MindSpore模型精度调优实战:如何更快定位精度问题
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MindSpore模型精度调优实战:如何更快定位精度问题相关的知识,希望对你有一定的参考价值。
摘要:为大家梳理了针对常见精度问题的调试调优指南,将以“MindSpore模型精度调优实战”系列文章的形式分享出来,帮助大家轻松定位精度问题,快速优化模型精度。
本文分享自华为云社区《技术干货 | 更快定位精度问题!MindSpore模型精度调优实战(一)》,原文作者:HWCloudAI 。
引言:
在模型的开发过程中,精度达不到预期常常让人头疼。为了帮助大家解决模型调试调优的问题,我们为MindSpore量身定做了可视化调试调优组件:MindInsight。
还为大家梳理了针对常见精度问题的调试调优指南,将以“MindSpore模型精度调优实战”系列文章的形式分享出来,帮助大家轻松定位精度问题,快速优化模型精度。
本文是系列分享的第一篇,将简单介绍常见精度问题,分析精度问题的常见现象和原因,并给出一个整体的调优思路。本系列分享假设您的脚本已经能够运行并算出loss值。如果脚本还不能运行,请先参考相关报错提示进行修改。在精度调优实践中,发现异常现象是比较容易的。但是,如果我们对异常现象不够敏感、不会解释,还是会同问题根因失之交臂。本文对常见精度问题进行了解释,能够提高你对异常现象的敏感度,帮你更快定位精度问题。
01 精度问题的常见现象和原因
模型精度问题和一般的软件问题不同,定位周期一般也更长。在通常的程序中,程序输出和预期不符意味着存在bug(编码错误)。但是对一个深度学习模型来说,模型精度达不到预期,有着更复杂的原因和更多的可能性。由于模型精度要经过长时间的训练才能看到最终结果,定位精度问题通常会花费更长的时间。
1.1 常见现象
精度问题的直接现象一般体现在loss(模型损失值)和metrics(模型度量指标)上。loss现象一般表现为(1)loss跑飞,出现NAN,+/- INF,极大值(2)loss不收敛、收敛慢(3)loss为0等。模型metrics一般表现为模型的accuracy、precision等metric达不到预期。
精度问题的直接现象较容易观察,借助MindInsight等可视化工具,还可以在梯度、权重、激活值等张量上观察到更多现象。常见现象如:(1)梯度消失(2)梯度爆炸(3)权重不更新(4)权重变化过小(5)权重变化过大(6)激活值饱和等。
1.2 常见原因
有果必有因,在现象的背后,是精度问题的原因,可以简单分为超参问题、模型结构问题、数据问题、算法设计问题等类别:
-
1.2.1 超参问题
超参是模型和数据之间的润滑剂,超参的选择直接影响了模型对数据拟合效果的优劣。超参方面常见的问题如下:
1)学习率设置不合理(过大、过小)
2)loss_scale参数不合理
3)权重初始化参数不合理等
4)epoch过大或过小
5)batch size过大
学习率过大或过小。学习率可以说是模型训练中最重要的超参了。学习率过大,会导致loss震荡,不能收敛到预期值。学习率过小,会导致loss收敛慢。应根据理论和经验合理选择学习率策略。
epoch过大或过小。epoch数目直接影响模型是欠拟合还是过拟合。epoch过小,模型未训练到最优解就停止了训练,容易欠拟合;epoch过大,模型训练时间过长,容易在训练集上过拟合,在测试集上达不到最优的效果。应根据训练过程中验证集上模型效果的变化情况,合理选择epoch数目。batch size过大。batch size过大时,模型可能不能收敛到较优的极小值上,从而降低模型的泛化能力。
-
1.2.2 数据问题
a.数据集问题
