。
二、卷积神经网络CNN
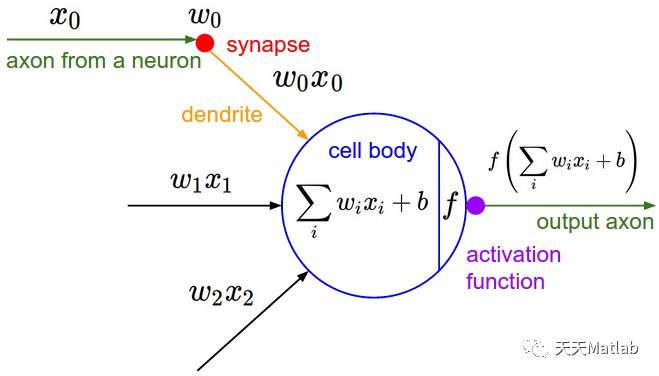
卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
所以哪里不同呢?卷积神经网络默认输入是图像,可以让我们把特定的性质编码入网络结构,使是我们的前馈函数更加有效率,并减少了大量参数。
具有三维体积的神经元(3D volumes of neurons)
卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth(注意这个depth不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 32 × 32 × 3 (rgb),那么输入神经元就也具有 32×32×3 的维度。下面是图解:
传统神经网络
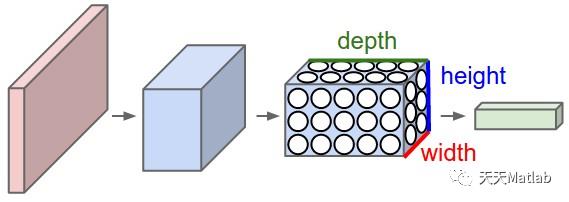
卷积神经网络
一个卷积神经网络由很多层组成,它们的输入是三维的,输出也是三维的,有的层有参数,有的层不需要参数。
Layers used to build ConvNets
卷积神经网络通常包含以下几种层:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
一个卷积神经网络各层应用实例: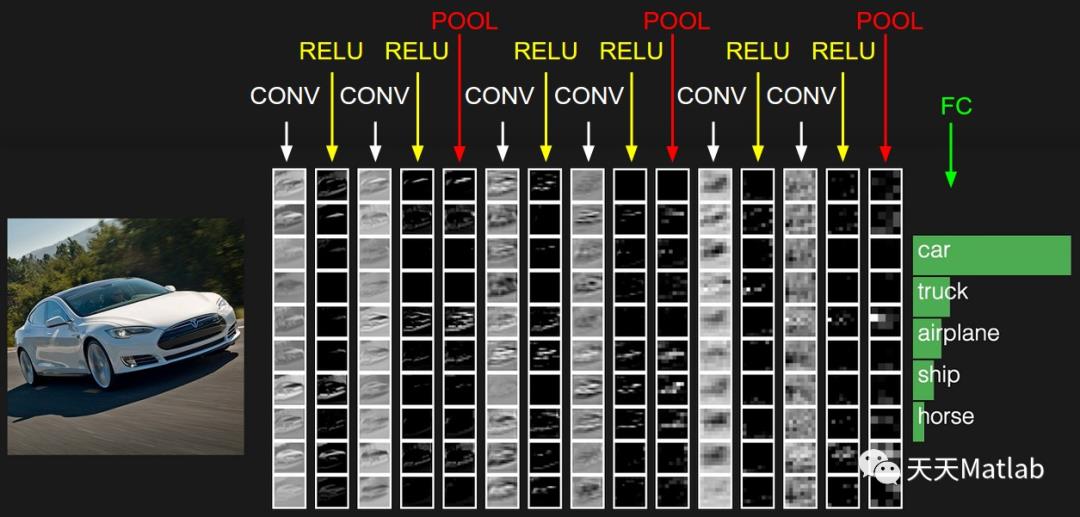
卷积层(Convolutional layer)
局部感知(Local Connectivity)
普通神经网络把输入层和隐含层进行“全连接(Full Connected)“的设计。从计算的角度来讲,相对较小的图像从整幅图像中计算特征是可行的。但是,如果是更大的图像(如 96x96 的图像),要通过这种全联通网络的这种方法来学习整幅图像上的特征,从计算角度而言,将变得非常耗时。你需要设计 10 的 4 次方(=10000)个输入单元,假设你要学习 100 个特征,那么就有 10 的 6 次方个参数需要去学习。与 28x28 的小块图像相比较, 96x96 的图像使用前向输送或者后向传导的计算方式,计算过程也会慢 10 的 2 次方(=100)倍。
卷积层解决这类问题的一种简单方法是对隐含单元和输入单元间的连接加以限制:每个隐含单元仅仅只能连接输入单元的一部分。例如,每个隐含单元仅仅连接输入图像的一小片相邻区域。(对于不同于图像输入的输入形式,也会有一些特别的连接到单隐含层的输入信号“连接区域”选择方式。如音频作为一种信号输入方式,一个隐含单元所需要连接的输入单元的子集,可能仅仅是一段音频输入所对应的某个时间段上的信号。)
每个隐含单元连接的输入区域大小叫r神经元的感受野(receptive field)。
