kubernetes日志采集工具log-pilot使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes日志采集工具log-pilot使用相关的知识,希望对你有一定的参考价值。
参考技术A github地址log-pilot官方介绍
log-pilot镜像地址
log-pilot官方搭建
log-pilot解决问题:
kubernetes1.15以上版本
官方tomcat实例
在本方案的 Elasticsearch 场景下,环境变量中的 name即是 catalina 和 access 。
Log-Pilot 支持声明式日志配置,可以依据容器的 Label 或者 ENV 来动态地生成日志采集配置文件。这里重点说明两个变量:
Log-Pilot 也支持自定义Tag,我们可以在容器的标签或者环境变量里配置 aliyun.logs.$name.tags: k=v ,那么在采集日志的时候也会将 k=v 采集到容器的日志输出中。
比如我们有一种场景,有一个开发环境和测试环境,应用日志都会被采集到统一的一个日志存储后端,假设是一个 ElasticSearch 集群,但是我们在 ElasticSearch 中查询日志的时候又想区分出来,具体某条日志记录到底来源于生产环境,还是测试环境。
那么我们就可以通过给测试环境的容器打上 stage=dev 的 tag,给生产环境的容器打上 stage=pro 的 tag,Log-Pilot 在采集容器日志的时候,同时会将这些 tag 随容器日志一同采集到日志存储后端中,那么当我们在查询日志的时候,就可以通过 stage=dev 或者 stage=pro 能明确地区分出某条日志是来源于生产环境的应用容器所产生,还是测试环境应用容器所产生的。