快速了解云原生架构
Posted 阿里巴巴云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速了解云原生架构相关的知识,希望对你有一定的参考价值。
作者 | 潘义文(空易)

起源
1. 云原生(Cloud Native)的由来
云原生的概念最早开始于 2010 年,,他一直想用一个词表达一种架构,这种架构能描述应用程序和中间件在云环境中的良好运行状态。因此他抽象出了 Cloud Native 必须包含的属性,只有满足了这些属性才能保证良好的运行状态。当时提出云原生是为了能构建一种符合云计算特性的标准来指导云计算应用的编写。
2. CNCF 基金会成立及云原生概念的演化
2015 年由 Linux 基金会发起了一个,CNCF基金会的成立标志着云原生正式进入高速发展轨道,,并逐步构建出围绕 Cloud Native 的具体工具,而云原生这个的概念也逐渐变得更具体化。因此,CNCF 基金最初对云原生定义是也是深窄的,当时把云原生定位为容器化封装+自动化管理+面向微服务:
The CNCF defines “cloud-native” a little more narrowly, to mean using open source software stack to be containerized, where each part of the app is packaged in its own container, dynamically orchestrated so each part is actively scheduled and managed to optimize resource utilization, and microservices-oriented to increase the overall agility and maintainability of applications.
到了 2017 年, 云原生应用提出者之一的上将云原生的定义概括为 DevOps、持续交付、微服务、容器四大特征,这也成了很多人对 Cloud Native 的基础印象。

而到 2018 年,随着 Service Mesh 的加入,,而这也逐渐成为被大家认可的官方定义:
基于容器、服务网格、微服务、不可变基础设施和声明式 API 构建的可弹性扩展的应用。
基于自动化技术构建具备高容错性、易管理和便于观察的松耦合系统。
构建一个统一的开源云技术生态,能和云厂商提供的服务解耦。

-
第一阶段:容器化封装+自动化管理+面向微服务 -
第二阶段:DevOps、持续交付、微服务、容器 -
第三阶段:DevOps、持续交付、容器、服务网格、微服务、声明式API
3. 对云原生的解构
解读:前面三节都是来自《》这篇文章中。
关键点
1. 微服务
1)优势
敏捷开发帮助我们减少浪费、快速反馈,以用户体验为目标。
持续交付促使我们更快、更可靠、更频繁地改进软件;基础设施即代码(Infrastructure As Code)帮助我们简化环境的管理。
2)什么时候开始微服务架构
几乎所有成功的微服务架构都是从一个巨大的单体架构开始的,并且都是由于单体架构太大而被拆分为微服务架构。
在所一开始就构建微服务架构的故事中,往往都有人遇到了巨大的麻烦。
3)如何决定微服务架构的拆分粒度
4)单体架构 VS 微服务架构对比