由于卷积层的神经元也是三维的,所以也具有深度。卷积层的参数包含一系列过滤器(filter),每个过滤器训练一个深度,有几个过滤器输出单元就具有多少深度。
具体如下图所示,样例输入单元大小是32×32×3, 输出单元的深度是5, 对于输出单元不同深度的同一位置,与输入图片连接的区域是相同的,但是参数(过滤器)不同。
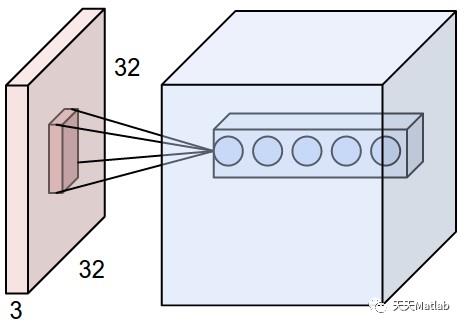
虽然每个输出单元只是连接输入的一部分,但是值的计算方法是没有变的,都是权重和输入的点积,然后加上偏置,这点与普通神经网络是一样的,如下图所示:
空间排列(Spatial arrangement)
一个输出单元的大小有以下三个量控制:depth, stride 和 zero-padding。
深度(depth) : 顾名思义,它控制输出单元的深度,也就是filter的个数,连接同一块区域的神经元个数。又名:depth column
步幅(stride):它控制在同一深度的相邻两个隐含单元,与他们相连接的输入区域的距离。如果步幅很小(比如 stride = 1)的话,相邻隐含单元的输入区域的重叠部分会很多; 步幅很大则重叠区域变少。
补零(zero-padding) :我们可以通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。
我们先定义几个符号:
: 输入单元的大小(宽或高)
: 感受野(receptive field)
: 步幅(stride)
: 补零(zero-padding)的数量
: 深度,输出单元的深度
则可以用以下公式计算一个维度(宽或高)内一个输出单元里可以有几个隐藏单元:
如果计算结果不是一个整数,则说明现有参数不能正好适合输入,步幅(stride)设置的不合适,或者需要补零,证明略,下面用一个例子来说明一下。
这是一个一维的例子,左边模型输入单元有5个,即, 边界各补了一个零,即,步幅是1, 即,感受野是3,因为每个输出隐藏单元连接3个输入单元,即,根据上面公式可以计算出输出隐藏单元的个数是:,与图示吻合。右边那个模型是把步幅变为2,其余不变,可以算出输出大小为:,也与图示吻合。若把步幅改为3,则公式不能整除,说明步幅为3不能恰好吻合输入单元大小。

另外,网络的权重在图的右上角,计算方法和普通神经网路一样。
参数共享(Parameter Sharing)
应用参数共享可以大量减少参数数量,参数共享基于一个假设:如果图像中的一点(x1, y1)包含的特征很重要,那么它应该和图像中的另一点(x2, y2)一样重要。换种说法,我们把同一深度的平面叫做深度切片(depth slice)((e.g. a volume of size [55x55x96] has 96 depth slices, each of size [55x55])),那么同一个切片应该共享同一组权重和偏置。我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动, 这里共享权值的梯度是所有共享参数的梯度的总和。