另外通过自定义 tag 的方式我们还可以进行日志统计、日志路由和日志过滤。
这里假设一种场景,我们同时有一个生产环境和一个测试环境,应用日志都需要被采集到同一套 Kafka 中,然后由不同的 consumer 去消费。
但是我们同样希望区分出来,某条日志数据是由生产环境的应用容器产生的,还是测试环境的应用容器产生的,但我们在测试环境中的应用容器已经配置了 aliyun.logs.svc=stdout 标签,那么当这些应用容器的标准输出日志被采集到 kafka 中,它最终会被路由到 topic=svc 的消息队列中,那么订阅了 topic=svc 的 consumer 就能够接收测试环境的应用容器产生的日志。
但当我们将该应用发布到生产环境时,希望它产生的日志只能交由生产环境的 consumer 来接收处理,那么我们就可以通过 target 的方式,给生产环境的应用容器额外定义一个 target=pro-svc ,那么生产环境的应用日志在被采集到 Kafka 中时,最终会被路由到 topic 为 pro-svc 的消息队列中,那么订阅了 topic =pro-svc 的 consumer 就可以正常地接收到来自于生产环境的容器产生的日志。
因此这里的 target 本身也有三种含义:
Log-Pilot 也支持多种日志解析格式,通过 aliyun.logs.$name.format: <format> 标签就可以告诉 Log-Pilot 在采集日志的时候,同时以什么样的格式来解析日志记录。目前主要支持六种:
目前 Log-Pilot 支持两种采集插件:一个是CNCF社区的Fluentd插件,一个是Elastic的Filebeat插件;其同时其支持对接多种存储后端,目前 Fluentd 和 Filebeat 都支持 Elasticsearch、Kafka、File、Console 作为日志存储后端,而 Fluentd 还支持 Graylog、阿里云日志服务 以及 Mongodb 作为存储后端。
验证环境
kubernetes16.3
elk6.8.4
log-pilot0.9.6/0.9.7-filebeat
其实是只有filebeat版本,加容器环境变量才能用。fluentd采集不到日志。
用容器标签,日志根本没有方式出去
不管是标签还是环境变量,都不启作用,设置tags后就发送不出日志
kubernetes 的EFK 部署日志管理工具
kubernetes 的EFK 部署
标签(空格分隔): kubernetes系列
一: kubernetes 的EFK 部署
一: kubernetes 的EFK 部署
1.1 关于pod的日志信息
cd /var/log/containers/
ls
ls -lrt *
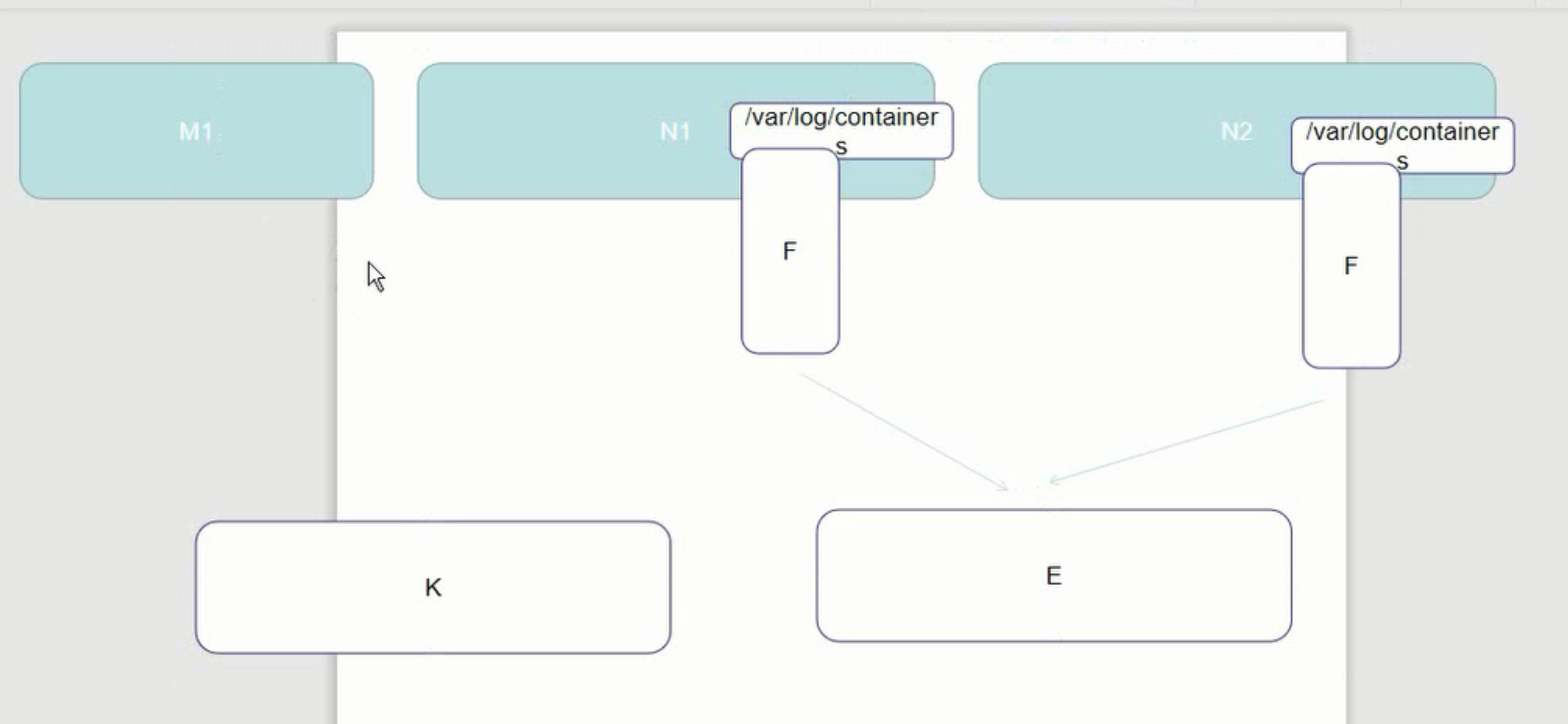
1.2 kubernetes 的EFK 部署
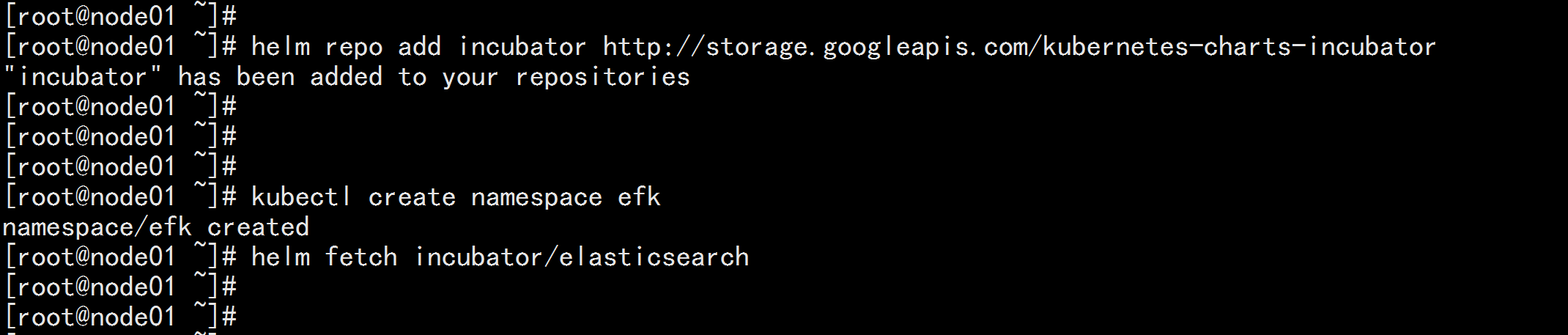
添加 Google incubator 仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator

部署 Elasticsearch
上传ES的镜像到所有节点
elasticsearch-oss.tar fluentd-elasticsearch.tar kibana.tar 三个镜像包
docker load -i elasticsearch-oss.tar
docker load -i fluentd-elasticsearch.tar
docker load -i kibana.tar
----
kubectl create namespace efk
helm fetch incubator/elasticsearch
下载elasticsearch-1.10.2.tgz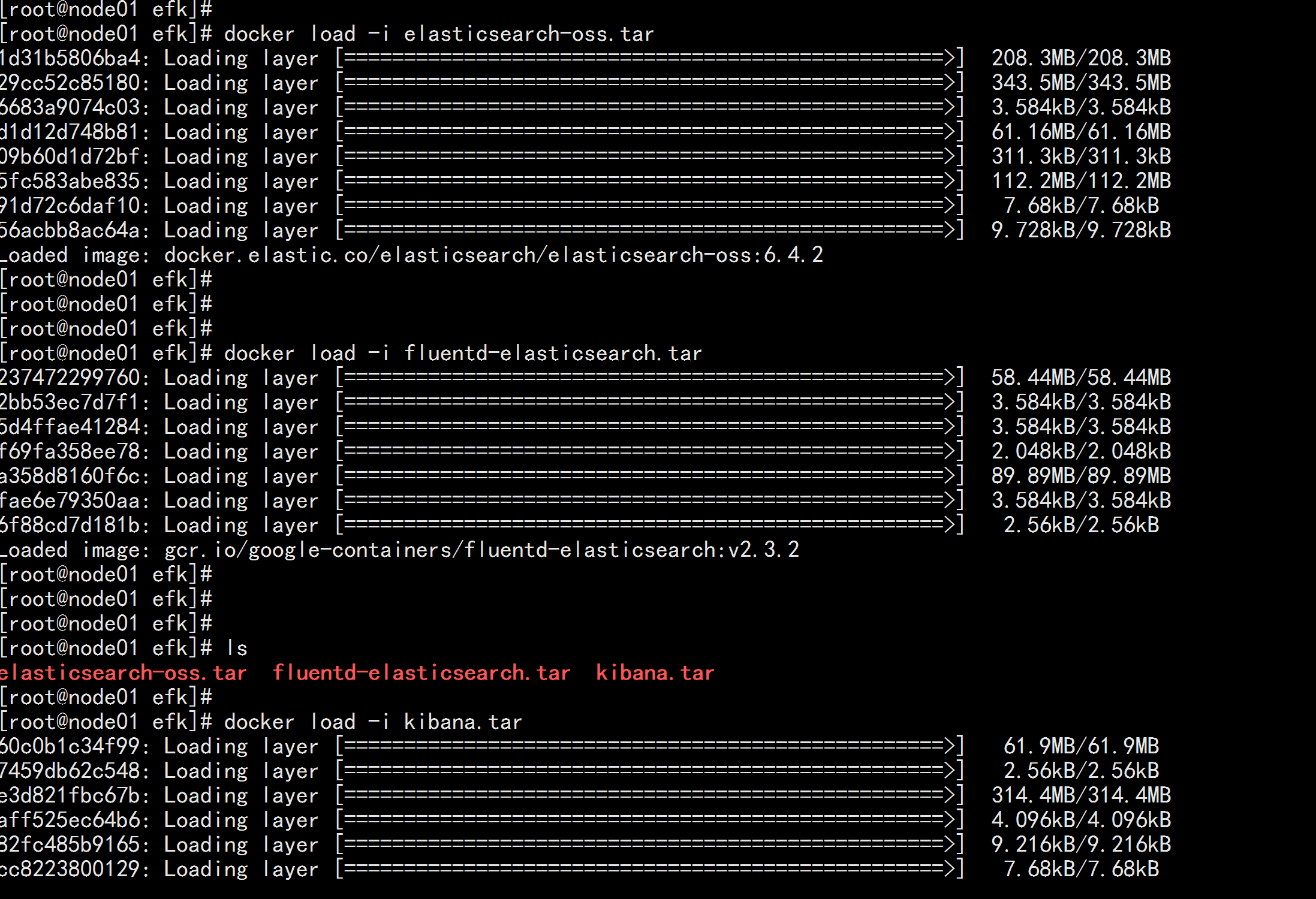
tar -zxvf elasticsearch-1.10.2.tgz
cd elasticsearch
vim values.yaml
修改
----
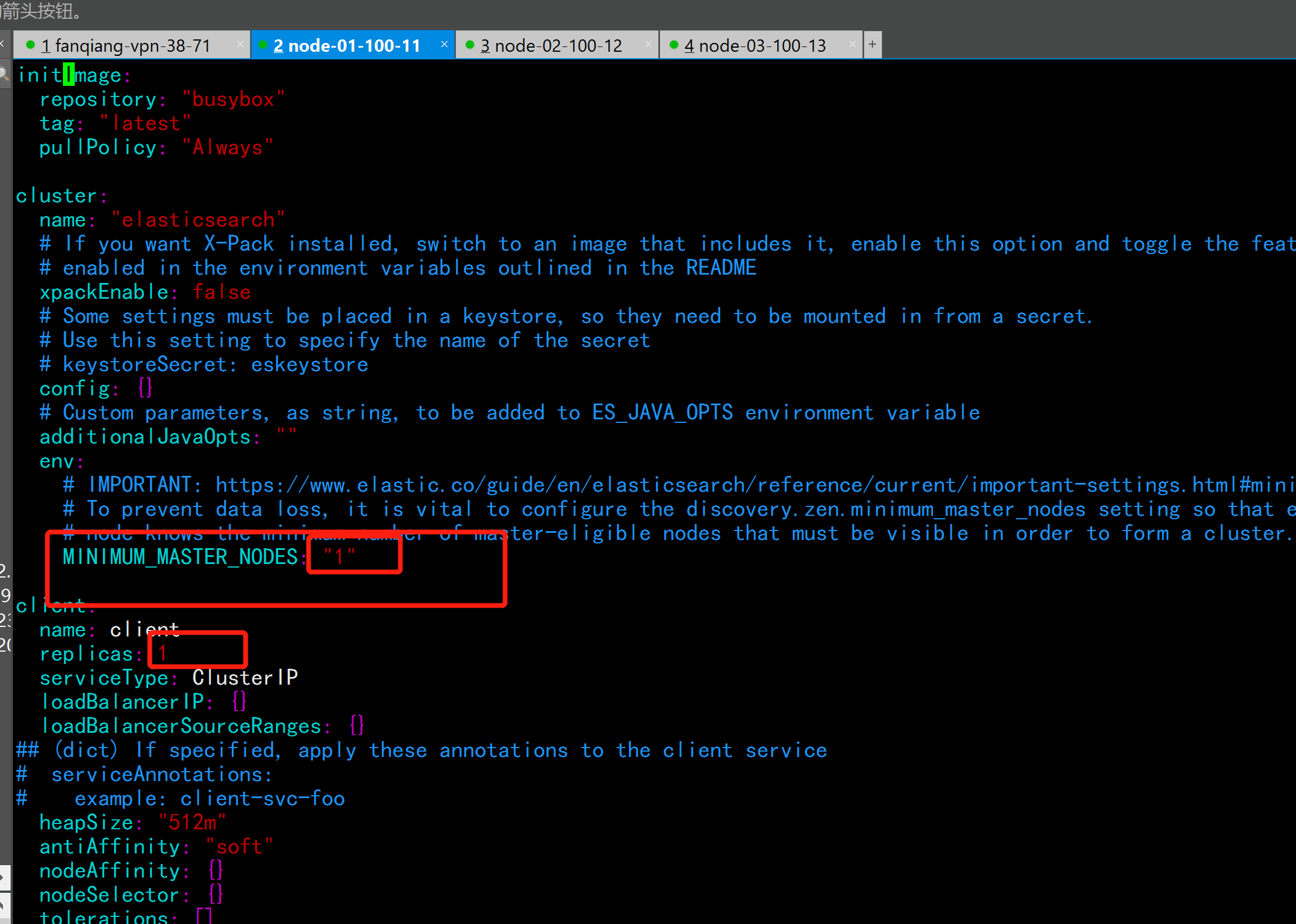
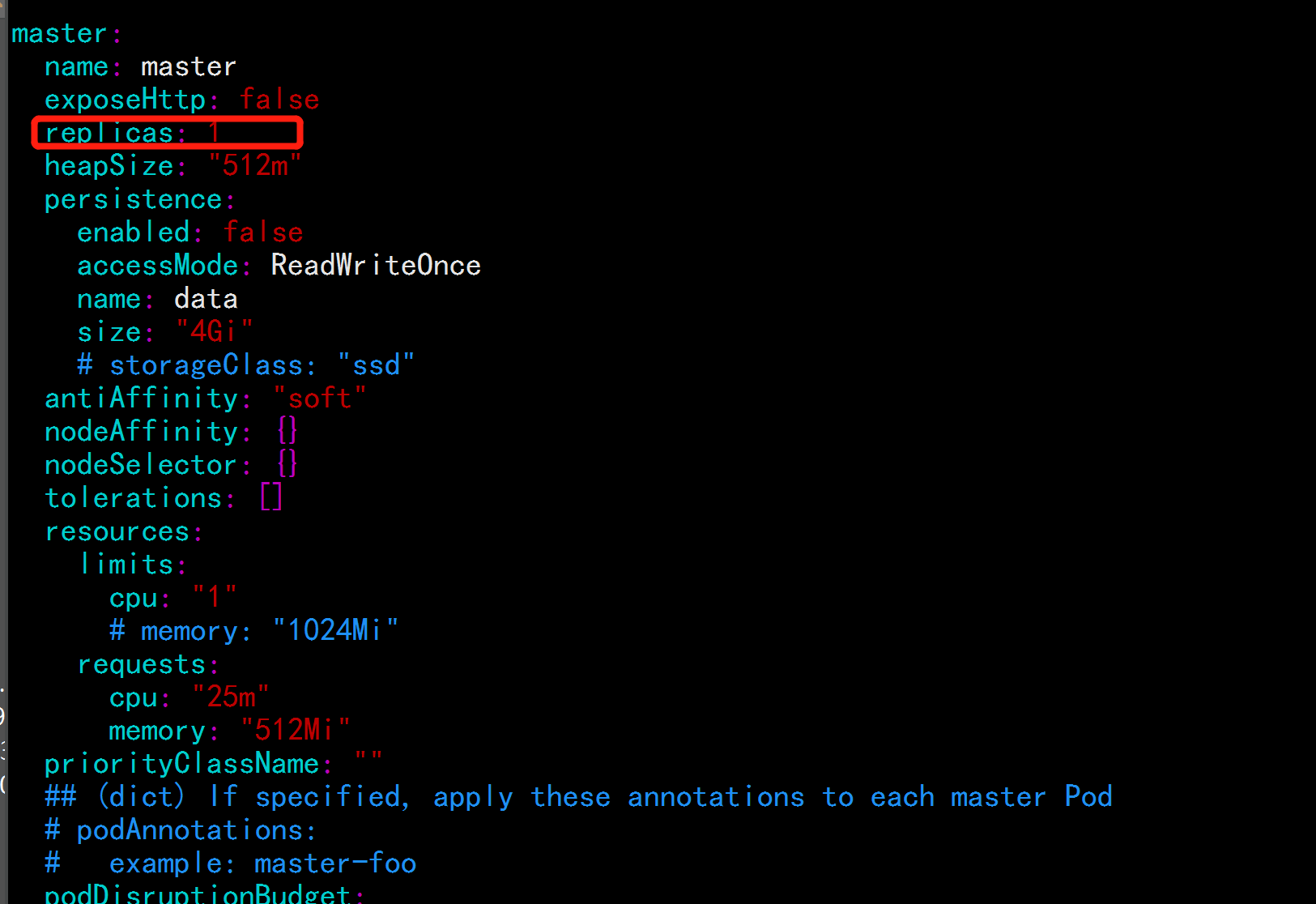
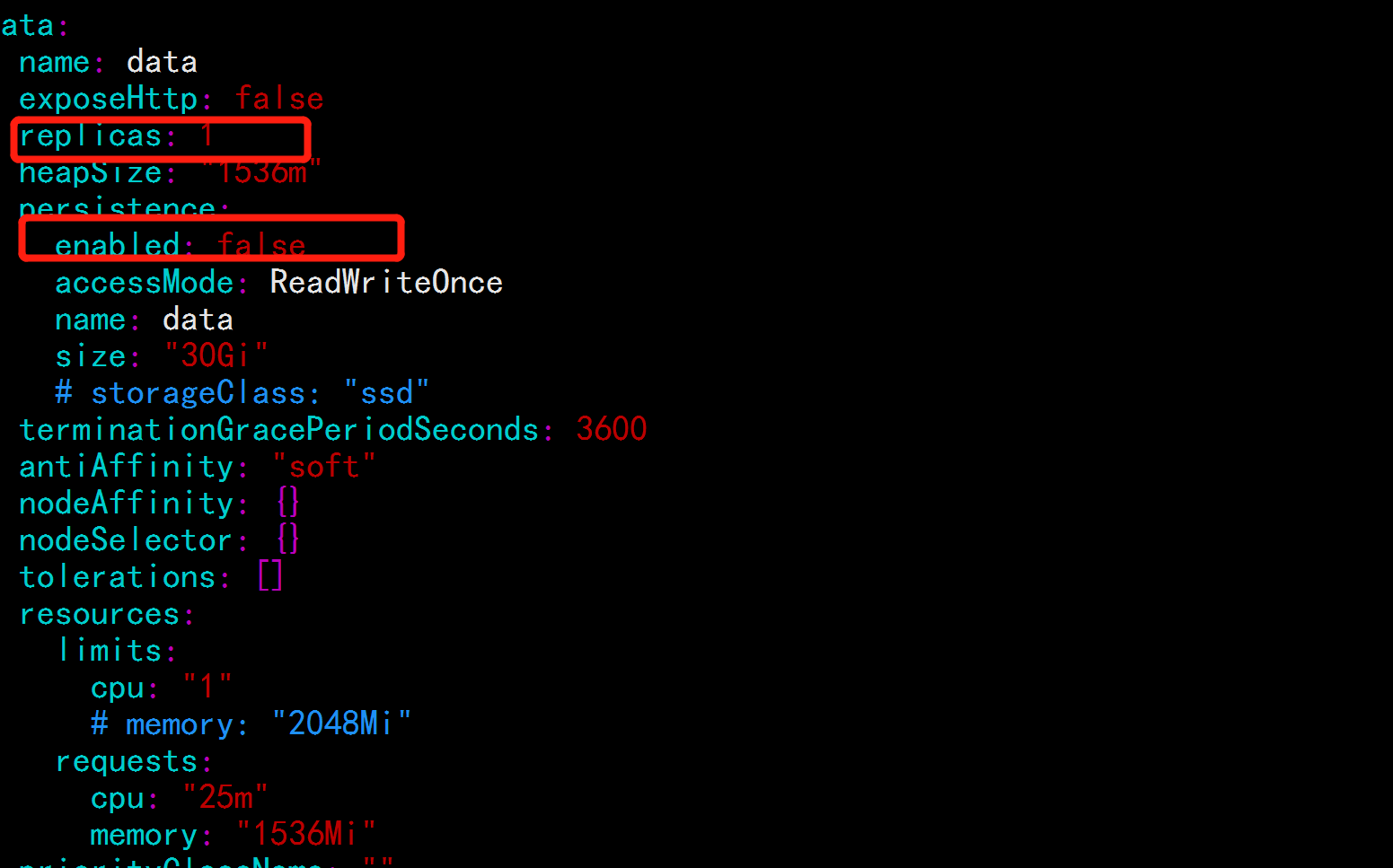
MINIMUM_MASTER_NODES: "1"
replicas: 1
enabled: false
##虚拟机配置硬件配置不是很高,所以改为1个 只有一个master节点
----
helm install --name els1 --namespace=efk -f values.yaml .
