初创企业的福音,还有这么贴心的云原生数据库?
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初创企业的福音,还有这么贴心的云原生数据库?相关的知识,希望对你有一定的参考价值。

导语 | TDSQL-C 为了满足更高的弹性能力和更精准的计费能力要求,推出了 Serverless 实例的形态,为用户提供更低成本、更灵活的云数据库服务。本文由腾讯云 TDSQL-C 高级工程师杨珏吉在 Techo TVP 开发者峰会 ServerlessDays China 2021 上的演讲《突破极致弹性-腾讯云原生数据库 TDSQL-C Serverless 架构设计与实践》整理而成,向大家分享 TDSQL-C Serverless 的特点以及实现原理。
点击可观看精彩演讲视频
一、Serverless 数据库特点
首先讲 Serverless 数据库的特点。Serverless 分为FaaS(函数即服务)和BaaS(后端即服务),FaaS主要是提供弹性、按使用计费和免运维的计算服务,还有一部分是BaaS。大部分的BaaS产品都能够提供 Serverless 能力,包括对象存储,开发者只要按量计费,以及有足够的弹性能力去扛那些突发的负载。但是目前在云数据库方面,其实并没有做到非常 Serverless 化。开发者在购买云数据库的时候需要指定固定规格,按照规格付费。
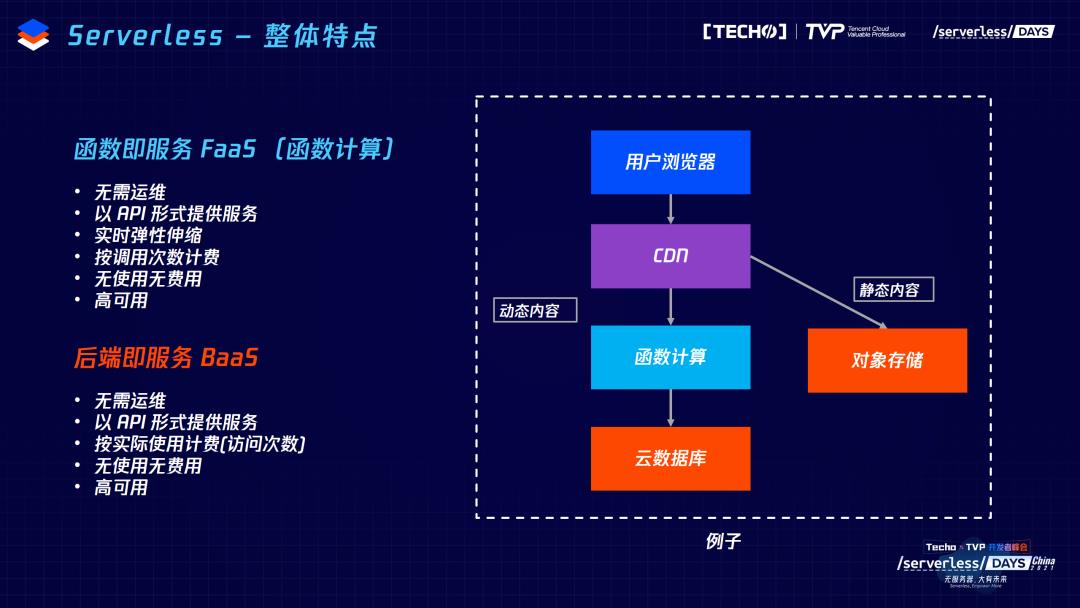
所以,TDSQL-C Serverless 在去年年底发布,补充了MySQL生态下 Serverless 的空缺。开发者不再需要去权衡规格和费用,不用担心过多的扣费,也不用担心购买很小的规格就扛不住突发流量。其实最大的特点是三个,按负载自动扩缩容,进一步以实际负载进行计费,再进一步做到不使用的时候不付费。