数据集的质量决定了算法效果的上限,如果数据质量差,再好的算法也难以得到很好的效果。常见数据集问题如下:
1)数据缺失值过多
2)每个类别中的样本数目不均衡
3)数据中存在异常值
4)训练样本不足
5)数据的标签错误
数据集中存在缺失值、异常值,会导致模型学习到错误的数据关系。一般来说,应该从训练集中删除存在缺失值或异常值的数据,或者设置合理的默认值。数据标签错误是异常值的一种特殊情况,但是这种情况对训练的破坏性较大,应通过抽查输入模型的数据等方式提前识别这类问题。
数据集中每个类别的样本数目不均衡,是指数据集中每个类别中的样本数目有较大差距。例如,图像分类数据集(训练集)中,大部分类别都有1000个样本,但是“猫”这一类别只有100个样本,就可以认为出现了样本数目不均衡的情况。样本数目不均衡会导致模型在样本数目少的类别上预测效果差。如果出现了样本数目不均衡,应该酌情增加样本量小的类别的样本。一般来说,有监督深度学习算法在每类5000个标注样本的情况下将达到可以接受的性能,当数据集中有1000万个以上的已标注样本时,模型的表现将会超过人类。
训练样本不足则是指训练集相对于模型容量太小。训练样本不足会导致训练不稳定,且容易出现过拟合。如果模型的参数量同训练样本数量不成比例,应该考虑增加训练样本或者降低模型复杂度。
b.数据处理问题常见数据处理问题如下:
1)常见数据处理算法问题
2)数据处理参数不正确等
3)未对数据进行归一化或标准化
4)数据处理方式和训练集不一致
5)没有对数据集进行shuffle
未对数据进行归一化或标准化,是指输入模型的数据,各个维度不在一个尺度上。一般来说,模型要求各个维度的数据在-1到1之间,均值为0。如果某两个维度的尺度存在数量级的差异,可能会影响模型的训练效果,此时需要对数据进行归一化或标准化。数据处理方式和训练集不一致是指在使用模型进行推理时,处理方式和训练集不一致。例如对图片的缩放、裁切、归一化参数和训练集不同,会导致推理时的数据分布和训练时的数据分布产生差异,可能会降低模型的推理精度。备注:一些数据增强操作(如随机旋转,随机裁切等)一般只应用在训练集,推理时无需进行数据增强。
没有对数据集进行shuffle,是指训练时未对数据集进行混洗。未进行shuffle,或者混洗不充分,会导致总是以相同的数据顺序更新模型,严重限制了梯度优化方向的可选择性,导致收敛点的选择空间变少,容易过拟合。
-
1.2.3 算法问题
算法本身有缺陷导致精度无法达到预期。
a. API使用问题
常见API使用问题如下:
1.使用API没有遵循MindSpore约束
2.构图时未遵循MindSpore construct约束。
使用API未遵循MindSpore约束,是指使用的API和真实应用的场景不匹配。例如,在除数中可能含有零的场景,应该考虑使用DivNoNan而非Div以避免产生除零问题。又例如,MindSpore中,DropOut第一个参数为保留的概率,和其它框架正好相反(其它框架为丢掉的概率),使用时需要注意。
构图未遵循MindSpore construct约束,是指图模式下的网络未遵循MindSpore静态图语法支持中声明的约束。例如,MindSpore目前不支持对带键值对参数的函数求反向。完整约束请见:https://mindspore.cn/doc/note/zh-CN/master/static_graph_syntax_support.html
b. 计算图结构问题
计算图结构是模型计算的载体,计算图结构错误一般是实现算法时代码写错了。计算图结构方面常见的问题有:
1.算子使用错误(使用的算子不适用于目标场景)
2.权重共享错误(共享了不应共享的权重)
3.节点连接错误(应该连接到计算图中的block未连接)
4.节点模式不正确
5.权重冻结错误(冻结了不应冻结的权重)