2. 敏捷基础设施及公共基础服务
1)敏捷基础设施的目标
-
标准化:所有的基础设施最好都是标准的。 -
可替换:任意节点都能够被轻易地创建、销毁、替换。 -
自动化:所有的操作都通过工具自动化完成,无须人工干预。 -
可视化:当前环境要做到可控,就需要对当前的环境状况可视。 -
可追溯:所有的配置统一作为代码进行版本化管理,所有的操作都可以追溯。 -
快速:资源申请及释放要求秒级完成,以适应弹性伸缩和故障切换的要求。
2)基于公共基础服务的平台化
平台化是指利用公共基础服务提升整体架构能力。
公共基础服务是指与业务无关的、通用的服务,包括监控服务、缓存服务、消息服务、数据库服务、负载均衡、分布式协调、分布式任务调度等。
3)常见的平台服务
-
监控告警服务 -
分布式消息中间件服务 -
分布式缓存服务 -
分布式任务调度服务
3. 分布式架构 - 可用性设计
1)什么降低了可用性
发布
故障
压力
外部依赖
2)设计阶段考虑如下几个比较重要的方法
-
20/10/5,设计系统的时候,以实际流量的 20 倍来设计;开发系统的时候,以实际流量的 10 倍来开发系统;发布系统的时候,以实际流量的 5 倍来部署。这只是一个通用的原则,可以根据实际情况来确定,不需要严格按照倍数来执行。 -
Design for failure,预测可能发生的问题,做好预案。
3)容错设计
-
消除单点 -
特性开关 -
服务分级 -
降级设计 -
超时重试
4)隔离策略
-
线程池隔离 -
进程隔离 -
集群隔离 -
用户隔离 -
租户隔离 -
逻辑隔离 -
物理隔离 -
混合隔离
5)熔断器
6)流控设计
-
限流算法。限流也就是调节数据流的平均速率,通过限制速率保护自己,常见的算法有: -
固定窗口算法(fixed window)。 -
漏桶算法(Leaky Bucket):漏桶算法主要目的是控制数据注入网络的速率,平滑网络上的突发流量。 -
令牌桶算法(token bucket):令牌桶控制的是一个时间窗口内通过的数据量,通常我们会以 QPS、TPS 来衡量。
-
流控策略 请求入口处。
业务服务入口处。
公共基础服务处。
基于 Guava 限流:Guava 是 Google 提供的 Java 扩展类库,其中的限流工具类 RateLimiter 采用的就是令牌桶算法,使用起来非常简单。
基于 nginx 限流。
7)容量预估
8)故障演练
-
随机关闭生产环境中的实例。 -
让某台机器的请求或返回变慢,观察系统的表现,可以用来测试上游服务是否有服务降级能力,当然如果响应时间特别长,也就相当于服务不可用。 -
模拟 AZ 故障,中断一个机房,验证是否跨可用区部署,业务容灾和恢复的能力。 -
查找不符合最佳实践的实例,并将其关闭。
9)数据迁移
-
逻辑分离,物理不分离。 -
物理分离 。
4. 分布式架构 - 可扩展设计
-
水平扩展,指用更多的节点支撑更大量的请求。 -
横向扩展通常是为了提升吞吐量,响应时间一般要求不受吞吐量影响即可。
1)AKF 扩展立方体


2)如何扩展数据库
-
X 轴扩展——主从复制集群 -
Y 轴扩展——分库、垂直分表 -
Z 轴扩展——分片(sharding)
5. 分布式架构 - 性能设计
性能指标
-
响应时间(Latency),就是发送请求和返回结果的耗时。 -
吞吐量(Throughput),就是单位时间内的响应次数。 -
负载敏感度,是指响应时间随时间变化的程度。例如,当用户增加时,系统响应时间的衰减速度。 -
可伸缩性,是指向系统增加资源对性能的影响。例如,要使吞吐量增加一倍,需要增加多少服务器。
1)如何树立目标