二、TDSQL-C 数据库架构
TDSQL-C如何做到以上特点?首先看整体架构,其实TDSQL-C分为两款产品,for mysql、for PostgreSQL。今天主要讲前者,它的整体是计算层和存储层分离的架构,设计原则是尽可能地复用云上组件。计算层用了腾讯云数据库内核团队TXSQL技术,跟社区的MySQL是完全兼容的,且能复用社区版bugfix和特性;主从之间通过redo进行复制;另外,本地不会存数据或者日志文件,日志文件下放到存储层。在存储层上利用了云硬盘基于CBS打造的 HiSTOR 存储平台,保证数据的复制以及GB级的回档能力,以及提供了SSD、混存、多种性能和成本的选择方案。在存储层平台里,我们自己增加了DBStore的组件,来接收计算层的日志、进行数据库的日志回放以及存储,以及提供算子下推的数据库能力。大家如果对数据库不是很了解,也不要被这些名词吓到。使用TDSQL-C之后,跟用MySQL几乎是一致的。只是我们内部做了存储分离,分离之后可以对整个计算层做非常灵活和自由的资源分配,这也是我们实现 Serverless 最重要的基础。
这个图就是应用程序访问TDSQL的整个流程,应用程序通过接入层访问计算层,计算层从存储层获取数据返回给用户。
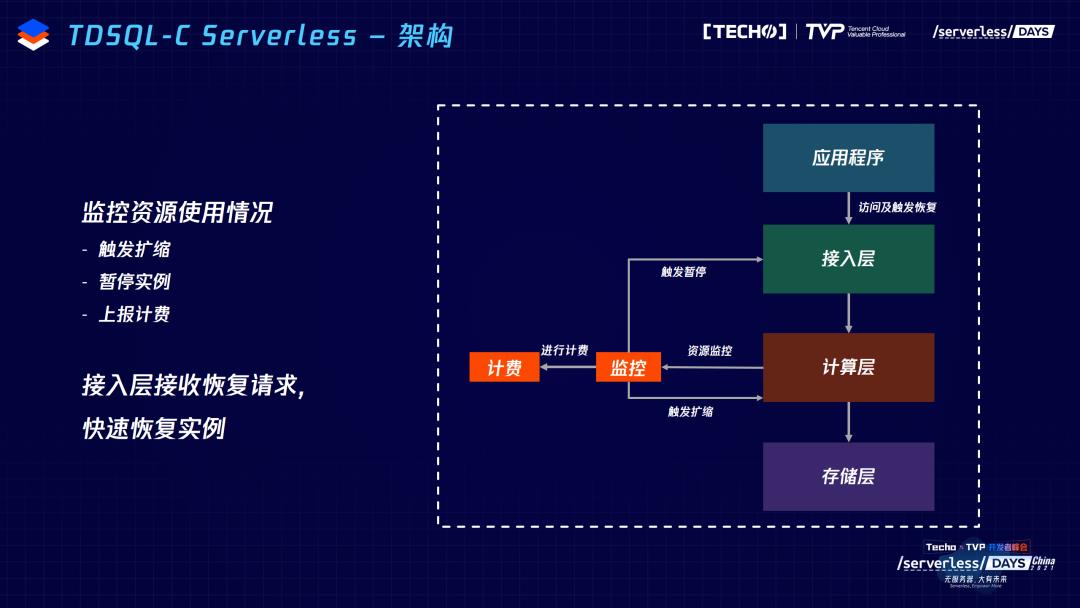
Serverless 是基于监控的方式实现,通过CPU和内存的资源消耗进行计费。如果发现使用资源过多或过少则触发自动扩缩容,没有连接时,会触发暂停的逻辑,就把计算层资源回收,因此不再计费。之后我们会通知这个接入层,MySQL内核已经不再计费,用户访问接入层会触发恢复逻辑。计算层重新恢复之后,提供数据库服务给应用程序。
再提一下之前说的三个特点,自动扩缩容、按使用计费和不使用不计费,如何做到更高要求?
