RocketMQ主机磁盘空间有限,无限期延长消息存储的一种解决方案
Posted NetWhite
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ主机磁盘空间有限,无限期延长消息存储的一种解决方案相关的知识,希望对你有一定的参考价值。
前言
RocketMQ作为国人开源的一款消息引擎,相对kafka也更加适合在线的业务场景,在业内使用的也是非常广泛,很多同学也是非常熟悉它及它的存储机制,所以这里不再对它的原理性东西作太多说明。
我们也知道,RocketMQ所有的数据如消息信息都是以文件形式保存到broker节点所在主机上指定的分区目录下,比如消息的数据都是保存在commitlog中,默认保存72小时(在磁盘使用率未达到阈值的情况下)会在指定时间清理过期数据,释放磁盘空间。
当然,如果消息量不大且所在磁盘的分区够大,我们可以增加消息的保存时间。但受限于磁盘大小,这个保存时间总归有限,如果消息比较重要,或者我们想保存的更久一些就需要一些其它方案解决。
背景
我们线上的几个集群目前消息保存时间在2-3天,实在是磁盘空间大小有限,消息量相对不算小。比如,有个比较核心的集群,部署方式是6个高配物理机采用DLedger模式4主8从交叉部署,发送的tps在10000多,所以每个节点的日消息量目前应该是在600G吧。老大给我说他现在设置的线上保存时间是2天,业务量一直在增加,继续增长下去,就要设置保存1天了,目前每个节点的磁盘使用率将近50%,年初我搭建监控平台的时候,注意过还没这么高。

还有其它集群上的业务,有些业务相关开发人员想要他们消息保存7天甚至更久。
基于这些原因,所以我们也的确需要一种过期消息备份的解决方案。
解决思路
如果需要对过期消息进行备份,然后支持过期消息检索及重新消费的能力,我们想到的,常规的方案有如下两种:
- 将发送到broker的消息持久化一份到第三方存储介质,如mysql
- 备份将要过期的commitlog到其它地方,重新恢复
业内大厂是采用哪些更好的方案,时间问题也没有具体调研过,我不得而知。关于第一种方案,老大也跟我聊过,我是不倾向的,原因如下:
- 我们的消息代理平台还没有建设出来,业务用的基本都是原生的,如果想要在消息生命周期中镜像一份出来到其它存储系统,在不改源码的情况下,确实没有很好的切入点
