MySQL复习——项目基础使用——事务主从复制分库分表分布式ID雪花算法
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL复习——项目基础使用——事务主从复制分库分表分布式ID雪花算法相关的知识,希望对你有一定的参考价值。
一、 Flask事务
Flask默认开启了事务
应用场景: 多次数据库操作的时候,需要两种或者两种以上的操作,一起成功或者一起失败,可以用到事务
例如: 以下两张表中的数据 需要同时插入,则用到事务,保证成功或者失败
environ = {'wsgi.version':(1,0), 'wsgi.input': '', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/', 'SERVER_NAME': 'itcast server', 'wsgi.url_scheme': 'http', 'SERVER_PORT': '80'}
with app.request_context(environ):
try:
user = User(mobile='18911111111', name='itheima')
db.session.add(user)
db.session.flush() # 将db.session记录的sql传到数据库中执行,以便获取最新的user_id,因为当前sql并没有commit
profile = UserProfile(id=user.id)
db.session.add(profile)
db.session.commit()
except:
db.session.rollback()
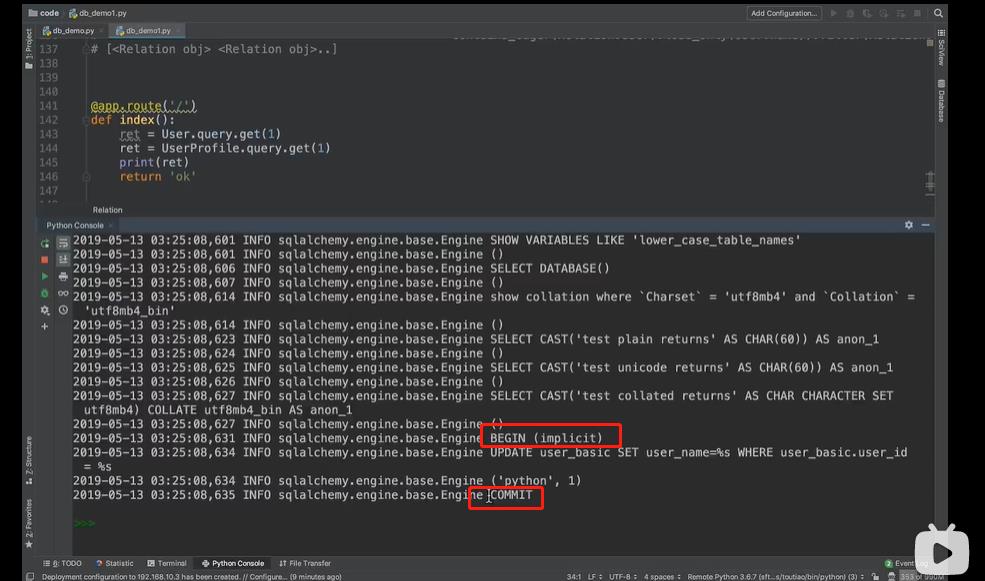
flask 会默认自动开启隐式事务
BEGIN (implicit)开启事务
COMMIT 提交后,终结事务。
操作 db.session 就是操作事务
增删改操作 一定要进行commit, 要不然事务会回滚
数据库事务的四大特征
原子性
指事物包含的所有操作要么全部成功,要么全部回滚。
一致性
指事物必须是数据库从一个一致性状态到另一个一致性状态。也就是说一个事物执行之前和执行之后都必须处于一致性状态。
隔离性
当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事物之间要相互隔离。
关于事务的隔离性数据库提供了多种隔离级别,下面就是。。。
持久性
指事务一旦被提交,那么数据库的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失事务的操作。
事务的隔离级别:
数据库事务的隔离级别有4种,由低到高分别是:Read uncommitted、Read committed、Repeatablead、Serializable。事物的并发操作中可能休闲脏读,不可重复读,幻读。
①Read uncommitted——读未提交
读 未提交,就是一个事务可以读取另一个未提交事务的数据。产生脏读问题
eg:
老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交.。
不commit也能看到,分析:
实际程序员这个月工资还是3.6万,但是程序员看到的是3.9万,他看到的是老板没提交事物的数据。就是脏读。
解决方法:Read commited读提交,能解决脏读问题。
② Read committed——读已提交
读 提交,就是事务要等另一个事物提交后才能读取数据,解决脏读问题,产生不可重复读问题
eg:
程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
分析:
这就是读提交,若有事务对数据进行更新(UPDATE)操作时,读操作事物要等这个更新操作事物提交才能读取数据,可以解决脏读问题。但在这个示例中,出现了一个事物范围内两个相同的查询却返回了不同数据,这就是不可重复读。
解决方法:Repeatable read
③ Repeatable read——可重复读
重复读,就是在开始读取数据(事物开启)时,不再允许修改操作。MySQL是这一级别(默认)。
eg:
程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
分析:
重复读可以解决不可重复读问题。写到这里,应该明白一点就是,不可重复读对应的是修改 UPDATE操作。但是可能会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
什么时候出现幻读?