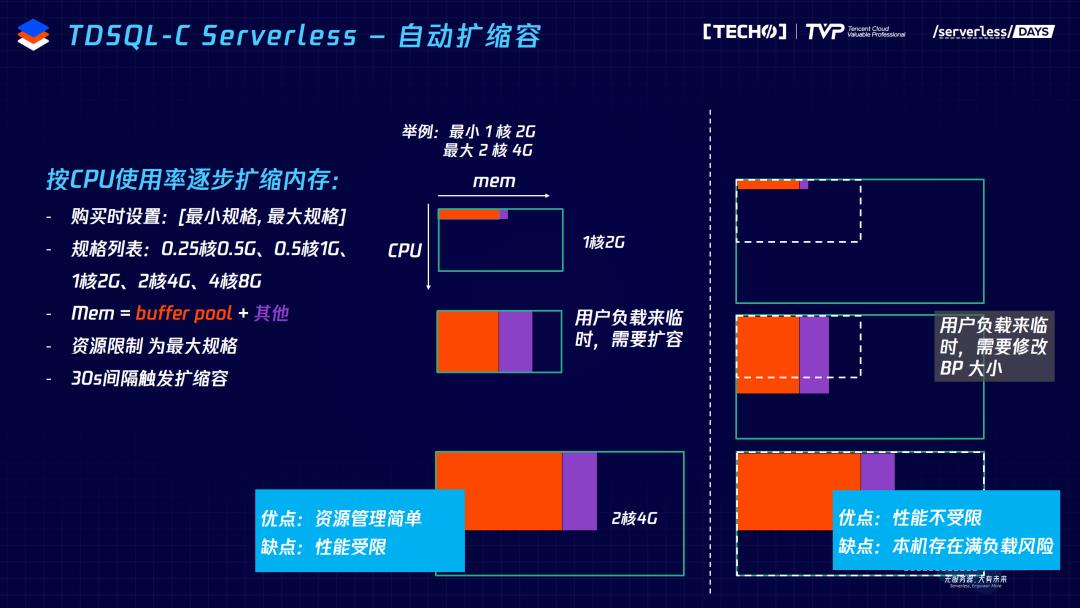
首先,自动扩缩容。我们希望扩缩容速度是秒级的,而且扩缩容的过程是用户无感知的。用户购买一个 Serverless 的时候,需要指定一个扩缩容的范围,最小规格和最大规格,即指定CPU内存资源的概况。比如用户指定一个最小规模1核2G最大规格2核4G,图中纵轴方向是CPU,横轴方向是内存。左边的矩形框是对资源的限制,限制在1核2G的最小规格上。这种方案下,如果用户直接把负载打满,就是用满一核的CPU,此时用户就无法用到更多的CPU。监控发现后,就会扩成2核4G,这时候用户就可以用更多的CPU,内存也可以用得更多。这种方式下的缺点在于存在CPU使用的限制,并不能立刻到最大的CPU。最终我们采用右边的方案,一开始就限定到最大的规格2核4G,用户负载来临的时候,可以直接用到超过一核甚至两核的CPU,我们根据CPU使用量动态扩缩缓存的大小。右边的方案优点在于CPU使用不再受限,可以立刻用到最大的CPU资源。缺点在于存在一个整机满负载的风险,当然通过很多运维手段和智能调度的算法来避免这样的情况发生。
第二点,按使用量计费,我们希望秒级别,而不是目前大部分云数据库提供的是按一小时内最大的规格进行按量计费的方案。另外一个特点,是以任意单位的资源计费,不是不足一核按一核收费,而是用户用了0.6核那就按0.6来收费。