- 依赖其它存储介质,复杂性,开发成本也高,我的开发时间也不充裕,短期内实现这个,有点难
- 全量保存的话,消息体的减少很难有质的变化,当然可以在处理的时候,去掉一些元数据信息,消息体也可以压缩减少存储空间的占用,但无论存哪,质量守恒,不会换个地方,用的硬盘资源就能等比减少很多倍
当然,这种方案的好处也很明显,可以更精细化的控制保存时间及消息类别,设定对哪些topic或哪类消息的保存时限。另外如果我们的MQ代理层建设完,无论是RocketMQ还是kafka等都可以采用一种通用方案备份。
我目前主要采用第2种解决方案并进行实现,备份commitlog,支持检索和重新消费。主要思路就是,开发一个应用,备份集群里将要过期的commitlog到更大的磁盘空间的主机(一台主机,备份整个集群的数据,且硬件配置不需要太高,硬盘尽量大即可),并提供接口,支持检索消息。
解决方案
基本实现
我们的主要目标是让消息保存的更久一些,不是为了灾备什么的,所以不需要双活、冷备这样搭建一个同等的部署模型的集群。况且资源有限,不可能再申请同配置或者低配的主机资源解决,比如上面那个4主8从Dledger模式,如果需要同样的集群来解析commitlog检索消息,至少也需要4主4从部署8个节点才行,双活太浪费,冷备维护也不方便。主要原因是资源也不好申请。
我用了一周的时间,紧赶赶的写了一个工具能支持备份commitlog及检索消息:rocketmq-reput。
该工具支持3种模式:客户端、服务器及混合模式
- 客户端:部署在broker节点,定时扫描上传将要过期的commitlog
- 服务器:保存过期的commitlog并支持消息检索
- 混合模式:同时开启客户端和服务器模式,无限期备份的关键
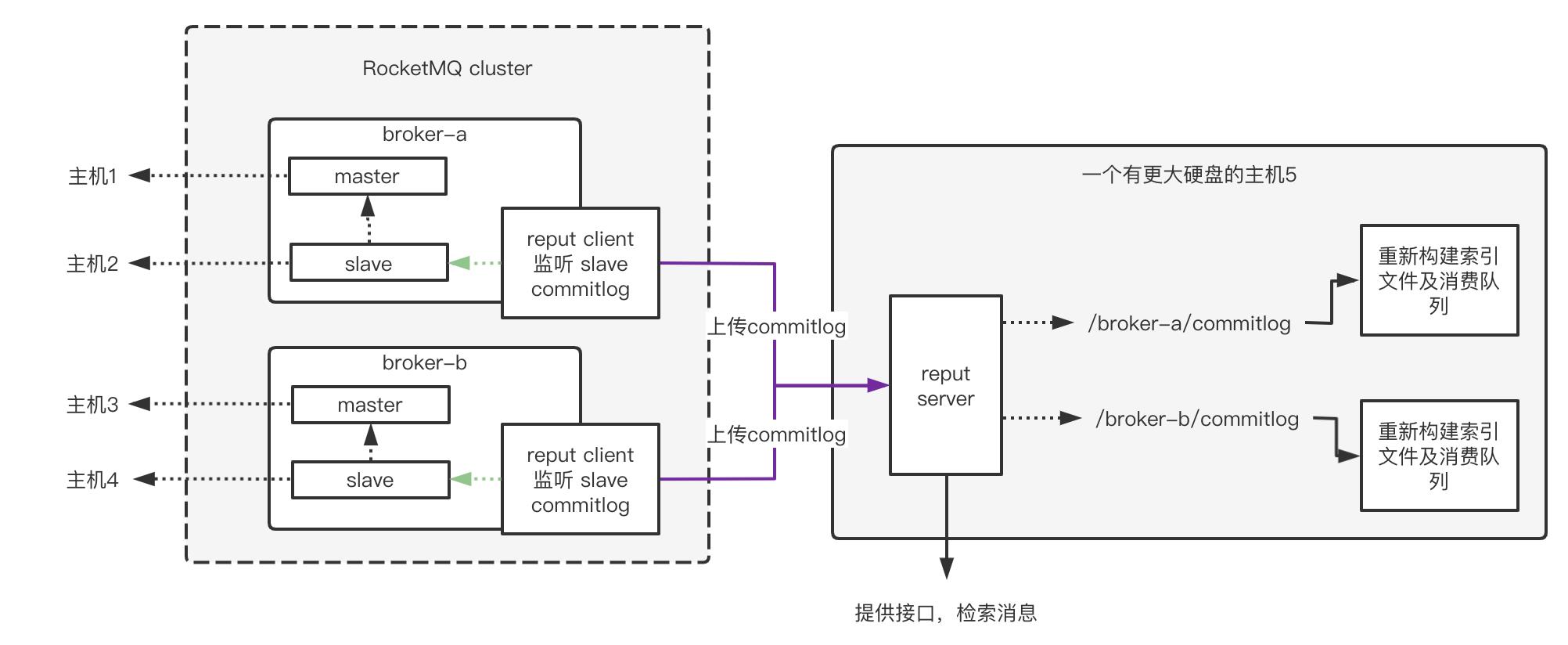
主要流程如下:
- 将reput client部署到rokcetmq集群的各个broker的从节点上,配置监听的commitlog目录,定时扫描将要过期的commitlog上传到reput server上。
- reput server接收client传来的commit log并根据不同的broker存放在不同的目录下。
- 重新分发commit log的消息(所以我起名reput),构建索引文件(消息检索使用)和逻辑消费队列。