kubectl get pod -n efk
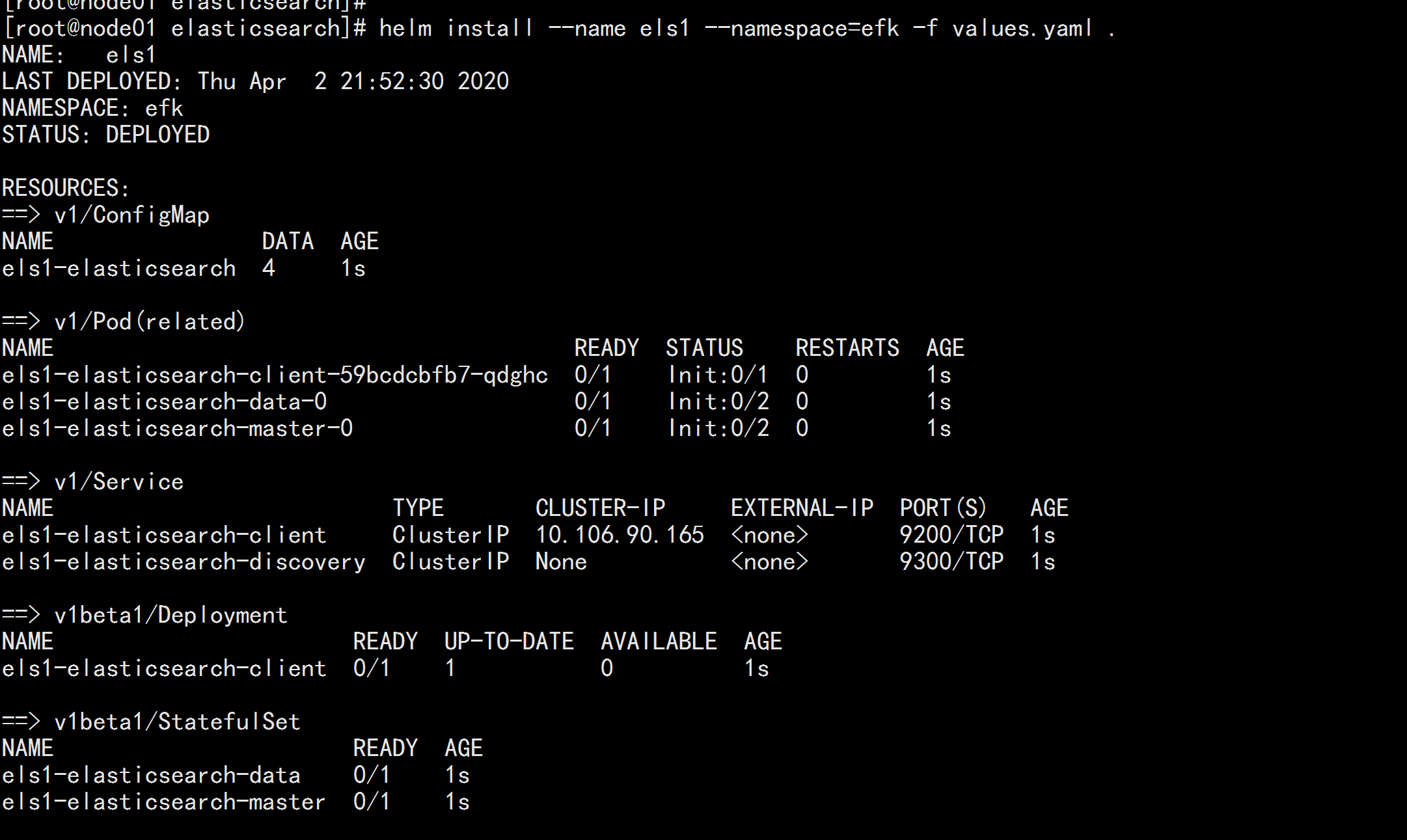
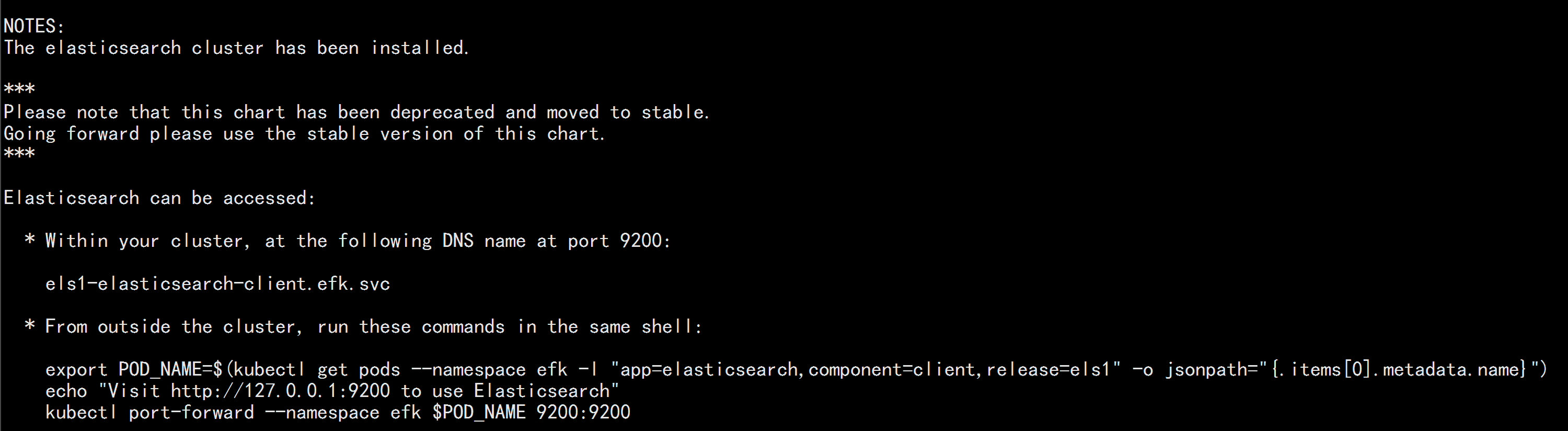

kubectl get svc -n efk
kubectl run cirror-$RANDOM --rm -it --image=cirros -- /bin/sh
curl Elasticsearch:Port/_cat/nodes

部署 Fluentd
helm fetch stable/fluentd-elasticsearch
tar -zxvf fluentd-elasticsearch-2.0.7.tgz