我们每5秒采集一次CPU和内存的消耗,根据计算得到的CCU算力进行计费,CPU、内存的二分之一和最小规格取最大值就是算力单位CCU,每一个点都会作为一个小时的帐单的一部分,1小时出一次帐单。以这张图为例,用户刚开始的时候没有任何负载,刚开始是0.25 CCU,也就是最小规格,用户负载来的时候,可能CPU立刻到达3核,内存的调整没有跟上的话,就按照CCU为3计费;当负载过去之后,BG调整慢慢缩小,这时候内存最大,就是按0.8 CCU进行收费。

不使用不收费的话,我们希望做到的是不使用的时候成本极低,从使用到不使用判断的时间非常短。从不使用到使用存在恢复时间,也就是刚才说的冷启动时间,是秒级的。也是因为整个计算存储分离的架构,完成不使用不收费的能力是水到渠成的事情。

运行中的实例,监控发现10分钟没有请求,就会转为暂停的实例,接入层负责接收后续的用户请求。用户请求之后,会迅速地唤起计算进程提供服务。数据库场景下,冷启动优化有很多问题需要解决,比如获取之前的连续日志位点,以及进行BP和事务系统的并行处理化,在内核上以及管控系统上我们做了非常多改进。目前我们的冷启动时间是2秒,在关系型 Serverless 数据库里面目前是领先的,但还是不够,目前还在优化当中。
三、Serverless 数据库应用场景
