优化 Golang 分布式行情推送的性能瓶颈
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化 Golang 分布式行情推送的性能瓶颈相关的知识,希望对你有一定的参考价值。

责编 | 张红月
出品 | 码农桃花源
最近一直在优化行情推送系统,有不少优化心得跟大家分享下。性能方面提升最明显的是时延,在单节点8万客户端时,时延从1500ms优化到40ms,这里是内网mock客户端的得到的压测数据。
对于订阅客户端数没有太执着量级的测试,弱网络下单机8w客户端是没问题的。当前采用的是kubenetes部署方案,可灵活地扩展扩容。

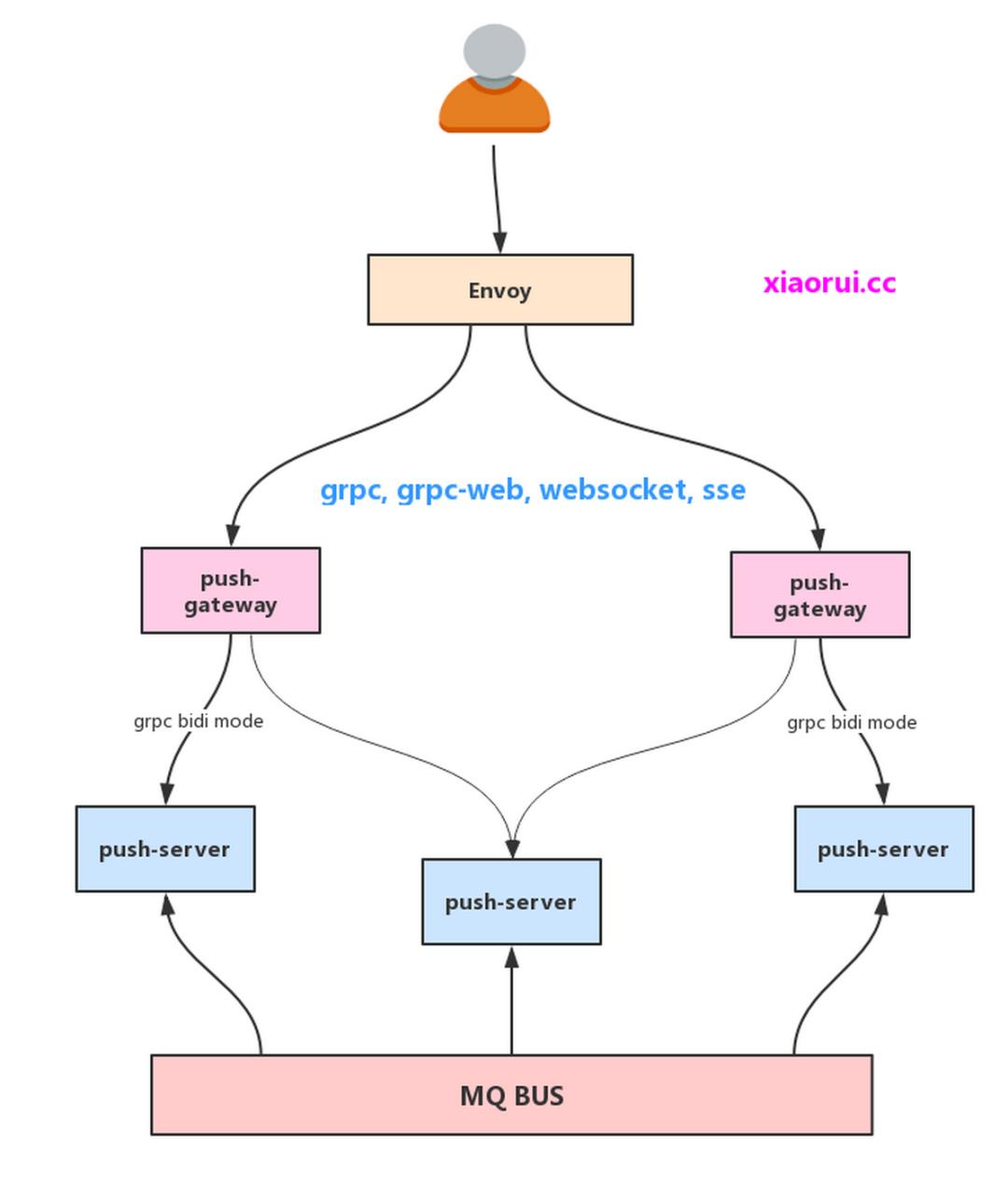
架构图
push-gateway 是推送的网关,有这么几个功能:第一点是为了做鉴权;第二点是为了做接入多协议,我们这里实现了websocket, grpc, grpc-web,sse的支持;第三点是为了实现策略调度及亲和绑定等。
push-server 是推送服务,这里维护了订阅关系及监听mq的新消息,继而推送到网关。