eg
程序员某一天消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事物开启),看到确实是花了2千元,就在这个时候,程序员花了1万元买了一台电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子提交事务),发现花了1.2万元,似乎出现了幻读,就是幻读。
解决:Serializable
④ Serializable序列化 ——串行
Serializable是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读,不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不用。
大多数数据库默认的事务级别隔离级别是Read committed、比如Sql Server,Oracle。mysql的默认级别是Repeatable read
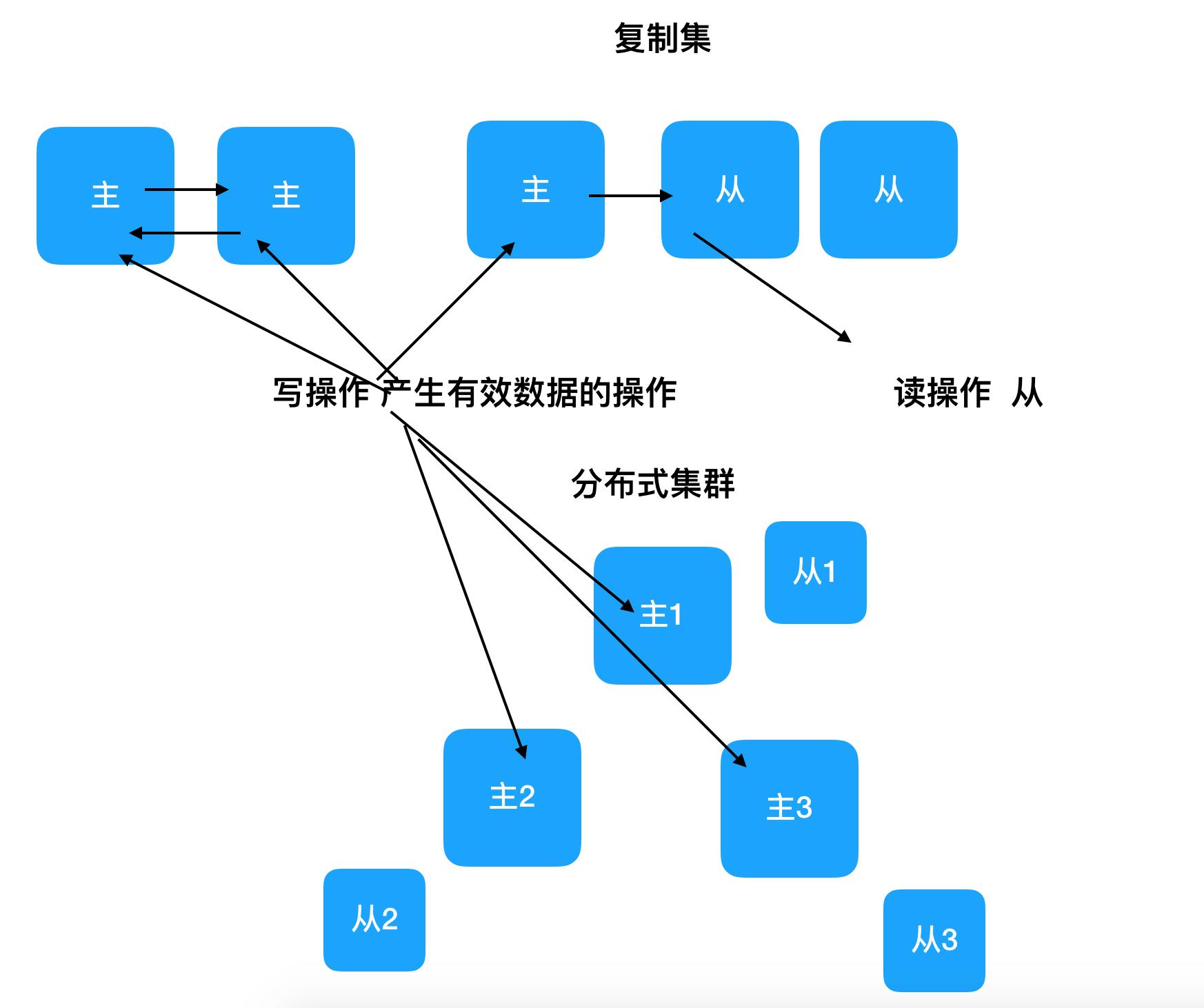
二、复制集与分布式
-
复制集(Replication)
+ 数据库中数据相同,起到备份作用
+ 高可用High Available HA -
分布式(Distribution)
+ 数据库中数据不同,共同组成完整的数据集合
+ 通常每个节点被称为一个分片(shard)
+ 高吞吐High Throughput -
复制集与分布式可以单独使用,也可以组合使用(即每个分片都组建一个复制集)
-
关于主(
Master)从(Slave)
+ 这个概念是从使用的角度来阐述问题的
+ 主节点 -> 表示程序在这个节点上最先更新数据
+ 从节点 -> 表示这个节点的数据是要通过复制主节点而来
+ 复制集 可选 主从、主主、主主从从
+ 分布式 每个分片都是主,组合使用复制集的时候,复制集的是从
三、主从复制
配置主从同步的原因
- 做数据备份
- 配合使用读写分离之后,提供吞吐量 高可用
吞吐量 在一定的时间内处理数据
复制分成三步:
- master将改变记录到二进制日志(
binary log)中(这些记录叫做二进制日志事件,binary log events); - slave将master的