到底 Serverless 数据库到底可以给用户带来什么?它的落地场景有哪些?这也是用户最关心的。
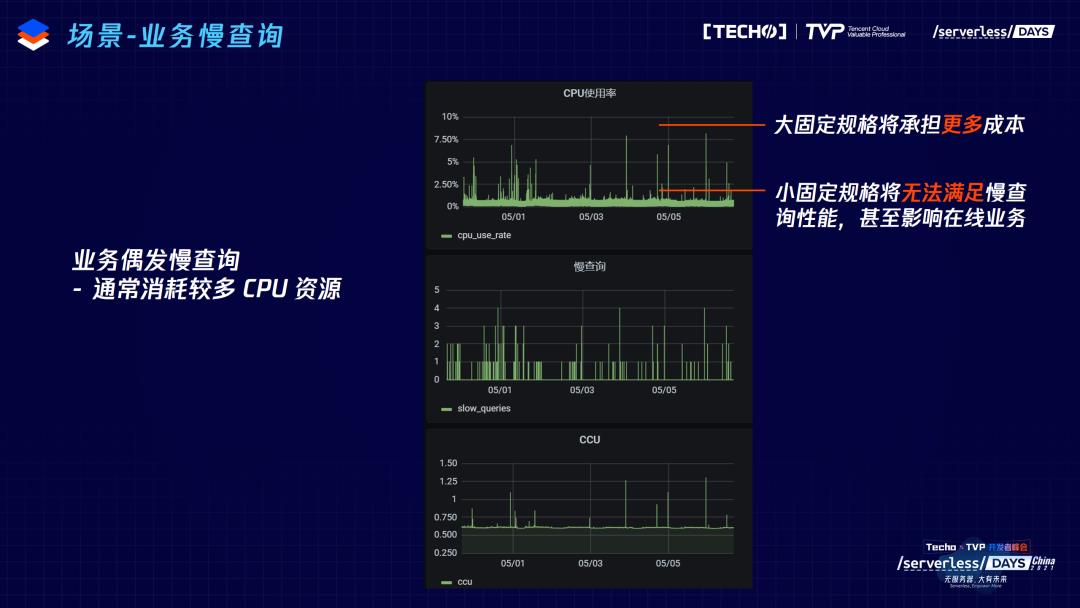
首先第一个场景,慢查询。用过数据库都会有这样的问题,SQL写得不好会带来一些非常慢的请求,另外,业务也会有不可避免地产生报表等的AP场景的查询。这个例子中,用户偶发的慢查询,带来了全表扫描,进而引起CPU的增高,慢查询和CPU从图中看出是正相关的关系。用户想解决慢查询需要购买比较大的规格,如果这样,就会要付出更多的成本,如果购买更小的规格,就满足不了慢查询的需求,处于两难的情况。用户在使用我们的 Serverless 数据库后,可以完全避免这个问题,大部分的情况下以比较低的CCU去进行计费,但是如果慢查询来了,就相应的在慢查询的那个时刻点付更高的费用,整体情况下我们是以非常低的规格去计费的。
第二个场景,定时任务。大部分业务都有定时任务的场景,做前一天数据的清理或者生成前一天数据的报表。这个用户就是在每天凌晨0点的时候,对自己的数据进行分析。每天凌晨请求非常多,因此CPU使用量变得更多,这种场景和刚刚的场景是类似的,购买大规格或小规格,都会面临成本或者性能的问题,但是使用 Serverless 数据库之后,在成本和性能上都是完美的解决方案。
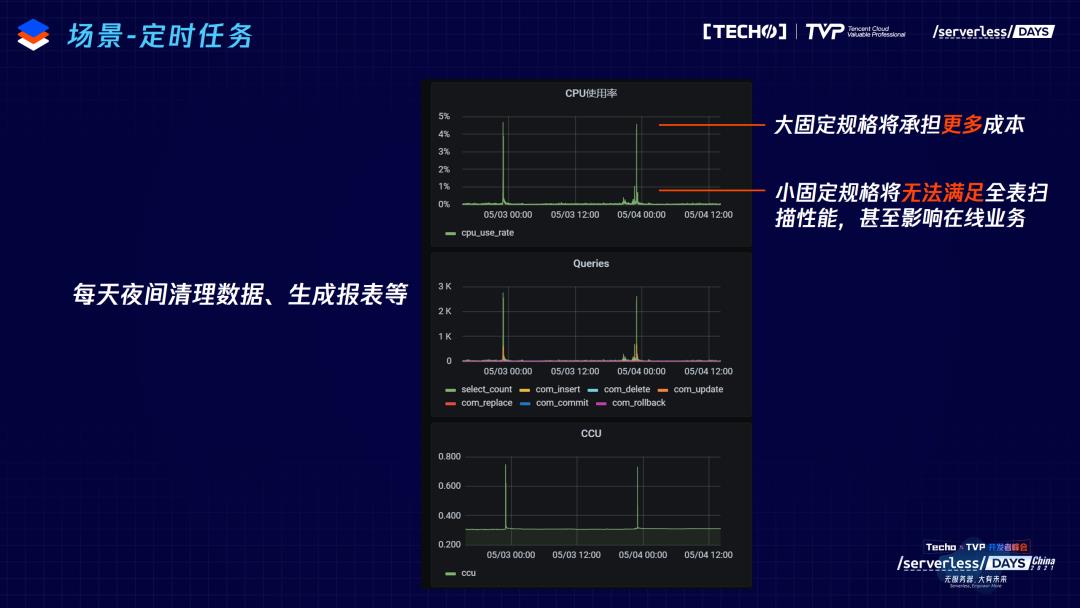