问题一:并发操作map带来的锁竞争及时延
推送的服务需要维护订阅关系,一般是用嵌套的map结构来表示,这样造成map并发竞争下带来的锁竞争和时延高的问题。
// xiaorui.cc {"topic1": {"uuid1": client1, "uuid2": client2}, "topic2": {"uuid3": client3, "uuid4": client4} ... }
已经根据业务拆分了4个map,但是该订阅关系是嵌套的,直接上锁会让其他协程都阻塞,阻塞就会造成时延高。
加锁操作map本应该很快,为什么会阻塞?上面我们有说过该map是用来存topic和客户端列表的订阅关系,当我进行推送时,必然是需要拿到该topic的所有客户端,然后进行一个个的send通知。(这里的send不是io.send,而是chan send,每个客户端都绑定了缓冲的chan)
解决方法:在每个业务里划分256个map和读写锁,这样锁的粒度降低到1/256。除了该方法,开始有尝试过把客户端列表放到一个新的slice里返回,但造成了 GC 的压力,经过测试不可取。
// xiaorui.cc
sync.RWMutexmap[string]map[string]client
改成这样
m *shardMap.shardMap
分段map的库已经推到github[1]了,有兴趣的可以看看。

问题二:串行消息通知改成并发模式
简单说,我们在推送服务维护了某个topic和1w个客户端chan的映射,当从mq收到该topic消息后,再通知给这1w个客户端chan。
客户端的chan本身是有大buffer,另外发送的函数也使用 select default 来避免阻塞。但事实上这样串行发送chan耗时不小。对于channel底层来说,需要goready等待channel的goroutine,推送到runq里。
下面是我写的benchmark[2],可以对比串行和并发的耗时对比。在mac下效果不是太明显,因为mac cpu频率较高,在服务器里效果明显。
串行通知,拿到所有客户端的chan,然后进行send发送。
for _, notifier := range notifiers { s.directSendMesg(notifier, mesg)}
并发send,这里使用协程池来规避morestack的消耗,另外使用sync.waitgroup里实现异步下的等待。
// xiaorui.cc
notifiers := []*mapping.StreamNotifier{}// conv slicefor _, notifier := range notifierMap { notifiers = append(notifiers, notifier)}
// optimize: direct map structtaskChunks := b.splitChunks(notifiers, batchChunkSize)
// concurrent send chanwg := sync.WaitGroup{}for _, chunk := range taskChunks { chunkCopy := chunk // slice replica wg.Add(1) b.SubmitBlock( func() { for _, notifier := range chunkCopy { b.directSendMesg(notifier, mesg) } wg.Done() }, )}wg.Wait()
按线上的监控表现来看,时延从200ms降到30ms。这里可以做一个更深入的优化,对于少于5000的客户端,可直接串行调用,反之可并发调用。

问题三:过多的定时器造成cpu开销加大
行情推送里有大量的心跳检测,及任务时间控速,这些都依赖于定时器。go在1.9之后把单个timerproc改成多个timerproc,减少了锁竞争,但四叉堆数据结构的时间复杂度依旧复杂,高精度引起的树和锁的操作也依然频繁。
所以,这里改用时间轮解决上述的问题。数据结构改用简单的循环数组和map,时间的精度弱化到秒的级别,业务上对于时间差是可以接受的。
Golang时间轮的代码已经推到github[3]了,时间轮很多方法都兼容了golang time原生库。有兴趣的可以看下。
问题四:多协程读写chan会出现send closed panic的问题
解决的方法很简单,就是不要直接使用channel,而是封装一个触发器,当客户端关闭时,不主动去close chan,而是关闭触发器里的ctx,然后直接删除topic跟触发器的映射。
// xiaorui.cc
// 触发器的结构type StreamNotifier struct { Guid string Queue chan interface{}
closed int32 ctx context.Context cancel context.CancelFunc}
func (sc *StreamNotifier) IsClosed() bool { if sc.ctx.Err() == nil { return false } return true}
...

问题五:提高grpc的吞吐性能
grpc是基于http2协议来实现的,http2本身实现流的多路复用。通常来说,内网的两个节点使用单连接就可以跑满网络带宽,无性能问题。但在golang里实现的grpc会有各种锁竞争的问题。
如何优化?多开grpc客户端,规避锁竞争的冲突概率。测试下来qps提升很明显,从8w可以提到20w左右。
可参考以前写过的grpc性能测试[4]。

问题六:减少协程数量
有朋友认为等待事件的协程多了无所谓,只是占内存,协程拿不到调度,不会对runtime性能产生消耗。这个说法是错误的。虽然拿不到调度,看起来只是占内存,但是会对 GC 有很大的开销。所以,不要开太多的空闲的协程,比如协程池开的很大。
在推送的架构里,push-gateway到push-server不仅几个连接就可以,且几十个stream就可以。我们自己实现大量消息在十几个stream里跑,然后调度通知。在golang grpc streaming的实现里,每个streaming请求都需要一个协程去等待事件。所以,共享stream通道也能减少协程的数量。

问题七:GC 问题
对于频繁创建的结构体采用sync.Pool进行缓存。有些业务的缓存先前使用list链表来存储,在不断更新新数据时,会不断的创建新对象,对 GC 造成影响,所以改用可复用的循环数组来实现热缓存。
后记
有坑不怕,填上就可以了。
参考资料
https://github.com/rfyiamcool/ccmap/blob/master/syncmap.go
https://github.com/rfyiamcool/go-benchmark/tree/master/batch_notify_channel
https://github.com/rfyiamcool/go-timewheel
https://github.com/rfyiamcool/grpc_batch_test


☞字节跳动辟谣“出售AI技术”和“成立打车项目”;GitHub 因代码版权问题遭抵制;贝佐斯正式卸任亚马逊 CEO|极客头条☞碰上这种 Wi-Fi,iPhone 秒崩!
☞为什么学计算机的学生应该向开源项目做贡献?
以上是关于优化 Golang 分布式行情推送的性能瓶颈的主要内容,如果未能解决你的问题,请参考以下文章