通过缓存提升读性能。
通过消息中间件提升写性能。
6. 分布式架构 - 一致性设计
1)事务的四大特征
-
原子性(Atomicity)。 -
一致性(Consistency)是指通过事务保证数据从一种状态变化到另一种状态。 -
隔离性(Isolation)是指事务内的操作不受其他操作影响,当多个事务同时处理同一个数据的时候,多个事务之间是互不影响的。 -
持久性(Durability)是指事务被提交后,应该持久化,永久保存下来。
2)CPA 定理
-
一致性(Consistence) -
可用性(Availability) -
分区容错性(Partition tolerance)
3)BASE 理论
-
BA:Basically Available,基本可用。 -
S:Soft state,软状态。 -
E:Eventually consistent,最终一致。
4)Quorum 机制(NWR 模型)
5)租约机制(Lease)
6)脑裂问题
-
一种是采用投票机制(Paxos 算法)。 -
一种是采用租约机制——Lease,租约机制的核心就是在一定时间内将权力下放。
7)分布式系统的一致性分类
-
建立多个副本。可以把副本放到不同的物理机、机架、机房、地域,当一个副本失效时,可以让请求转到其他副本。 -
对数据进行分区。复制多个副本解决了读的性能问题,但是无法解决写的性能问题。
8)以数据为中心的一致性模型
-
严格一致性(Strict Consistency) -
顺序一致性(Sequential Consistency) -
因果一致性(Causal Consistency)
9)以用户为中心的一致性模型
-
单调读一致性(Monotonic-read Consistency) -
单调写一致性(Monotonic-write Consistency) -
写后读一致性(Read-your-writes Consistency) -
读后写一致性(Writes-follow-reads Consistency)
10)业界常用的一致性模型
-
弱一致性:写入一个数据 a 成功后,在数据副本上可能读出来,也可能读不出来。不能保证每个副本的数据一定是一致的。 -
最终一致性(Eventual Consistency):写入一个数据 a 成功后,在其他副本有可能读不到 a 的最新值,但在某个时间窗口之后保证最终能读到。 -
强一致性(Strong Consistency):数据 a 一旦写入成功,在任意副本任意时刻都能读到 a 的最新值。
11)如何实现强一致性
-
两阶段提交 -
三阶段提交(3PC)
12)如何实现最终一致性
-
重试机制:超时时间,重试的次数,重试的间隔时间,重试间隔时间的衰减度。 -
本地记录日志。 -
可靠事件模式。 -
Saga 事务模型:又叫 Long-running-transaction,核心思想是把一个长事务拆分为多个本地事务来实现,由一个 Process manager 统一协调。 -
TCC 事务模型:两阶段提交是依赖于数据库提供的事务机制,再配合外部的资源协调器来实现分布式事务。TCC(Try Confirm Cancel)事务模型的思想和两阶段提交虽然类似,但是却把相关的操作从数据库提到业务中,以此降低数据库的压力,并且不需要加锁,性能也得到了提升。
7. 十二因素
-
基准代码,一份基准代码,多份部署,使用 GIT 或者 SVN 管理代码,并且有明确的版本信息。 -
依赖,显示声明依赖。 -
配置:环境中存储配置。 -
后端服务:把后端服务当作附加资源。后端服务是指程序运行所需要的通过网络调用的各种服务,如数据库(mysql、CouchDB)、消息/队列系统(RabbitMQ、Beanstalkd)、SMTP 邮件发送服务(Postfix),以及缓存系统(Memcached)。 -
构建、发布、运行:严格分离构建和运行。 -
进程,以一个或多个无状态进程运行应用,如果存在状态,应该将状态外置到后端服务中,例如数据库、缓存等。 -
端口绑定,通过端口绑定提供服务,应用通过端口绑定来提供服务,并监听发送至该端口的请求。 -
并发,通过进程模型进行扩展,扩展方式有进程和线程两种。进程的方式使扩展性更好,架构更简单,隔离性更好。线程扩展使编程更复杂,但是更节省资源。 -
易处理,快速启动和优雅终止可最大化健壮性,只有满足快速启动和优雅终止,才能使服务更健壮。 -
开发环境与线上环境等价,尽可能保持开发、预发布、线上环境相同。 -
日志,把日志当作事件流,微服务架构中服务数量的爆发需要具备调用链分析能力,快速定位故障。 -
管理进程,把后台管理任务当作一次性进程运行,一些工具类在生产环境上的操作可能是一次性的,因此最好把它们放在生产环境中执行,而不是本地。
8. 研发流程
1)为什么选择 DevOps