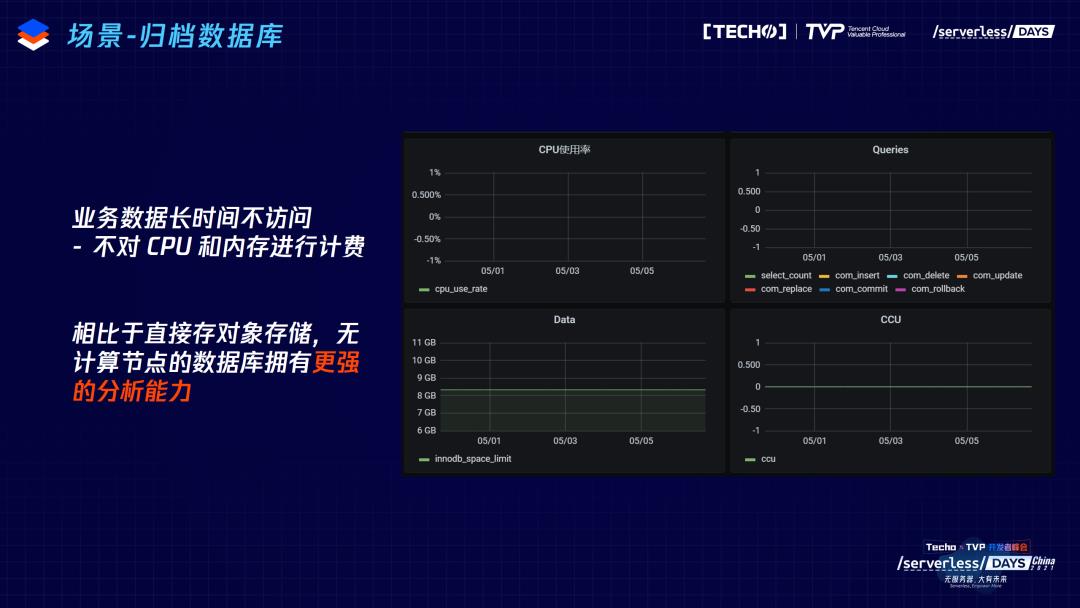
第三个场景,归档数据库。如果长时间不访问数据库,TDSQL-C Serverless 就会回收计算进程,不再对CPU和内存进行计费。档案类的数据库非常适合使用这个特性,比如学校录入学生信息,开学和毕业的时候要集中地获取和修改这些信息,大部分时间数据库是关闭的状态,不用再进行计费。
另外,机器学习场景下,会有很多的采样样本。但是只有在做实验、投论文的前夕会频繁访问,大部分时间不访问这些数据库,这也属于归档类数据库。这种归档数据库,另一个方案就是把数据存在对象存储上。对象存储的方案下,用户需要时把数据下载下来,自己写个脚本解析。而对于 TDSQL-C Serverless 数据方案来说,访问的时候就立刻唤醒计算进程,瞬间就有强大的分析能力,不需要下载并自己临时写脚本去检索数据,熟悉MySQL就能立刻检索数据。
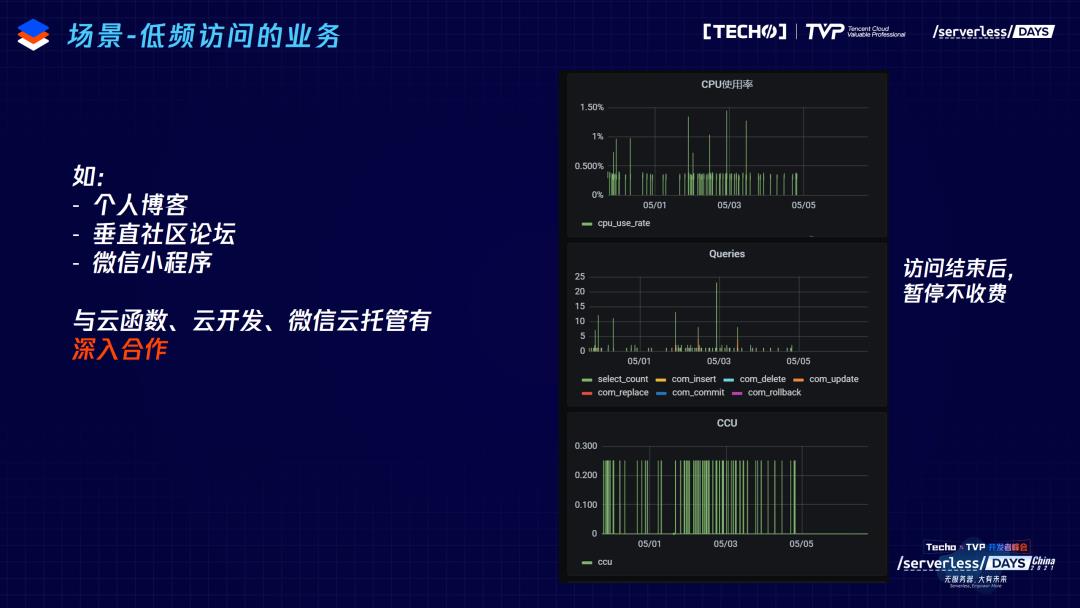
然后是低频的访问业务。这一类的业务的日请求一般少于10个,比如个人博客、垂直论坛、微信小程序,这方面我们也是和云开发、云函数以及微信云托管有深入合作支持一键部署等完整的解决方案,在这些低频访问结束之后,我们暂停实例,对数据库计算资源不再收费。
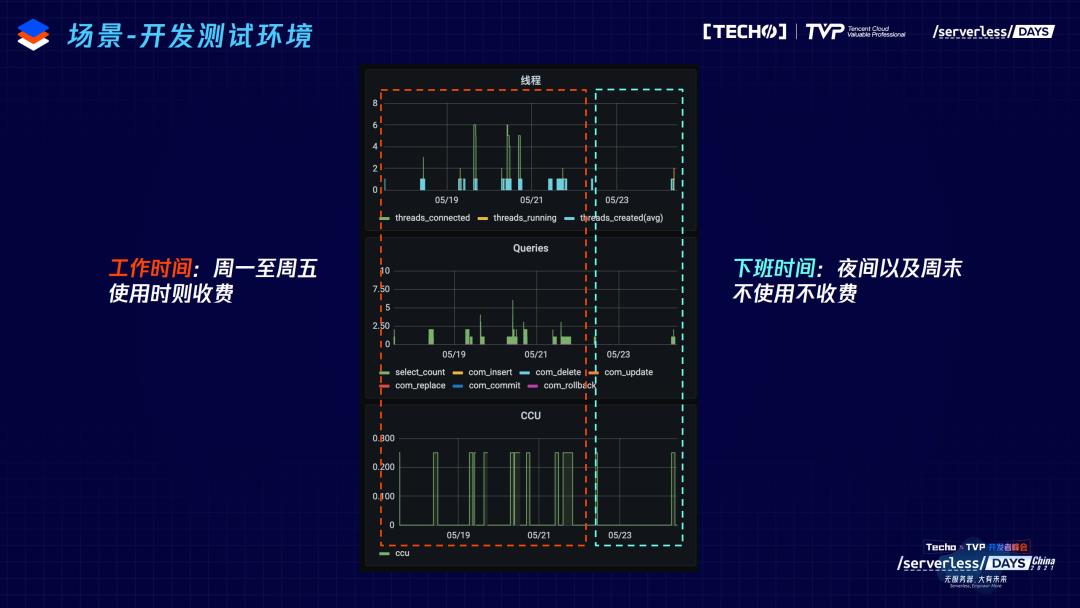
