HashMap的原理分析
Posted 长江很多号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的原理分析相关的知识,希望对你有一定的参考价值。
码字不易,转载请注明出处:https://blog.csdn.net/newchenxf/article/details/118516553
这是一个考察Java基础知识的题目,面试常用,这里专门整理一下答案和原理分析。
这次我比较过粪,不是由浅入深,而是直接给结论,因为考虑到你打开这个文章,只是来抓紧查一下总结,时间相当紧迫。^^
1. 结论
说结论,改成说HashMap的特点,也不是不可以^^
存储用数组,数组长度为2个倍数,且在数据个数超过0.75倍时,动态扩大
存储/查找 根据hash值找到数组下标,时间复杂度基本为O(1)
线程不安全
key可以为null
2 细化分析
2.1 存储用数组,数组长度为2个倍数,且在数据个数超过0.75倍时,动态扩大
数组的类型是HashMapEntry。这是一个单链表节点的类,放在HashMap的内部,关键定义如下:
//数组的定义
transient HashMapEntry<K, V>[] table;
//定义一个最小数组,MINIMUM_CAPACITY为2
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
//new一个hashmap就会初始化数组
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
//HashMap的静态内部类,static的好处是不持有外部引用
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
}
从类定义可见,除了存基本的key-value,还存一个哈希值(int类型,根据key生成)。这个类还是个链表节点,next变量指向下一个对象,作用等会说。
2.2 存数据流程
存储就是put方法。定义如下:
@Override public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
//根据key生成哈希值,就是一个int,然后做二次哈希算法,输出还是一个哈希int值
int hash = secondaryHash(key.hashCode());
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);//相当于index = hash % tab.length,保证index在长度之内
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);//覆盖老的
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {//threadhold是数组长度的0.75倍,超过就扩容
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);//数组的index赋值
return null;
}
/**
* 数组的index赋值
***/
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
这个put函数,有3个关键点
2.2.1 index的生成
首先,数组不是从0开始存的,而是根据哈希值,随机生成一个index,然后存到index的位置。
index的生成代码抽取如下:
int hash = secondaryHash(key.hashCode());
int index = hash & (tab.length - 1);
private static int secondaryHash(int h) {
// Doug Lea's supplemental hash function
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
先根据key的值,生成一个hashCode,然后用散列函数(也可以认为是一次哈希运算),再次做一次哈希运算(目的是把哈希值打散,这样index就会很分散!当然,不这么做也不是不可以),最后生成了一个int的哈希值,例如110245596。
接着hash & (tab.length - 1); 是什么意思呢?其实,相当于hash % tab.length,即int值除于数组长度,求余数。这依赖的是数学公式:
任意数对2的N次方取模时,等同于其和2的N次方-1作位于运算。
公式表述为:
k % 2^n = k & (2^n - 1)
这样,就可以随机生成index,且index的大小绝对小于数组长度。
那么问题来了,index会不会一样呢?
答案是,会。我特地用了这样一个测试程序验证:
(ps: 你也可以直接在这里运行:https://www.jdoodle.com/online-java-compiler/)
public class MyClass {
private static int secondaryHash(int h) {
// Doug Lea's supplemental hash function
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public static void main(String args[]) {
for(int i = 0; i <16; i++) {
String e1 = new String("temp" +i);
int hash0 = e1.hashCode();
int hash = secondaryHash(hash0);
int size = 16;
int index = hash & (size - 1);
System.out.println("hashCode origin " + hash0 +" hash " +hash +" index " +index);
}
}
}
输出结果是:
hashCode origin 110245596 hash 116809424 index 0
hashCode origin 110245597 hash 116809425 index 1
hashCode origin 110245598 hash 116809426 index 2
hashCode origin 110245599 hash 116809427 index 3
hashCode origin 110245600 hash 116809455 index 15
hashCode origin 110245601 hash 116809454 index 14
hashCode origin 110245602 hash 116809453 index 13
hashCode origin 110245603 hash 116809452 index 12
hashCode origin 110245604 hash 116809451 index 11
hashCode origin 110245605 hash 116809450 index 10
hashCode origin -877353741 hash -963321324 index 4
hashCode origin -877353740 hash -963321325 index 3
hashCode origin -877353739 hash -963321326 index 2
hashCode origin -877353738 hash -963321327 index 1
hashCode origin -877353737 hash -963321328 index 0
hashCode origin -877353736 hash -963321313 index 15
从上可见,index是有可能一样的,比如0, 1, 2, 3,15都重复了。
这种情况,我们称为哈希碰撞
2.2.2 发生哈希碰撞如何存数据
那么,如果index重复了,即发生了哈希碰撞,怎么办呢?这时候,链表的作用体现出来了!
