Netty结合Protostuff传输对象案例,单机压测秒级接收35万个对象
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty结合Protostuff传输对象案例,单机压测秒级接收35万个对象相关的知识,希望对你有一定的参考价值。
单纯netty结合protostuff进行rpc对象传输的demo网上有很多,大部分都是一个模子刻出来的,一开始我也是抄了一个,本地测试畅通无阻,未发生任何异常。
部署预发环境,进行压测后,问题巨多,各种报错层出不穷。当然,压测时我用的数据量大、发送请求非常密集,单机是每秒前100ms发送2万个对象,其他900ms歇息,死循环发送,共计40台机器作为客户端,同时往2台netty Server服务器发送对象,那么平均每个server每秒大概要接收40万个对象,由于后面还有业务逻辑,逻辑每秒只能处理35万实测。
对于网上的代码,进行了多次修改,反复测试,最终是达到了不报错无异常,单机秒级接收35万个对象以上,故写篇文章记录一下,文中代码会和线上逻辑保持一致。
Protostuff序列化和反序列化
这个没什么特殊的,网上找个工具类就好了。
引入pom
<protostuff.version>1.7.2</protostuff.version>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>${protostuff.version}</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>${protostuff.version}</version>
</dependency>
public class ProtostuffUtils {
/**
* 避免每次序列化都重新申请Buffer空间
* 这句话在实际生产上没有意义,耗时减少的极小,但高并发下,如果还用这个buffer,会报异常说buffer还没清空,就又被使用了
*/
// private static LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
/**
* 缓存Schema
*/
private static Map<Class<?>, Schema<?>> schemaCache = new ConcurrentHashMap<>();
/**
* 序列化方法,把指定对象序列化成字节数组
*
* @param obj
* @param <T>
* @return
*/
@SuppressWarnings("unchecked")
public static <T> byte[] serialize(T obj) {
Class<T> clazz = (Class<T>) obj.getClass();
Schema<T> schema = getSchema(clazz);
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
byte[] data;
try {
data = ProtobufIOUtil.toByteArray(obj, schema, buffer);
// data = ProtostuffIOUtil.toByteArray(obj, schema, buffer);