第五,开发测试环境。这个例子中的客户看得出来是一个955的公司,只有在工作时间对数据库进行测试和开发,在中午、晚上以及周末把数据库关闭,不再进行收费,非常灵活,节省开发测试成本,非常低碳。
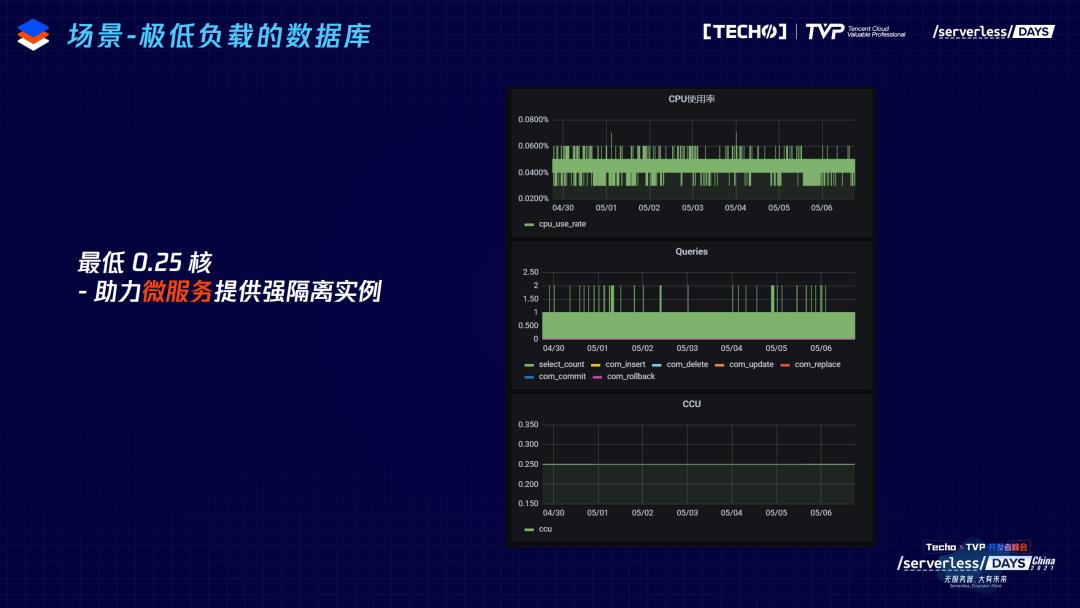
第六,极低负载数据库。目前微服务比较盛行,把整个大系统拆成一个个非常小的微服务,但是服务变小之后,对应数据库的负载会变低。一个常见的方式是很多的微服务访问同一个大的数据库,就会带来微服务之间的隔离性的问题。TDSQL-C Serverless 带来非常小的强隔离的微服务数据库的方案,助力微服务提供稳定的性能。
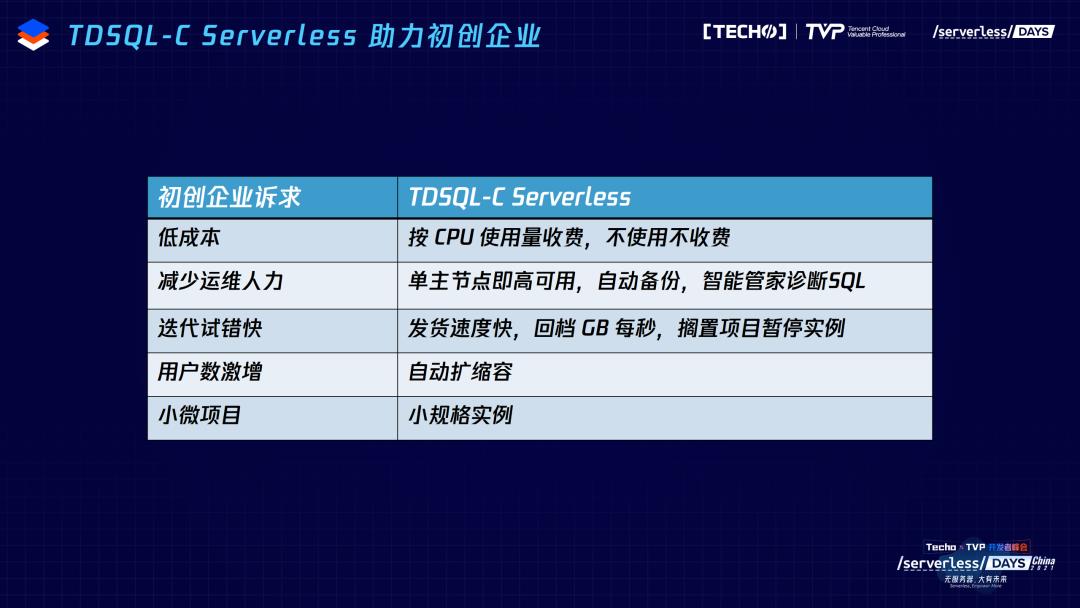
最后,还是要特别提一下,我们想要助力初创企业,初创企业有几个需求:一方面是数据库的低成本,TDSQL-C Serverless 按使用量计费,不使用不收费。另外,人力成本,包括DBA以及运维能力,TDSQL-C Serverless 单主节点即高可用,另外,每天的自动备份,以及智能管家的分析、SQL优化意见,都免去业务自建数据库的维护痛苦。初创企业希望迭代试错快,相应的,我们发货速度非常快,以及GB级每秒的回档能力,可以非常快地创建新的实例。