binary log events拷贝到它的中继日志(relay log); - slave重做中继日志中的事件,将改变反映它自己的数据。
下图描述了这一过程:
主从复制
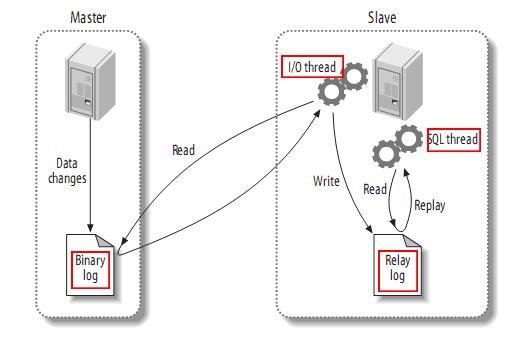
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。
利用主从在达到高可用的同时,也可以通过读写分离提供吞吐量。
思考:读写分离对事务是否有影响?(项目重要)
对于写操作包括开启事务和提交或回滚要在一台机器上执行,分散到多台master执行后数据库原生的单机事务就失效了。
对于事务中同时包含读写操作,与事务隔离级别设置有关,如果事务隔离级别为read-uncommitted 或者 read-committed,读写分离没影响,如果隔离级别为repeatable-read、serializable,读写分离就有影响,因为在slave上会看到新数据,而正在事务中的master看不到新数据。
四、分库分表
分库分表前的问题
任何问题都是太大或者太小的问题,我们这里面对的数据量太大的问题。
-
用户请求量太大
因为单服务器TPS,内存,IO都是有限的。 解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
-
单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库
-
单表太大
CRUD都成问题;索引膨胀,查询超时 解决方法:切分成多个数据集更小的表。
分库分表的方式方法
一般就是垂直切分和水平切分,这是一种结果集描述的切分方式,是物理空间上的切分。 我们从面临的问题,开始解决,阐述: 首先是用户请求量太大,我们就堆机器搞定(这不是本文重点)。
然后是单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。 如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。