} finally {
buffer.clear();
}
return data;
}
/**
* 反序列化方法,将字节数组反序列化成指定Class类型
*
* @param data
* @param clazz
* @param <T>
* @return
*/
public static <T> T deserialize(byte[] data, Class<T> clazz) {
Schema<T> schema = getSchema(clazz);
T obj = schema.newMessage();
ProtobufIOUtil.mergeFrom(data, obj, schema);
// ProtostuffIOUtil.mergeFrom(data, obj, schema);
return obj;
}
@SuppressWarnings("unchecked")
private static <T> Schema<T> getSchema(Class<T> clazz) {
Schema<T> schema = (Schema<T>) schemaCache.get(clazz);
if (Objects.isNull(schema)) {
//这个schema通过RuntimeSchema进行懒创建并缓存
//所以可以一直调用RuntimeSchema.getSchema(),这个方法是线程安全的
schema = RuntimeSchema.getSchema(clazz);
if (Objects.nonNull(schema)) {
schemaCache.put(clazz, schema);
}
}
return schema;
}
}
此处有坑,就是最上面大部分网上代码都是用了static的buffer。在单线程情况下没有问题。在多线程情况下,非常容易出现buffer一次使用后尚未被clear,就再次被另一个线程使用,会抛异常。而所谓的避免每次都申请buffer空间,实测性能影响极其微小。
另里面两次ProtostuffIOUtil都改成了ProtobufIOUtil,因为也是出过异常,修改后未见有异常。
自定义序列化方式
解码器decoder:
import com.jd.platform.hotkey.common.model.HotKeyMsg;
import com.jd.platform.hotkey.common.tool.ProtostuffUtils;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.ByteToMessageDecoder;
import java.util.List;
/**
* @author wuweifeng
* @version 1.0
* @date 2020-07-29
*/
public class MsgDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf in, List<Object> list) {
try {
byte[] body = new byte[in.readableBytes()]; //传输正常
in.readBytes(body);
list.add(ProtostuffUtils.deserialize(body, HotKeyMsg.class));