如果这个项目失败了想放弃,可以暂停这个实例,哪天觉得这个项目需要重新开启,可以恢复实例继续使用,保留之前的数据。初创企业很难预测自己用户的激增,所以自动扩缩容能力能非常好地应对这方面的情况。初创企业有小的试水项目,我们也响应提供了小规格实例。
四、总结
总结和展望一下:TDSQL-C Serverless 弥补了 Serverless 领域里关系型数据库的空白,自动扩缩容能做到瞬间最大的使用规格,按使用量计费,能按真实的CPU使用量进行计费,单位秒级别,不使用不收费,冷启动目前是2秒,未来希望在冷启动方面有更多的优化,成本上做到更低。
讲师简介

杨珏吉
腾讯云 TDSQL-C 高级工程师
毕业于浙江大学,现于腾讯担任高级工程师,负责腾讯云 TDSQL-C Serverless 方案设计与后台研发工作。
推荐阅读
用了 Serverless 这么久,这里有其底层技术的一点经验
Serverless + 低代码,让技术小白也能成为全栈工程师?
点击观看峰会的精彩总结视频????
???? 错过了直播懊悔不已?本次峰会所有嘉宾的演讲视频回顾上线啦,点击「阅读原文」即可观看~
???? 看视频不过瘾还想要干货PPT?关注本公众号,在后台回复关键词「serverless」即可获取!

以上是关于初创企业的福音,还有这么贴心的云原生数据库?的主要内容,如果未能解决你的问题,请参考以下文章