cd fluentd-elasticsearch/
vim values.yaml
---
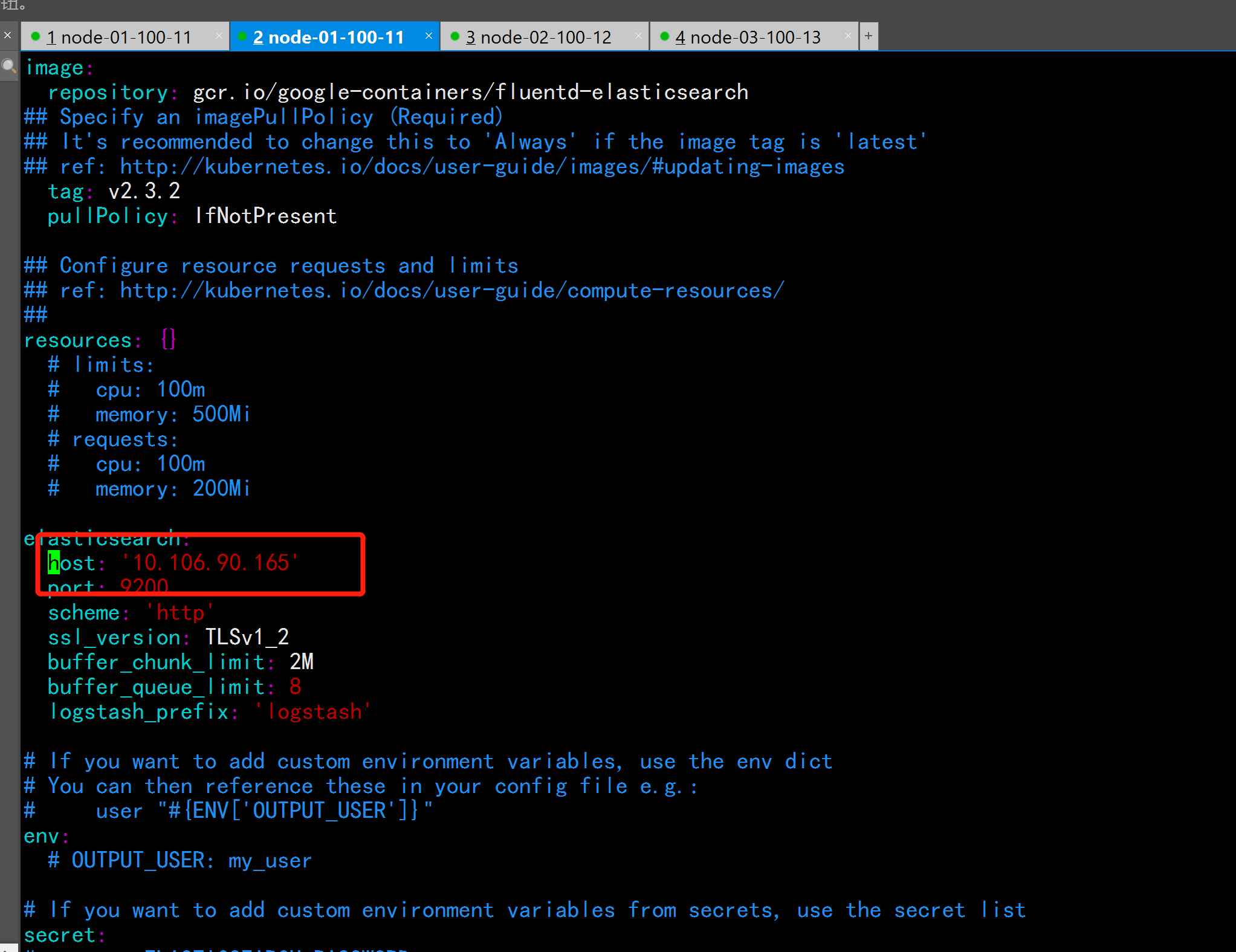
host: ‘elasticsearch-client‘ 改为 host: ‘10.106.90.165‘
---
helm install --name flu1 --namespace=efk -f values.yaml .
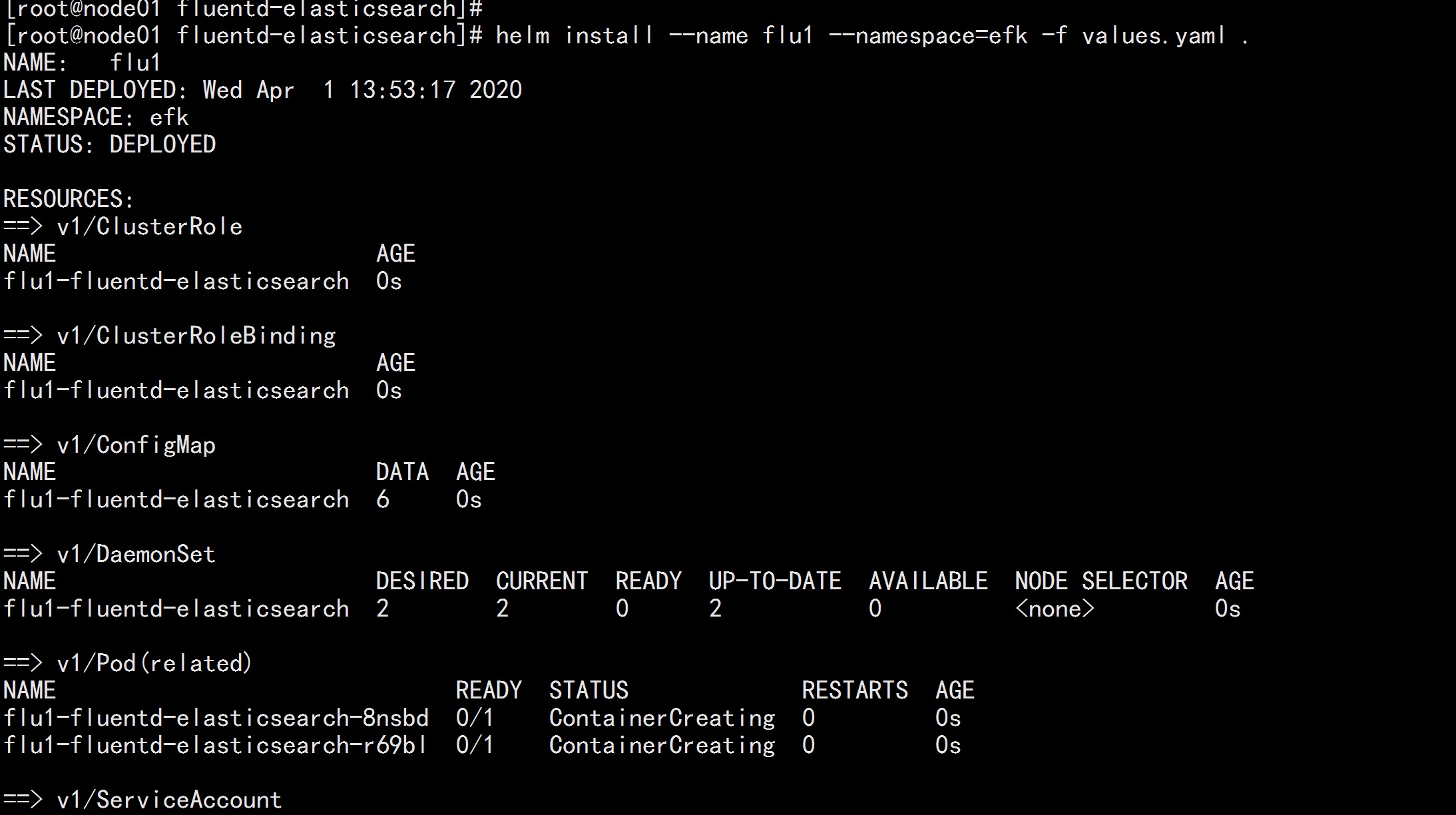
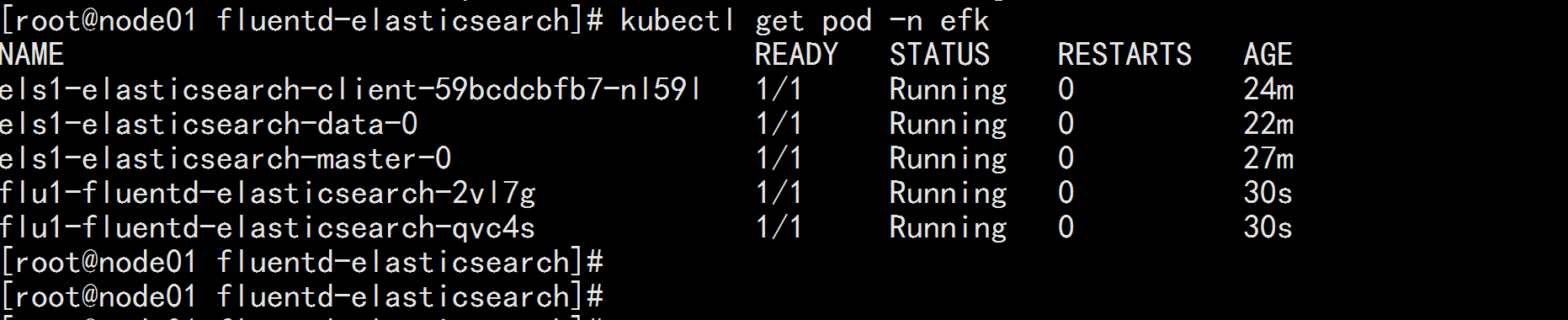