6.loss函数有误
7.优化器算法错误(如果自行实现了优化器)等
权重共享错误,是指应该共享的权重未共享,或者不应该共享的权重共享了。通过MindInsight计算图可视,可以检查这一类问题。
权重冻结错误,是指应该冻结的权重未冻结,或者不应该冻结的权重冻结了。在MindSpore中,冻结权重可以通过控制传入优化器的params参数来实现。未传入优化器的Parameter将不会被更新。可以通过检查脚本,或者查看MindInsight中的参数分布图确认权重冻结情况。
节点连接错误,是指计算图中各block的连接和设计不一致。如果发现节点连接错误,应该仔细检查脚本是否编写出错。
节点模式不正确,是指部分区分训练、推理模式的算子,需要按照实际情况设置模式。典型的包括:(1)BatchNorm算子,训练时应打开BatchNorm的训练模式,此开关在调用 net.set_train(True)的时候会自动打开(2)DropOut算子,推理时不应使用DropOut算子。
loss函数有误,是指loss函数算法实现错误,或者未选择合理的loss函数。例如,BCELoss和BCEWithLogitsLoss是不同的,应根据是否需要sigmoid函数合理选择。
c. 权重初始化问题
权重初始值是模型训练的起点,不合理的初始值将会影响模型训练的速度和效果。权重初始化方面常见问题如下:
1.权重初始值全部为0
2.分布式场景不同节点的权重初始值不同
权重初始值全为0,是指初始化后,权重值为0。这一般会导致权重更新问题,应使用随机值初始化权重。
分布式场景不同节点的权重初始值不同,是指初始化后,不同节点上的同名权重初始值不同。正常来说,MindSpore会对梯度做全局AllReduce。确保每个step结尾,权重更新量是相同的,从而保证每个step中,各个节点上的权重一致。如果初始化时各节点的权重不同,就会导致不同节点的权重在接下来的训练中处于不同的状态,会直接影响模型精度。分布式场景应通过固定相同的随机数种子等方式,确保权重的初始值一致。
1.3 相同现象存在多个可能原因导致精度问题定位难
以loss不收敛为例(下图),任何可能导致激活值饱和、梯度消失、权重更新不正确的问题都可能导致loss不收敛。例如错误地冻结了部分权重,使用的激活函数和数据不匹配(使用relu激活函数,输入值全部小于0),学习率过小等原因都是loss不收敛的可能原因。

02 调优思路概述

针对上述精度问题的现象和原因,常用的几个调优思路如下:检查代码和超参、检查模型结构、检查输入数据、检查loss曲线。若上述思路都未发现问题,我们可以让训练执行到最后,检查精度(主要是模型metrics)是否达到预期。
其中,检查模型结构和超参重在检查模型的静态特征;检查输入数据和loss曲线则是将静态特征和动态训练现象结合检查;检查精度是否达到预期则是对整体精度调优过程重新审视,并考虑调整超参、解释模型、优化算法等调优手段。
为了帮助用户高效实施上述的精度调优思路,MindInsight提供了配套的能力,如下图。在本系列的后续文章后,我们会展开介绍精度调优的准备工作,每个调优思路的细节,以及如何使用MindInsight的功能实践这些调优思路,敬请期待。

03 精度问题checklist
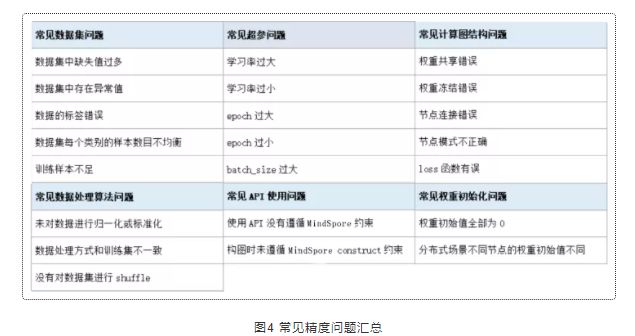
最后,我们将常见的精度问题汇总到一起,以方便大家查阅:
了解完MindSpore的关键技术是不是很心动呢!赶紧【点击链接】并【立即报名】,即可在 ModelArts 平台学习到一个经典案例掌握基于MindSpore的深度学习!
以上是关于MindSpore模型精度调优实战:如何更快定位精度问题的主要内容,如果未能解决你的问题,请参考以下文章