// if (in.readableBytes() < 4) {
// return;
// }
// in.markReaderIndex();
// int dataLength = in.readInt();
// if (dataLength < 0) {
// channelHandlerContext.close();
// }
// if (in.readableBytes() < dataLength) {
// in.resetReaderIndex();
// return;
// }
//
// byte[] data = new byte[dataLength];
// in.readBytes(data);
//
// Object obj = ProtostuffUtils.deserialize(data, HotKeyMsg.class);
// list.add(obj);
} catch (Exception e) {
e.printStackTrace();
}
}
}
编码器 encoder
import com.jd.platform.hotkey.common.model.HotKeyMsg;
import com.jd.platform.hotkey.common.tool.Constant;
import com.jd.platform.hotkey.common.tool.ProtostuffUtils;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToByteEncoder;
/**
* @author wuweifeng
* @version 1.0
* @date 2020-07-30
*/
public class MsgEncoder extends MessageToByteEncoder {
@Override
public void encode(ChannelHandlerContext ctx, Object in, ByteBuf out) {
if (in instanceof HotKeyMsg) {
byte[] bytes = ProtostuffUtils.serialize(in);
byte[] delimiter = Constant.DELIMITER.getBytes();
byte[] total = new byte[bytes.length + delimiter.length];
System.arraycopy(bytes, 0, total, 0, bytes.length);
System.arraycopy(delimiter, 0, total, bytes.length, delimiter.length);
out.writeBytes(total);
}
}
}
先看Decoder解码器,这个是用来netty收到消息后,进行解码,将字节转为对象(自定义的HotKeyMsg)用的。里面有一堆被我注释掉了,注释掉的,应该在网上找到的帖子都是那么写的。这种方式本身在普通场景下是没问题的,解码还算正常,但是当上几十万时非常容易出现粘包问题。所以我是在这个解码器前增加了一个DelimiterBasedFrameDecoder分隔符解码器。