部署 kibana
helm fetch stable/kibana --version 0.14.8
tar -zxvf kibana-0.14.8.tgz
cd kibana
vim values.yaml
----
elasticsearch.url: http://10.106.90.165:9200
----
helm install --name kib1 --namespace=efk -f values.yaml .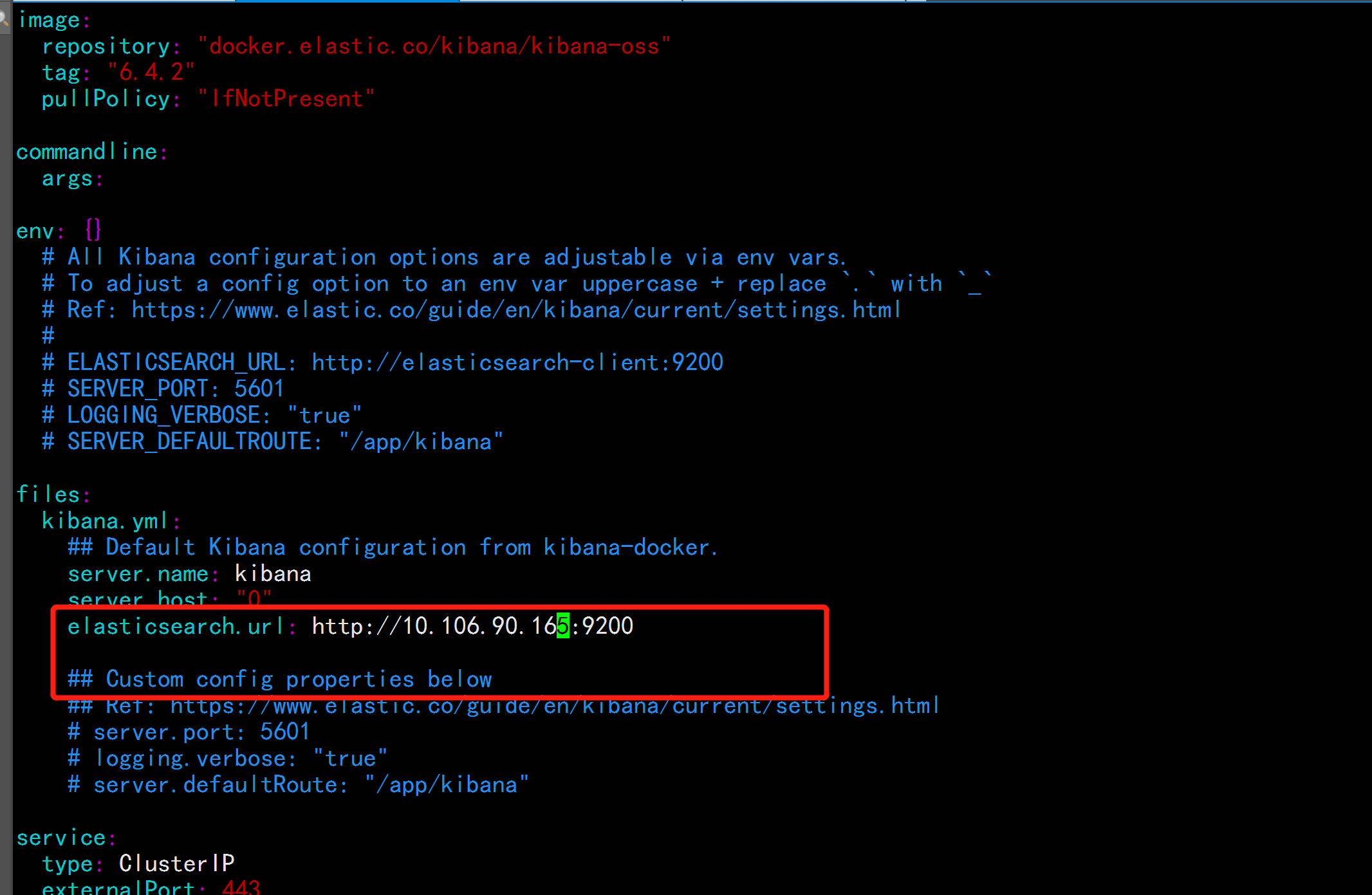
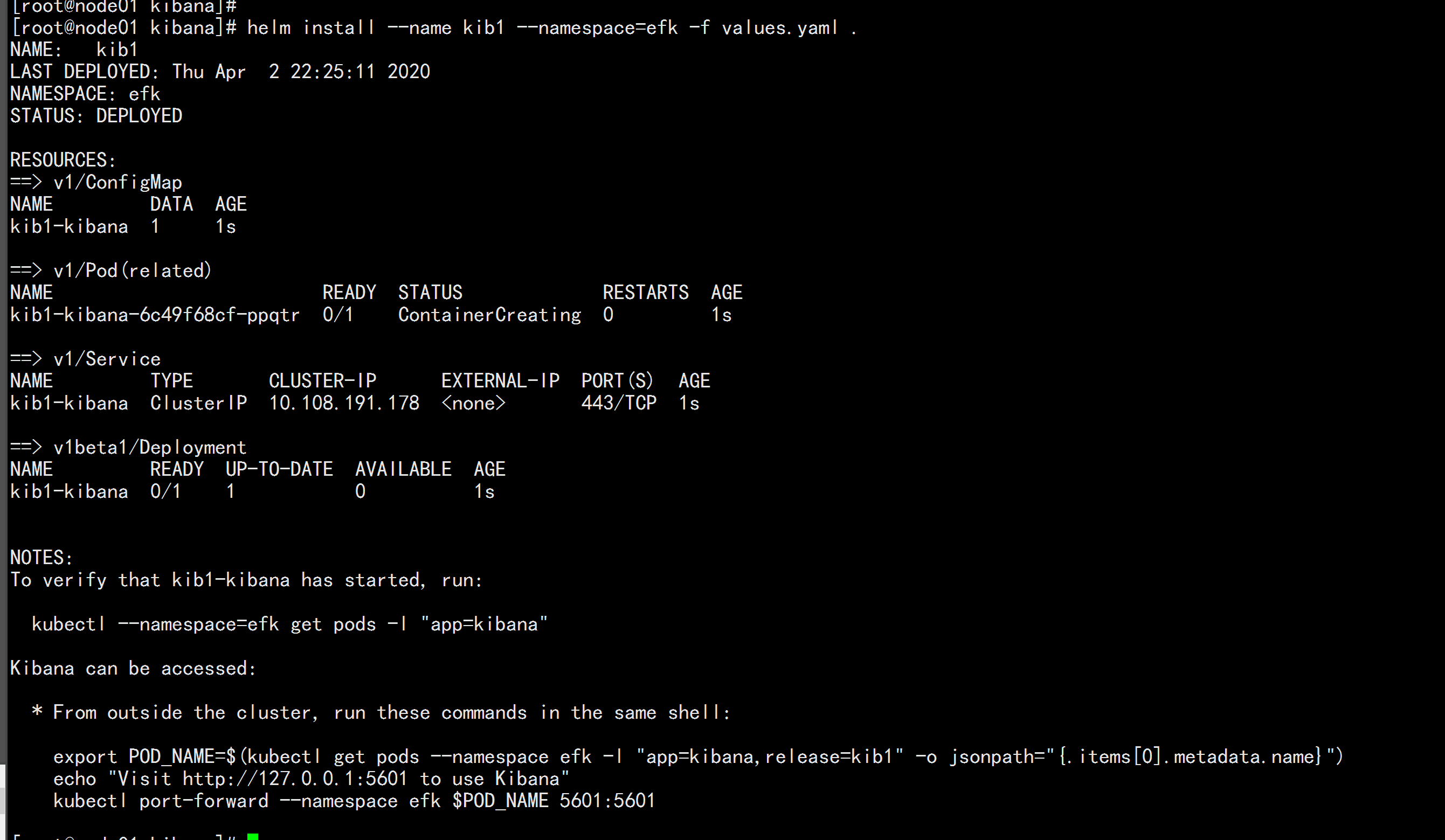