请再看一下addNewEntry函数。
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
这里table[index]虽然用一个新的对象赋值了,但是,这个新的对象,传了一个上一次的table[index]。
我们再来看一下HashMapEntry的构造函数:
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
如果数组的某个index之前有HashMapEntry对象了,那么,重新构造一个新的HashMapEntry对象,会把之前的HashMapEntry对象赋值给新的对象的next。
然后新的对象,存到数组的index中。
所以,最后可能数组的数据形式,样子如下:
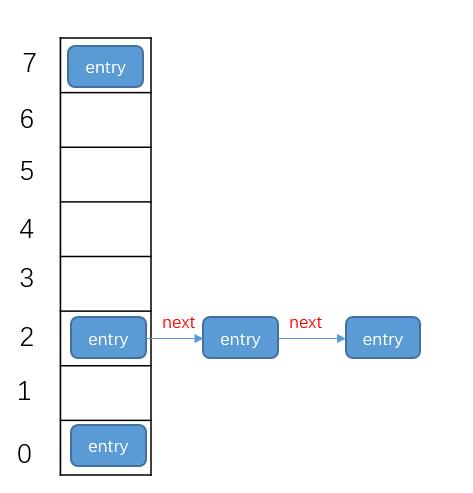
大部分数组的坑位(文明的说法,是bucket,桶),只放1个entry,但个别的坑,有多个entry,以链表形式存在,当然,还有些坑位一直是空的。
这也是为什么,我们在entry的数量达到数组长度的0.75倍时,就要开始扩容的原因。因为,再不扩的话,发生哈希碰撞的概率会越来越大。 而如果数组的每个坑位都碰撞了,就影响查找的效率了!
2.2.3 扩容规则
如前文所说,entry的数量达到数组长度的0.75倍就扩容。
也就是这段代码:
if (size++ > threshold) {//threadhold是数组长度的0.75倍,超过就扩容
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
threadhold是在每次创建新的数组时赋值的:
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}
回到上面的代码,doubleCapacity函数就是具体的扩容代码。具体就做两件事,一是调用makeTable创建新数组,二是把老的数组的数据,迁移到新的数组上!
注意,一个entry在新表(数组)的index,和在老表的index不一样喔。
因为不管是读还是取,index的规则都是
index = hash & (tab.length - 1)。现在length翻倍了,肯定要按新的规则来!
2.3 取数据流程
写数据搞清楚了,读取就简单的多了!
截取代码如下:
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
//计算key对应的哈希值
int hash = secondaryHash(key.hashCode());
HashMapEntry<K, V>[] tab = table;
//根据哈希值,计算index
int index = hash & (tab.length - 1);
//在index的位置上,遍历链表,找到哈希值一样的
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
就两个步骤,一是根据key对应的哈希值,计算出index,二是根据index,读取到对应的entry(链表节点),然后把节点对应的value返回。
2.4 时间复杂度
从上面可知,大部分情况下,一个坑位放一个entry。
get函数,for循环一般一次就可以读取到有效的value。所以时间复杂度,可以说是O(1)
当然了,极端情况下,所有的坑位都空空如也,只有一个坑位,存的链表节点(即entry)有next,链表拉长到数组长度的0.75倍,那时间复杂度就是O(n)了。 但这种一般不会发生。
2.5 线程不安全
之所以说线程不安全,最主要是put函数!
put随时可能扩容,扩容就随时可能操作修改链表。而如果多线程来修改,肯定就乱套了!
所以,如果你需要多线程使用HashMap,那就改用ConcurrentHashMap!
2.6 key可以为null
key可以为null,并不是为了什么高端作用,就是做的兼容性强一些。
如果key传null,则没法计算hashcode了,也就没法算index了,也就没法放到数组里了。所以,HashMap就定义了一个entry成员变量。只要传了是put函数传递的key为空,则就把新建的entry赋值给这个变量。多次put,则新的覆盖老的。
具体代码如下,很简单:
/**
* The entry representing the null key, or null if there's no such mapping.
*/
transient HashMapEntry<K, V> entryForNullKey;
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}
void addNewEntryForNullKey(V value) {
entryForNullKey = new HashMapEntry<K, V>(null, value, 0, null);
}
从代码可见,即使value也想为空,也是可以的。但一般没人会这么干。
参考
以上是关于HashMap的原理分析的主要内容,如果未能解决你的问题,请参考以下文章