当收到消息时,先过这个分隔符解码器,之后到MsgDecoder那里时,就是已经分隔好的一个对象字节流了,就可以直接用proto工具类进行反序列化的。Constant.DELIMITER是我自定义的一个特殊字符串,用来做分隔符。
再看encoder,编码器,首先将要传输的对象用ProtostuffUtils序列化为byte[],然后在尾巴上挂上我自定义的那个分隔符。这样在对外发送对象时,就会走这个编码器,并被加上分隔符。
对应的server端代码大概是这样:
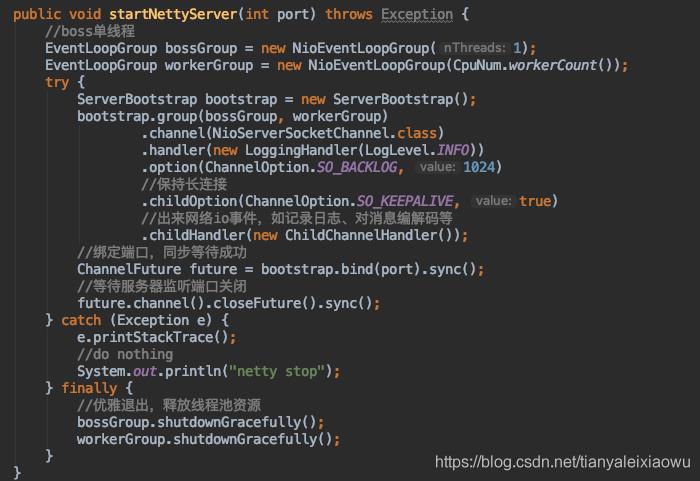
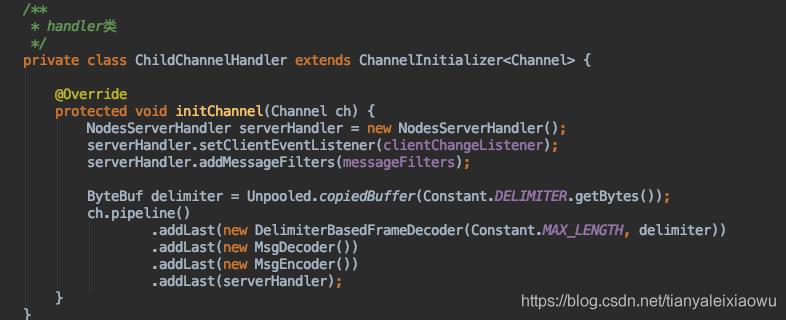
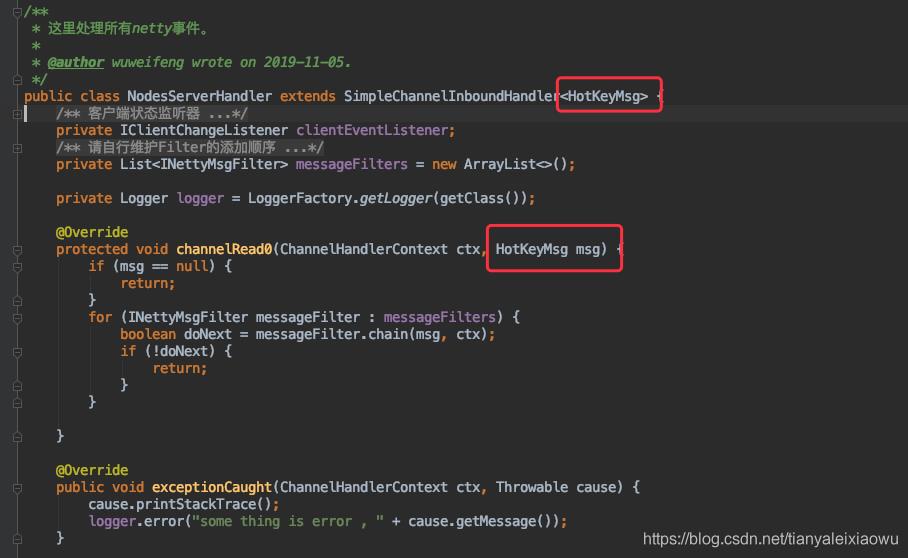
之后在Handler里就可以直接使用这个传输的对象了。
再看client端
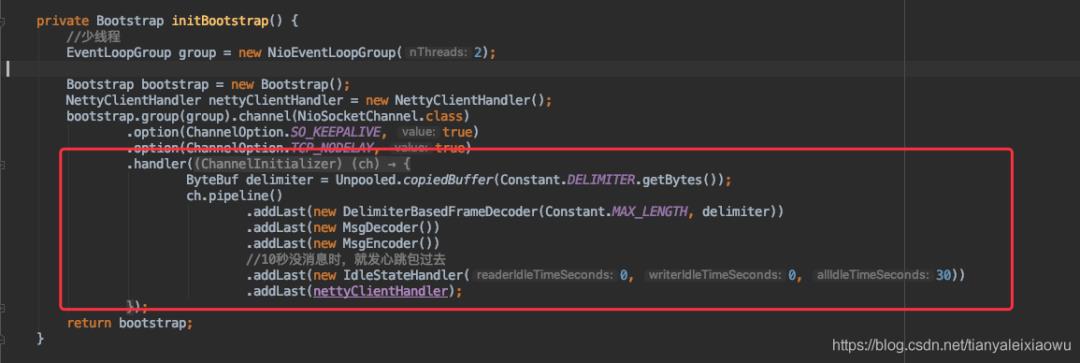
和Server端是一样的,也是这几个编解码器,没有区别。因为netty和server之间通讯,我都是用的同一个对象定义。
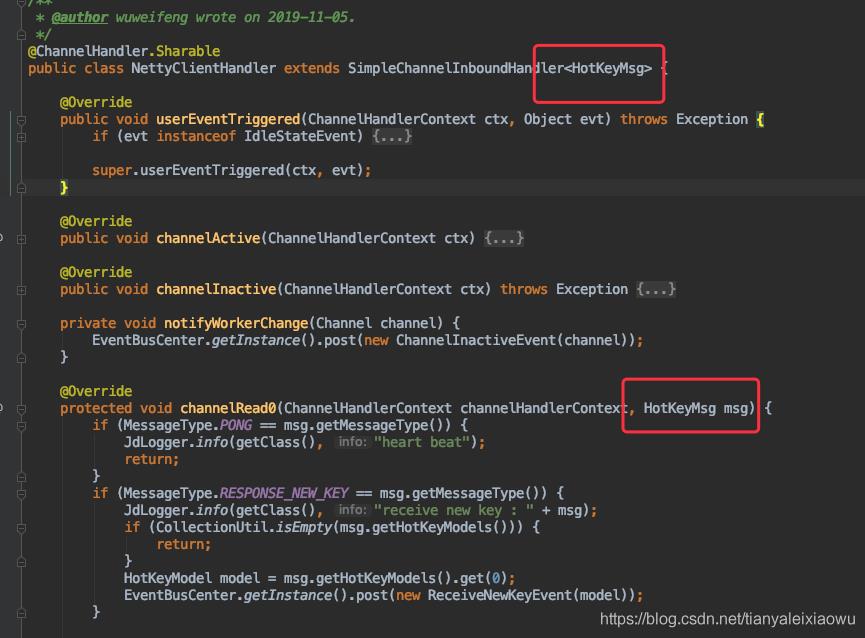
同理handler也是一样的。
单机和集群
以上都写完后,其实就可以测试了,我们可以启动一个client,一个server,然后搞个死循环往Server发这个对象了,然后你在server端在收到这个对象后,再直接把这个对象也写回来,原样发送到客户端。会发现运行的很顺畅,每秒发N万个没问题,编解码都正常,client和server端都比较正常,当前前提是ProtoBuf的工具类和我的一样,不要共享那个buffer。网上找的文章基本上到这样也就结束了,随便发几个消息没问题也就算OK。然而实际上,这种代码上线后,会坑的不要不要的。
其实本地测试也很容易,再启动几个客户端,都连同一个Server,然后给他死循环发对象,再看看两端会不会有异常。这种情况下,和第一种的区别其实客户端没什么变化,Server端就有变化了,之前同时只给一个client发消息,现在同时给两个client发消息,这一步如果不谨慎就会出问题了,建议自行尝试。
之后,我们再加点料,我启动两个Server,分别用两个端口,线上其实是两台不同的server服务器,client会同时往两台server死循环发对象,如下图代码。
发消息,我们常用的就是channel.writeAndFlush(),大家可以把那个sync去掉,然后跑一下代码看看。会发现异常抛的一坨一坨的。我们明明是往两个不同的channel发消息,只不过时间是同时,结果就是发生了严重的粘包。server端收到的消息很多都是不规范的,会大量报错。如果在两个channel发送间隔100ms,情况就解决了。当然,最终我们可以使用sync同步发送,这样就不会抛异常了。
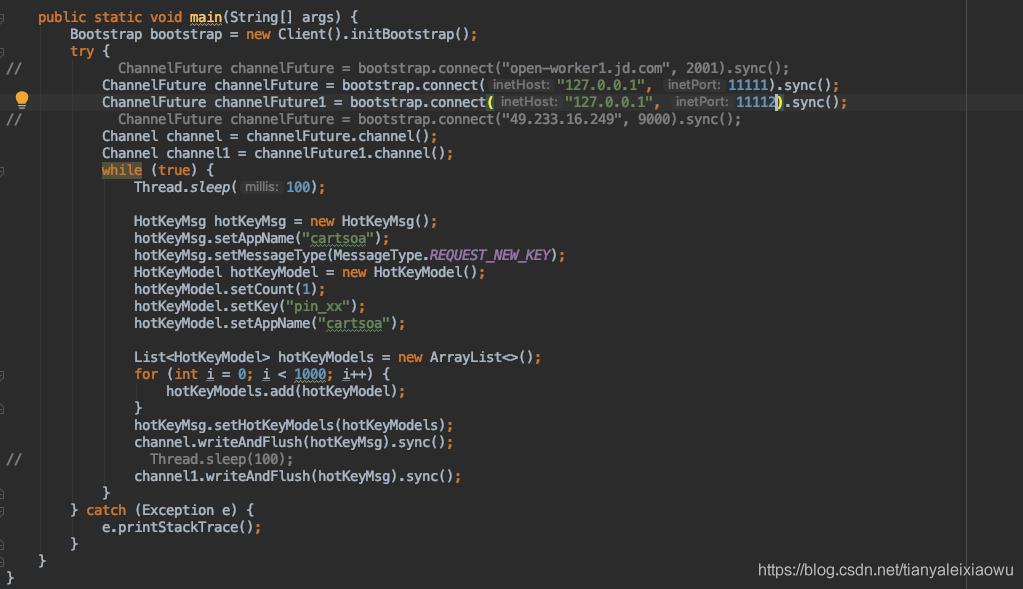
以上代码经测试,40台client,2台Server,平均每个server每秒大概接收40万个对象,可以持续稳定运行。
最近面试BAT,整理一份面试资料
《Java面试BAT通关手册》
,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
以上是关于Netty结合Protostuff传输对象案例,单机压测秒级接收35万个对象的主要内容,如果未能解决你的问题,请参考以下文章