我们不禁会问为什么要权重共享呢?一方面,重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权值共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
卷积(Convolution)
如果应用参数共享的话,实际上每一层计算的操作就是输入层和权重的卷积!这也就是卷积神经网络名字的由来。
先抛开卷积这个概念不管。为简便起见,考虑一个大小为5×5的图像,和一个3×3的卷积核。这里的卷积核共有9个参数,就记为 吧。这种情况下,卷积核实际上有9个神经元,他们的输出又组成一个3×3的矩阵,称为特征图。第一个神经元连接到图像的第一个3×3的局部,第二个神经元则连接到第二个局部(注意,有重叠!就跟你的目光扫视时也是连续扫视一样)。具体如下图所示。
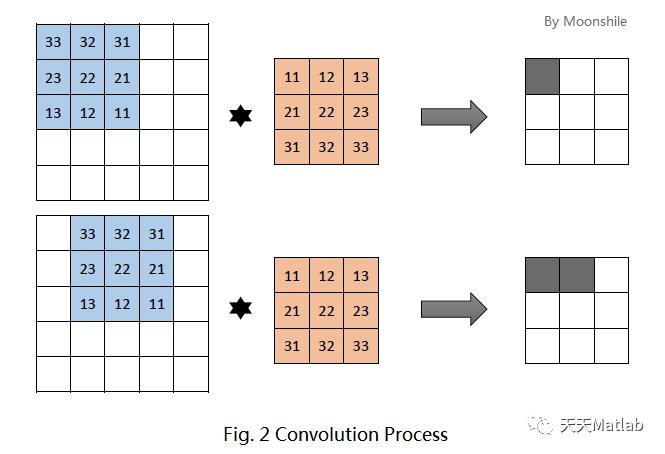
图的上方是第一个神经元的输出,下方是第二个神经元的输出。每个神经元的运算依旧是
需要注意的是,平时我们在运算时,习惯使用 这种写法,但事实上,我们这里使用的是 。
现在我们回忆一下离散卷积运算。假设有二维离散函数 , , 那么它们的卷积定义为
现在发现了吧!上面例子中的9个神经元均完成输出后,实际上等价于图像和卷积核的卷积操作!
Numpy examples
下面用numpy的代码具体的说明一下上面的概念和公式等。
假设输入存储在一个numpy array X里,那么:
* 位于 (x, y) 的 depth column 是 X[x, y, :]
* 深度为 d 的 depth slice 是 X[:, :, d]
假设X的大小是X.shape: (11,11,4),并且不用补零(P = 0),过滤器(感受野)大小F = 5,步幅为2(S= 2)。那么输出单元的空间大小应该为 (11 - 5) / 2 + 1 = 4,即宽和高都为4 。假设输出存储在 V 中,那么它的计算方式应该为:
V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1
注意在numpy中 * 表示两个数组对应元素相乘。
卷积层总结(Summary)
接收三维输入
需要给出4个参数(hyperparameters):
Number of filters ,
their spatial extent ,
the stride ,
the amount of zero padding .