如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。 分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式。
垂直拆分
-
垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
2.垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么? 我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
水平拆分
-
水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用。
-
水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
-
水平分库分表切分规则
-
①RANGE
从0到10000一个表,10001到20000一个表;
② HASH取模 离散化
一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
③地理区域
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
④时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”
分库分表后面临的问题
事务支持
-
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
-
多库结果集合并(
groupby,orderby) -
跨库
join分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
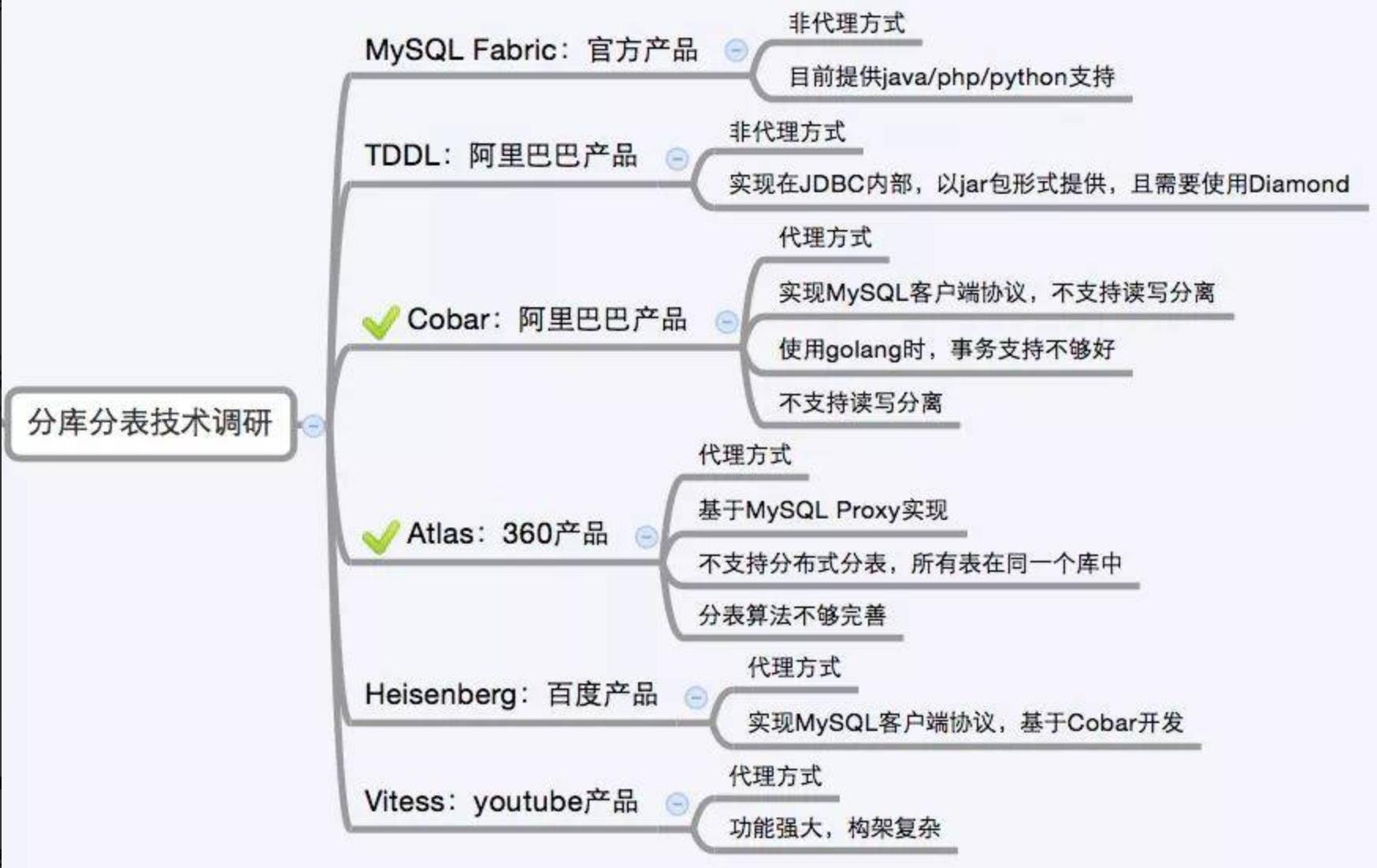
分库分表方案产品
目前市面上的分库分表中间件相对较多,其中基于代理方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
五、分布式ID
水平分表时,怎么让主键 id 不重复?
