部署加速模型Int8量化
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了部署加速模型Int8量化相关的知识,希望对你有一定的参考价值。
0前言
- 为什么量化有用?
- 因为CNN对噪声不敏感。
2. 为什么用量化?
- 模型太大,比如alexnet就200MB,存储压力大的哟,必须要降一降温;
- 每个层的weights范围基本都是确定的,且波动不大,适合量化压缩;
- 此外,既减少访存又减少计算量,优势很大的啊!
3. 为什么不直接训练低精度的模型?
- 因为你训练是需要反向传播和梯度下降的,int8就非常不好做了,举个例子就是我们的学习率一般都是零点几零点几的,你一个int8怎么玩?
- 其次大家的生态就是浮点模型,因此直接转换有效的多啊!
1、INT8量化过程
一个训练好的深度学习模型,其数据包含了权重(weights)和偏移(biases)两部分,在其进行前向推理(forward)时,中间会根据权重和偏移产生激活值(activation)。
INT8的量化原理简单介绍:
- TensorRT在进行INT8量化时:1)对权重直接使用了最大值量化);2)对偏移直接忽略;3)对前向计算中的激活值的量化是重点;
- 对激活值进行INT8量化采用饱和量化:因为激活值通常分布不均匀,直接使用非饱和量化会使得量化后的值都挤在一个很小的范围从而浪费了INT8范围内的其他空间,也就是说没有充分利用INT8(-128~+127)的值域;而进行饱和量化后,使得映射后的-128~+127范围内分布相对均匀,这相当于去掉了一些不重要的因素,保留了主要成分。
英伟达官方PPT中对于偏移(biases)的处理:直接忽略掉,未明确原因。

量化的两种处理方式:
非饱和量化(左图)和饱和量化(右图)
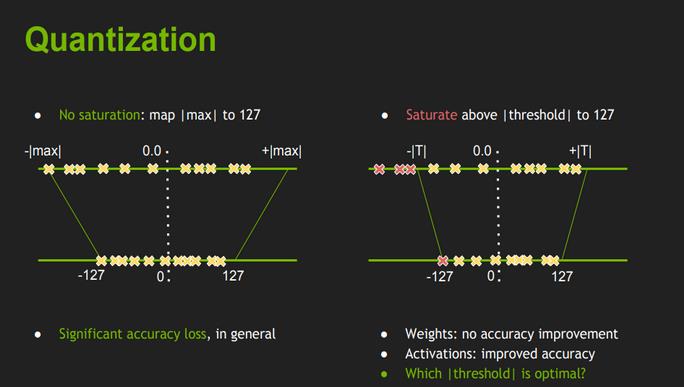
图1. 非饱和量化(左图)和饱和量化(右图)
- 权重没必要使用饱和映射,因为没啥提高,而激活值使用饱和映射能调高性能;
- 权重通常分别较为均匀直接最大值非饱和映射和费劲力气找阈值再进行饱和映射,其量化后的分布很可能是极其相似的;
- 激活值分布不均,寻找一个合适的阈值进行饱和映射就显得比较重要了;
- 图1显示直接使用最大值量化到INT8和选择一个合适的阈值后饱和地量化到INT的区别,可以看出:右图的关键在于选择一个合适的阈值T,来对原来的分布进行一个截取,将-T~+T之间的值映射到-128~+127,而>T和<-T的值则忽略掉。
量化评价指标:KL散度(相对熵)
NVIDIA选择了KL散度也即相对熵来对量化前后的激活值分布进行评价,来找出使得量化后INT8分布相对于原来的FP32分布信息损失最小的那个阈值。
INT8量化流程:
- 先在一个校准数据集上跑一遍原FP32的模型;
- 然后,统计每一层激活值的直方图(划分若干个bin,英伟达官方用的2048个bin);
- 生成在不同阈值T下的饱和量化分布,最后找出使得KL散度最小的那个阈值T,即为所求。
下面是网上的一张步骤图:

Tensorrt中进行Int8量化:
INT8量化需要准备哪些东西(tensorrt):
- 训练好的原始模型
- 一个校准数据集(取1000张样本)
- 进行量化过程的校准器(tensorrt未开源).
校准过程我们是不用参与的,全部都由TensorRT内部完成,但是,我们需要告诉校准器如何获取一个batch的数据,也就是说,我们需要重写校准器类中的一些方法。下面,我们就开始介绍如何继承原校准器类并重写其中的部分方法,来获取我们自己的数据集来校准我们自己的模型。
编写tensorrt校准器,并进行INT8量化
TensorRT 提供3种校准器 IInt8Calibrator 的实现:
IInt8EntropyCalibratorIInt8EntropyCalibrator2IInt8LegacyCalibrator
下面使用的是第二种。
1)我们需要创建IInt8Calibrator接口以提供校准数据和辅助函数来读写校准表。
2)我们创建的接口是继承tensorrt中的父类—trt.IInt8EntropyCalibrator2,并重写他的一些方法:get_batch_size, get_batch, read_calibration_cache, write_calibration_cache。
- get_batch_size:获取batch大小;
- get_batch:获取一个batch的数据;
- read_calibration_cache:将校准集写入缓存;
- write_calibration_cache:从缓存读出校准集。
- 前两个是必须的,不然校准器不知道用什么数据来校准,后两个方法可以忽略(一般也要写,包含数据预处理操作,和模型推理时保持一致),但当你需要多次尝试时,后两个方法将很有用,它们会大大减少数据读取的时间!
附录:信息熵、交叉熵、相对熵
信息熵:
![]()
我们可以用log ( 1/P )来衡量不确定性。P是一件事情发生的概率,概率越大,不确定性越小。
信息熵的公式其实就是log(1/p)的期望,就是不确定性的期望,它代表了一个系统的不确定性,信息熵越大,不确定性越大。因此,熵越大就代表事件发生的可能性越小;
信息熵H(X)可以看做对X中的样本进行编码所需要的编码长度的期望值。
这里可以引申出交叉熵的理解,现在有两个分布,真实分布p和非真实分布q,我们的样本来自真实分布p。
1、信息熵H( p ):按照真实分布p来编码样本所需的编码长度的期望为:
![]()
2、交叉熵H( p,q ):按照不真实分布q来编码样本所需的编码长度的期望为:
![]()
3、相对熵,KL散度D(p||q) :它表示两个分布的差异,差异越大,相对熵越大。
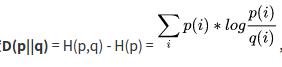
机器学习中,我们用非真实分布q去预测真实分布p,因为真实分布p是固定的,
D(p||q) = H(p,q) - H(p) 中 H(p) 固定,也就是说交叉熵H(p,q)越大,相对熵D(p||q)越大,两个分布的差异越大。
所以交叉熵用来做损失函数就是这个道理,它衡量了真实分布和预测分布的差异性。
参考链接:https://blog.csdn.net/oYeZhou/article/details/106719154
知乎上@章小龙的Int8量化-介绍:https://zhuanlan.zhihu.com/p/58182172
INT8量化GitHub工程:https://github.com/qq995431104/Pytorch2TensorRT.git
以上是关于部署加速模型Int8量化的主要内容,如果未能解决你的问题,请参考以下文章