输出一个三维单元 ,其中:
应用权值共享,每个filter会产生 个权重,总共 个权重和 个偏置。
在输出单元,第d个深度切片的结果是由第d个filter 和输入单元做卷积运算,然后再加上偏置而来。
池化层(Pooling Layer)
池化(pool)即下采样(downsamples),目的是为了减少特征图。池化操作对每个深度切片独立,规模一般为 2*2,相对于卷积层进行卷积运算,池化层进行的运算一般有以下几种:
* 最大池化(Max Pooling)。取4个点的最大值。这是最常用的池化方法。
* 均值池化(Mean Pooling)。取4个点的均值。
* 高斯池化。借鉴高斯模糊的方法。不常用。
* 可训练池化。训练函数 ff ,接受4个点为输入,出入1个点。不常用。
最常见的池化层是规模为2*2, 步幅为2,对输入的每个深度切片进行下采样。每个MAX操作对四个数进行,如下图所示: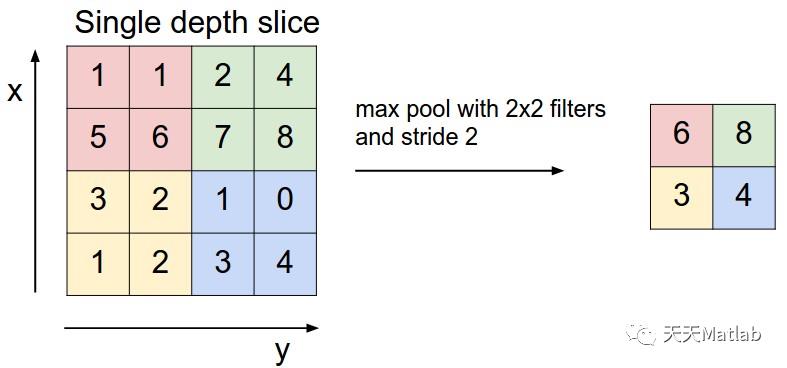
池化操作将保存深度大小不变。
如果池化层的输入单元大小不是二的整数倍,一般采取边缘补零(zero-padding)的方式补成2的倍数,然后再池化。
池化层总结(Summary)
接收单元大小为:
需要两个参数(hyperparameters):
their spatial extent ,
the stride ,
输出大小:,其中:
不需要引入新权重
全连接层(Fully-connected layer)
全连接层和卷积层可以相互转换:
* 对于任意一个卷积层,要把它变成全连接层只需要把权重变成一个巨大的矩阵,其中大部分都是0 除了一些特定区块(因为局部感知),而且好多区块的权值还相同(由于权重共享)。
* 相反地,对于任何一个全连接层也可以变为卷积层。比如,一个 的全连接层,输入层大小为 ,它可以等效为一个 的卷积层。换言之,我们把 filter size 正好设置为整个输入层大小。
卷积神经网络架构
Layer Patterns
常见的卷积神经网络架构是这样的:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
1
堆叠几个卷积和整流层,再加一个池化层,重复这个模式知道图片已经被合并得比较小了,然后再用全连接层控制输出。
上述表达式中 ? 意味着0次或1次,通常情况下:N >= 0 && N <= 3, M >= 0, K >= 0 && K < 3。
比如你可以组合出以下几种模式:
* INPUT -> FC, 实现了一个线性分类器, 这里 N = M = K = 0
* INPUT -> CONV -> RELU -> FC
* INPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC. Here we see that there is a single CONV layer between every POOL layer.
* INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FC Here we see two CONV layers stacked before every POOL layer. This is generally a good idea for larger and deeper networks, because multiple stacked CONV layers can develop more complex features of the input volume before the destructive pooling operation.
Layer Sizing Patterns
Input layer : 应该是2的整数次幂。比如32,64, 128等。
Conv Layer : 使用小的过滤器(filter),, 步幅 ,如果不能恰好拟合输入层,还要边缘补零。如果使用 ,那么输出大小将与输入一样。如果用更大的过滤器(比如7*7),一般只会在紧挨着原始输入图片的卷积层才会看到。
Pool Layer :
三、部分代码
function varargout = cnnMain(varargin)
gui_Singleton = 1;
gui_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn', @cnnMain_OpeningFcn, ...