将kibana的clusterIP 改为NodePort
kubect get svc -n efk
kuectl edit svc kib1-kibana -n efk
------
type : Cluster-IP 改为 type: NodePort
------
允许 对外网 的访问

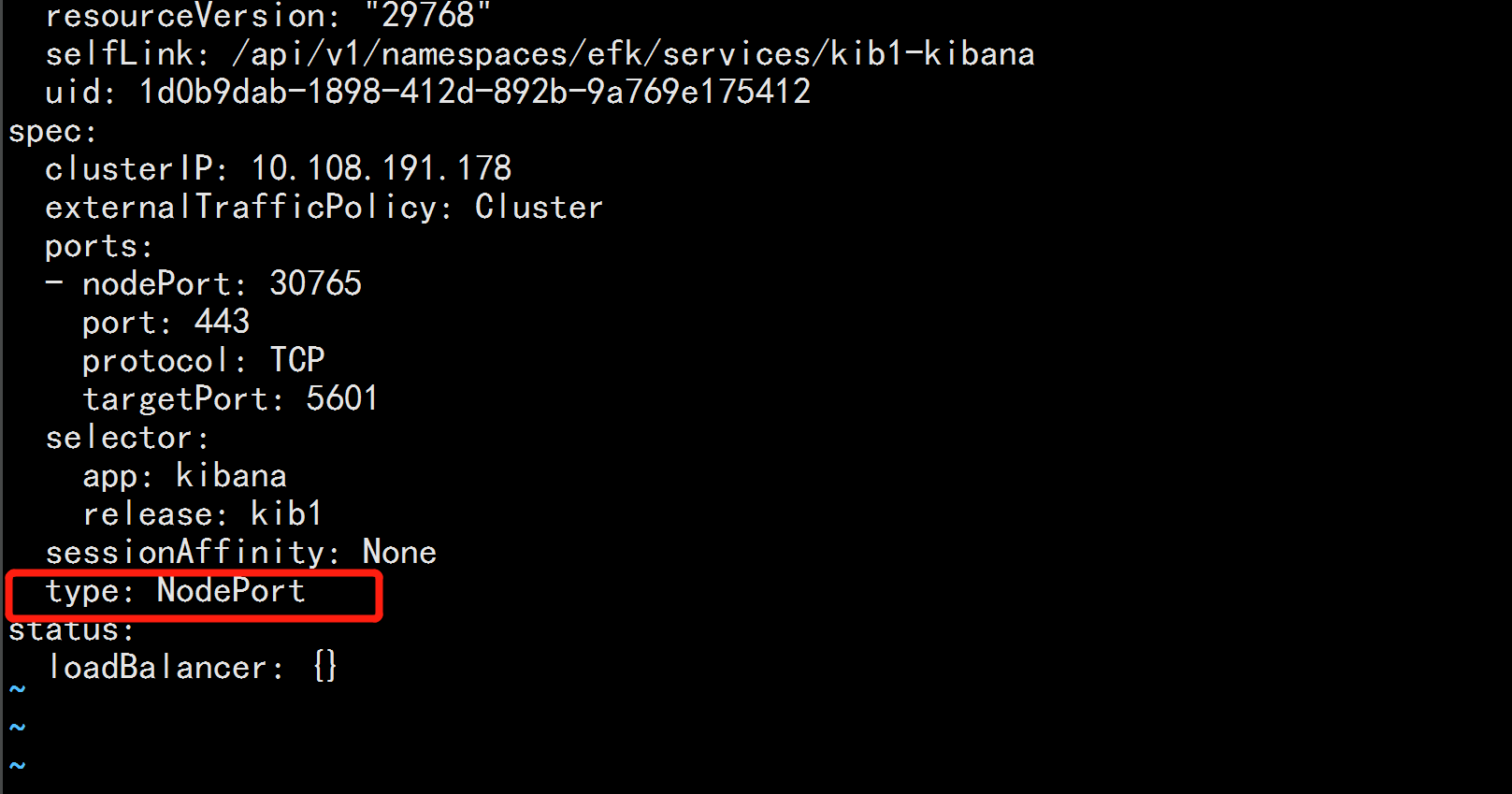
kubectl get svc -n efk 
http://192.168.100.11:30765
以上是关于kubernetes日志采集工具log-pilot使用的主要内容,如果未能解决你的问题,请参考以下文章