分布式ID
1 方案选择
① UUID
UUID是通用唯一识别码(Universally Unique Identifier)的缩写,开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
UUID是由128位二进制组成,一般转换成十六进制,然后用String表示。
550e8400-e29b-41d4-a716-446655440000
UUID的优点:
- 通过本地生成,没有经过网络I/O,性能较快
- 无序,无法预测他的生成顺序。(当然这个也是他的缺点之一)
UUID的缺点:
- 128位二进制一般转换成36位的16进制,太长了只能用String存储,空间占用较多。
- 不能生成递增有序的数字
② 数据库主键自增
大家对于唯一标识最容易想到的就是主键自增,这个也是我们最常用的方法。例如我们有个订单服务,那么把订单id设置为主键自增即可。
-
单独数据库 记录主键值
-
业务数据库分别设置不同的自增起始值和固定步长,如
第一台 start 1 step 9
第二台 start 2 step 9
第三台 start 3 step 9
优点:
- 简单方便,有序递增,方便排序和分页
缺点:
- 分库分表会带来问题,需要进行改造。
- 并发性能不高,受限于数据库的性能。
- 简单递增容易被其他人猜测利用,比如你有一个用户服务用的递增,那么其他人可以根据分析注册的用户ID来得到当天你的服务有 多少人注册,从而就能猜测出你这个服务当前的一个大概状况。
- 数据库宕机服务不可用。
③ Redis
熟悉Redis的同学,应该知道在Redis中有两个命令Incr,IncrBy,因为Redis是单线程的所以能保证原子性。
优点:
- 性能比数据库好,能满足有序递增。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
④ 雪花算法-Snowflake
Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数:
snowflake
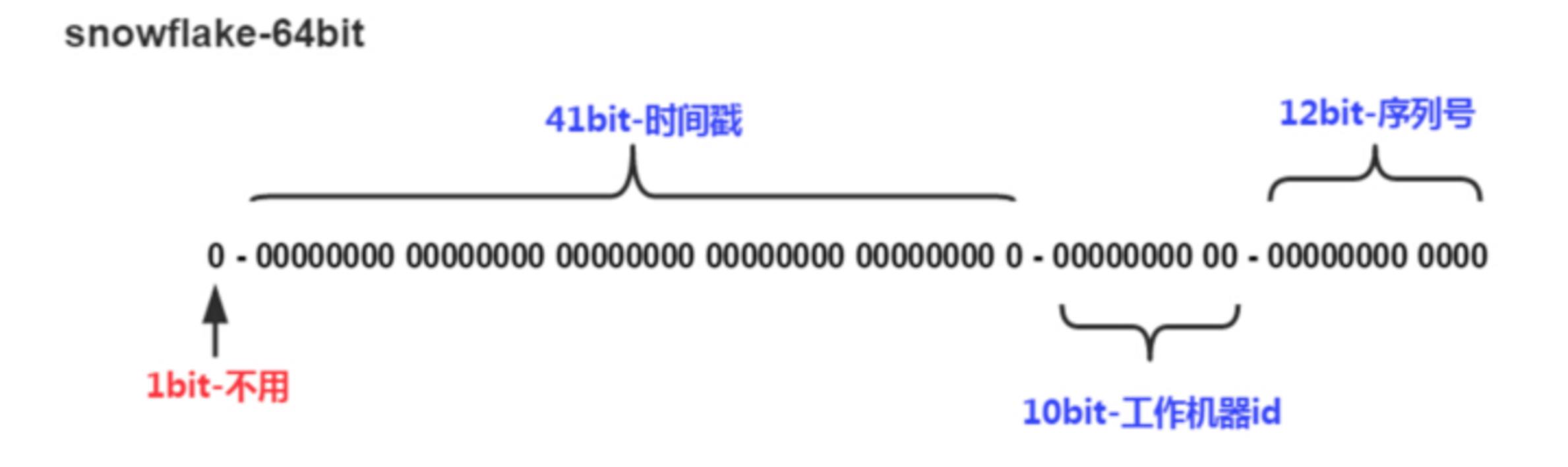
- 1bit:一般是符号位,不做处理
- 41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
- 10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
- 12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
上面只是一个将64bit划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
- 服务目前QPS10万,预计几年之内会发展到百万。
- 当前机器三地部署,上海,北京,深圳都有。
- 当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。
snowflake

时钟回拨
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,算法会直接抛出异常.
雪花算法实例
使用雪花算法 (代码 toutiao-backend/common/utils/snowflake)
# Twitter's Snowflake algorithm implementation which is used to generate distributed IDs.
# https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala
import time
import logging
class InvalidSystemClock(Exception):
"""
时钟回拨异常
"""
pass
# 64位ID的划分
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
# 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# 移位偏移计算
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter元年时间戳
TWEPOCH = 1288834974657
logger = logging.getLogger('flask.app')
class IdWorker(object):
"""
用于生成IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 其实序号
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp()
# 时钟回拨
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests until {}'.format(self.last_timestamp))
raise InvalidSystemClock
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \\
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())
以上是关于MySQL复习——项目基础使用——事务主从复制分库分表分布式ID雪花算法的主要内容,如果未能解决你的问题,请参考以下文章