'gui_OutputFcn', @cnnMain_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);
if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1});
end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
gui_mainfcn(gui_State, varargin{:});
end
function cnnMain_OpeningFcn(hObject, eventdata, handles, varargin)
handles.output = hObject;
guidata(hObject, handles);
movegui(hObject,'center');
function varargout = cnnMain_OutputFcn(hObject, eventdata, handles)
varargout{1} = handles.output;
function LPBut_Callback(hObject, eventdata, handles)
[img_lp,PL]=LPLocation(handles.img_rgb);
axes(handles.axes1); hold on;
row = PL.row;
col = PL.col
plot([col(1) col(2)], [row(1) row(1)], 'g-', 'LineWidth', 3);
plot([col(1) col(2)], [row(2) row(2)], 'g-', 'LineWidth', 3);
plot([col(1) col(1)], [row(1) row(2)], 'g-', 'LineWidth', 3);
plot([col(2) col(2)], [row(1) row(2)], 'g-', 'LineWidth', 3);
hold off;
axes(handles.axes2);
imshow(img_lp);
title('定位图', 'FontWeight', 'Bold');
handles.img_lp=img_lp;
guidata(hObject, handles);
% --------------------------------------------------------------------
function openFile_Callback(hObject, eventdata, handles)
[uuu,vvv]=uigetfile({'*.jpg;*.tif;*.png;*.gif;*.BMP;*.JPEG','All Image Files'} ,'MultiSelect', 'on');%获取一张车牌照片
path=strcat(vvv,uuu);%拼接图片路径
img_rgb=imread(path);
img_rgb=imresize(img_rgb,[240,320]);
axes(handles.axes1);
im = imread(path);
imshow(img_rgb);
title('原图像', 'FontWeight', 'Bold');
handles.img_rgb=img_rgb;
guidata(hObject, handles);
function FGBut_Callback(hObject, eventdata, handles)
functionPath=pwd; %储存现有路径
dataPath=strcat(functionPath,'\CNN\data'); %储存data路径
cnnToolPath=strcat(functionPath,'\CNN\DeepLearnToolbox_CNN_lzbV3.0');
addpath(functionPath)
addpath(dataPath)
addpath(cnnToolPath)
[LP_word]=LPWordDivide(handles.img_lp);
figure
for i=1:7
subplot(1,7,i)
imshow(LP_word(:,:,i));
end
handles.LP_word=LP_word;
guidata(hObject, handles);
% --- Executes on button press in CNNbut.
function CNNbut_Callback(hObject, eventdata, handles)
functionPath=pwd; %储存现有路径
dataPath=strcat(functionPath,'\CNN\data'); %储存data路径
cnnToolPath=strcat(functionPath,'\CNN\DeepLearnToolbox_CNN_lzbV3.0');
addpath(functionPath)
addpath(dataPath)
addpath(cnnToolPath)
if(~exist('trainData.mat','file')||~exist('testData.mat','file')) %检查是否有trainData、testData
%数据自动保存在/data文件夹
[train_x,train_y,test_x,test_y]=dataSet(); %生成数据
else
load trainData
load testData
end
if(~exist('Net.mat','file')) %检查是否有NET
%如果想要重新生成NET,框黑下一句按F9(运行约20分钟)
%网络自动保存在/data文件夹
cd(functionPath)
[net,err,bad]=LPNetTrain(train_x,train_y,test_x,test_y); %训练网络
else
load Net5_3_1.mat
cd(functionPath)
end
lp=cnnff(net,handles.LP_word); %获得车牌字符的神经网络结果
lplabel=lp.Y; %获得字符的标签
[word,position]=label2word(lplabel); %转换为str,word为字符结果,position为对照标签位置
set(handles.AA,'String', word);
% --- Executes on button press in pushbutton4.
function pushbutton4_Callback(hObject, eventdata, handles)
img_gray = rgb2gray(handles.img_lp);
axes(handles.axes4);
imshow(img_gray);
title('灰度图像', 'FontWeight', 'Bold');
function pushbutton5_Callback(hObject, eventdata, handles)
se=[1 1];
img_bimr = imerode(handles.img_rgb, se);
se = strel('rectangle',[1,5]);
img_bimr2 = imdilate(img_bimr, se);
axes(handles.axes5);
imshow(img_bimr2);
title('腐蚀与膨胀', 'FontWeight', 'Bold');
四、运行结果
五、参考文献及代码私信博主
[1]基于卷积神经网络的垃圾分类系统的研究[J]. 汪洋,王小妮,王育新,刘畅,熊继伟,韩定良. 传感器世界. 2020(08)
[2]基于卷积神经网络的智能垃圾分类系统[J]. 吴碧程,邓祥恩,张子憧,唐小煜. 物理实验. 2019(11)
[3]基于计算机视觉的废物垃圾分析与识别研究[J]. 吴健,陈豪,方武. 信息技术与信息化. 2016(10)
以上是关于图像识别基于卷积神经网络(CNN)实现垃圾分类Matlab源码的主要内容,如果未能解决你的问题,请参考以下文章