2)Gartner 提出的 DevOps 模型
3)自动化测试
-
自动化测试可以代替人工测试。 -
测试成了全栈工程师的工作,因为不沟通才是最有效率的沟通。
4)Code Review
-
提升代码易读性。 -
统一规范、标准。 -
技术交流,提升能力。 -
Code Review 原则:以发现问题为目标,团队开放、透明,整个 Code Review 的过程对事不对人,不设置惩罚。 -
线上线下接合的方式,长期线上,定期线下。
5)流水线
6)开发人员自服务
-
高覆盖率的自动化测试 -
全面的监控 -
持续交付流水线 -
敏捷基础设施 -
自动化/智能化运维 -
好的架构 -
全栈工程师 -
服务型管理 -
工程师文化 -
信任文化 -
分享文化
7)代码即设计
模糊敏捷研发流程阶段性:业务需求太多和技术变化速度太快。
整个进化设计需要简单的架构+持续集成+重构+整个研发流程设计。
9. 团队文化
1)团队规模导致的问题
-
缺乏信任。由于人数众多,难于管理,只能通过制度、流程、规范、绩效约束。 -
没有责任感。高层管理者忙着开各种决策会议。 -
部门墙。跨部门协调还不如与第三方合作。 -
不尊重专业人士。当所有的生杀大权都掌握在少数人手中的时候。 -
管理层级太深。管理层级太深导致的问题很多。
2)组织结构 - 康威定律
-
第一定律 :Communication dictates design,即组织沟通方式会通过系统设计呈现。 -
第二定律 :There is never enough time to do something right,but there is always enough time to do it over,即时间再多,一件事情也不可能做得完美,但总有时间做完一件事情。 -
第三定律 :There is a homomorphism from the linear graph of a system to the linear graph of its design organization,即线型系统和线型组织架构间有潜在的异质同态特性。 -
第四定律 :The structures of large systems tend to disintegrate during development,qualitatively more so than with small systems,即大的系统组织总是比小系统更倾向于分解。
3)“沟通漏斗”是指工作中团队沟通效率下降的一种现象

4)环境氛围
-
公开透明的工作环境. -
学习型组织:让团队拥有共同愿景、目标,并持续学习。 -
减少无效的正式汇报。 -
高效的会议:缩小会议范围,常规会议不应该超过 45 分钟;限制“意见领袖”的发言时长;会议中不允许开小差;会议中的分歧不应该延伸到会议之外。
10. Serverless
-
全托管的计算服务,客户只需要编写代码构建应用,无需关注同质化的、负担繁重的基础设施开发、运维、安全、高可用等工作。 -
通用性,结合云 BaaS API 的能力,能够支撑云上所有重要类型的应用。 -
自动的弹性伸缩,让用户无需为资源使用提前进行容量规划。 -
按量计费,让企业使用成本得有效降低,无需为闲置资源付费。
Serverless 不足的地方:
-
成功案例太少 -
很难满足个性化 -
缺乏行业标准 -
初次访问性能差 -
缺乏开发调试工具
11. Service Mesh 技术
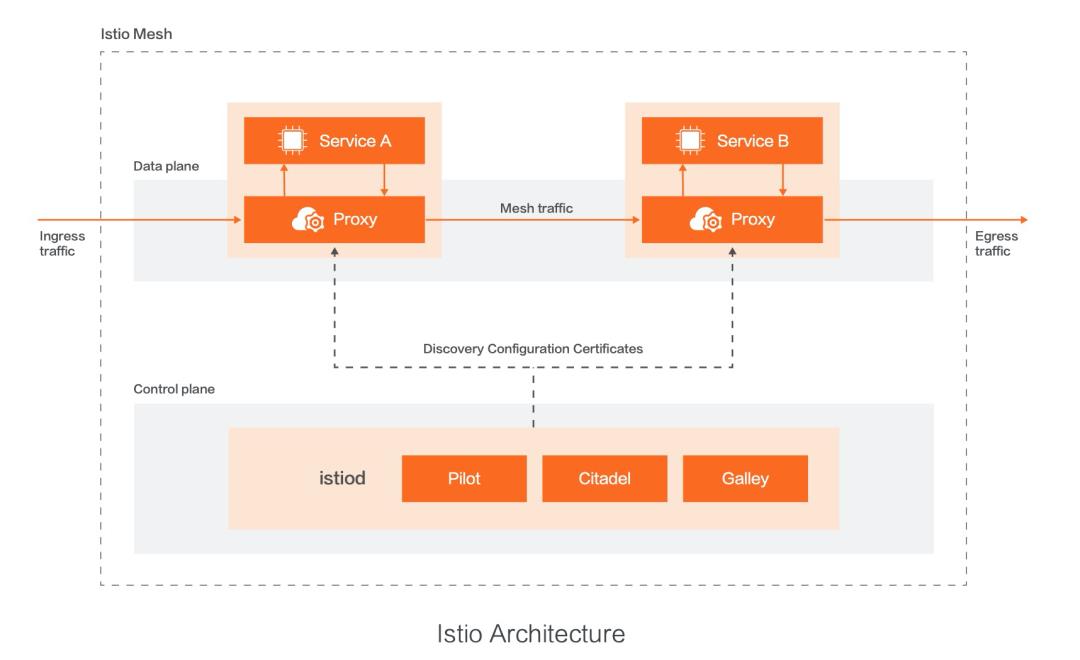
-
在微服务架构中,让开发人员感觉不到微服务之间的通信。 -
当服务数量越来越多,升级微服务框架变得越来越复杂的时候,微服务框架不可能一直不变且没有 bug。 -
Service Mesh 则从业务进程集成客户端的方式演进为独立进程的方式,客户端变成了一个独立进程。 -
对这个独立进程升级、运维要比绑在一起强得多。 -
微服务架构更强调去中心化、独立自治、跨语言。Service Mesh 通过独立进程的方式进行隔离,低成本实现跨语言。 -
每个服务独立占用一个容器,将服务、依赖包、操作系统、监控运维所需的代理打包成一个镜像。这种模式促成了 Service Mesh 的发展,让 Service Mesh 实现起来更容易。
12. 云原生架构成熟度模型


现状
-
全球云原生开发人员超过 470 万。 -
使用 Kubernetes 的开发人员超过 170 万。 -
使用 Serverless 架构及云函数的开发人员超过 330 万。 -
Kubernetes 用户更有可能影响购买决策。
1. 市场规模
2. 各个国家及地区的情况
3. 云原生开发人员掌握多种基础架构
4. 云的使用在各个行业各不相同
未来
1. 容器技术发展趋势

1)趋势一:无处不在的计算催生新一代容器实现
2)趋势二:云原生操作系统开始浮现


3)趋势三:Serverless 容器技术逐渐成为市场主流
4)趋势四:动态、混合、分布式的云环境将成为新常态
2. 基于云原生的新一代应用编程界面
-
Sidecar 架构彻底改变了应用的运维架构 。由于 Sidecar 架构支持在运行时隔离应用容器与其他容器,因此 原本在虚拟机时代和业务进程部署在一起的大量运维及管控工具都被剥离到独立的容器里进行统一管理。对于应用来说,仅仅是按需声明使用运维能力,能力实现成为云平台的职责。
-
应用生命周期全面托管 。在容器技术基础上,应用进一步描述清晰自身状态(例如通过 Liveness Probe), 描述自身的弹性指标以及通过 Service Mesh 和 Serverless 技术将流量托管给云平台。云平台能够全面管理应用的生命周期,包括服务的上下线、版本升级、完善的流量调配、容量管理等保障业务稳定性。
-
用声明式配置方式使用云服务 。云原生应用的核心特点之一就是大量依赖云服务(包括数据库、缓存、消息等) 构建,以实现快速交付。
-
语言无关的分布式编程框架成为一种服务 。为了解决分布式带来的技术挑战,传统中间件需要在客户端 SDK 编写大量的逻辑管理分布式的状态。我们看到很多项目在把这些内容下沉到 Sidecar 中,并通过语言无关的 API (基于 gRPC/HTTP) 提供给应用。这一变化进一步简化应用代码逻辑和应用研发的职责,例如配置绑定,身份认证和鉴权都可以在 Sidecar 被统一处理。
Sidecar 架构模式

3. Serverless 发展趋势
1)趋势一:Serverless 将无处不在
2)趋势二:Serverless 将通过事件驱动的方式连接云及其生态中的一切
3)趋势三:Serverless 计算将持续提高计算密度,实现最佳的性能功耗比和性能价格比
4. 参考文献
更多企业落地实践内容,可下载云原生架构白皮书了解详情!点击【阅读原文】即可下载!
以上是关于快速了解云原生架构的主要内容,如果未能解决你的问题,请参考以下文章