- 在reput server端可以通过restful接口查询指定topic的历史消息(根据时间范围、消息ID[客户端ID/服务端ID],消息key等)
数据上传
从方案到开发,因为时间上的原因,我也没太多时间花费在这上面,所以在实现上并没有太注意细节,开发上也比较粗糙。
数据上传这里也是很简单的压缩->传输->校验->保存,基本流程如下:
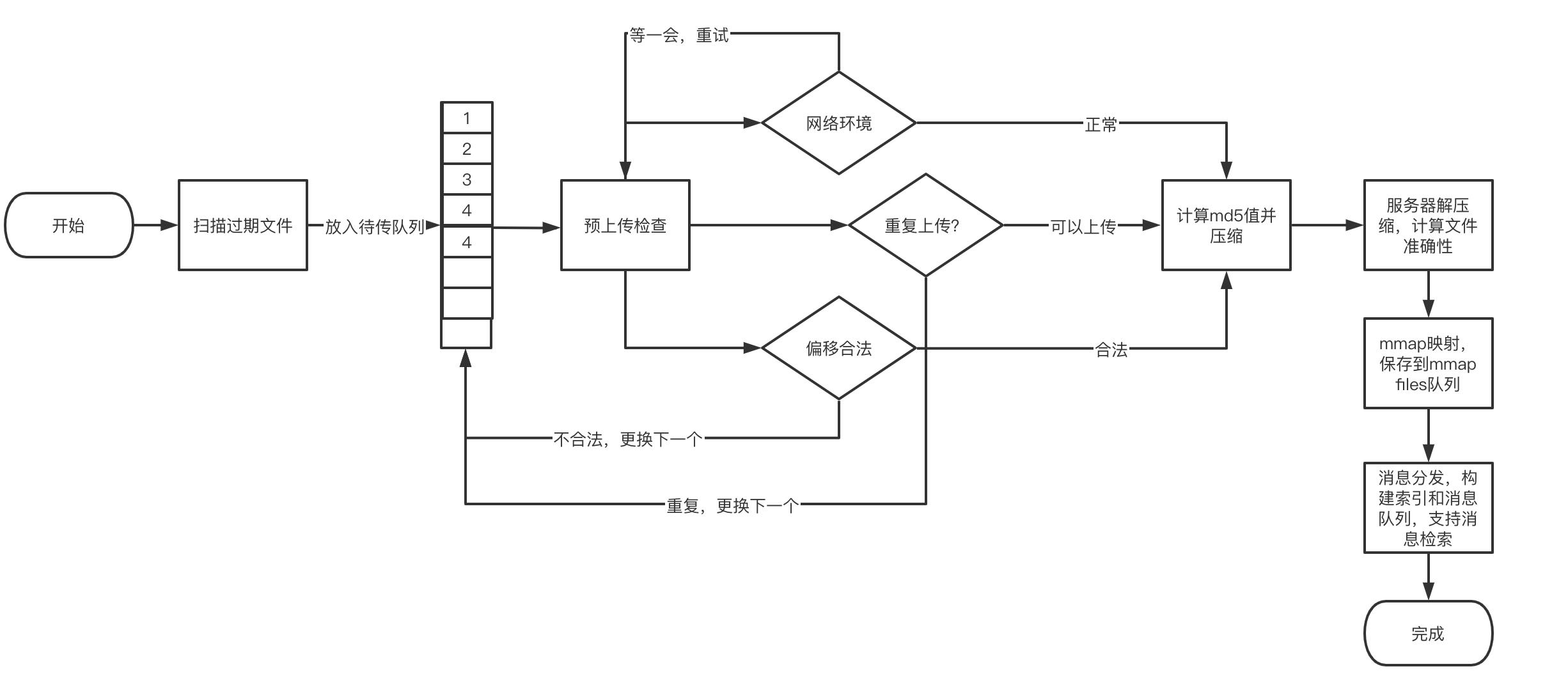
如果上传到一半服务器关闭等原因导致客户端当前文件上传失败,会重置队列,重新检查上传文件,避免有commitlog遗漏。
主机配置
该工具在执行时,大多情况下不需要太多算力,所以CPU是双核的即可,内存4G足够,堆内存配置2G就行,需要留一些物理内存给操作系统的page cache。我目前测试的时候,堆内存只配置了512M,挺好。
reput client尽量部署在从节点上,可以减少对master的影响。
另外开发的时候,为了节省时间,减少开发的代码,像文件压缩和md5检查,都是直接调用的shell 命令,这也导致不支持在windows平台下使用,只能在mac 和linux上运行,mac os不检查md5,只检查文件长度是否一致。
因为执行脚本命令的原因,会占用一些额外的性能,我观测的有以下几点:
- 压缩的时候一个cpu的核心使用率达到100%,所以要求最低双核cpu,单核会影响broker的处理性能
- 网络传输带宽占用在50M/s,其实压缩比挺高,一般在72%-92%吧,100M-300M之间,所以传输时间大概在2-6秒吧,如果本身带宽是瓶颈,需要注意
- 硬盘,硬盘得够大,毕竟要保存整个集群的commitlog
无限期备份方案
硬盘即使再大,但空间大小也有上限,所以能保存消息量也有限,比如一个节点消息量600-700G左右,4个节点一天的量就在2.5T左右,即使申请了一个8T的硬盘,也只能保存2天(3天是不可能了)。
reput自身也是和rockemq一样的过期删除策略(这部分代码直接copy rocketmq的实现的),所以数据在reput server上过期也要被清除释放磁盘空间。
所以目前reput支持混合模式,可以再申请一台主机,当前reput作为客户端,新reput作为server,将快要过期的文件以同样方式传输过去保存,完整流程如下:
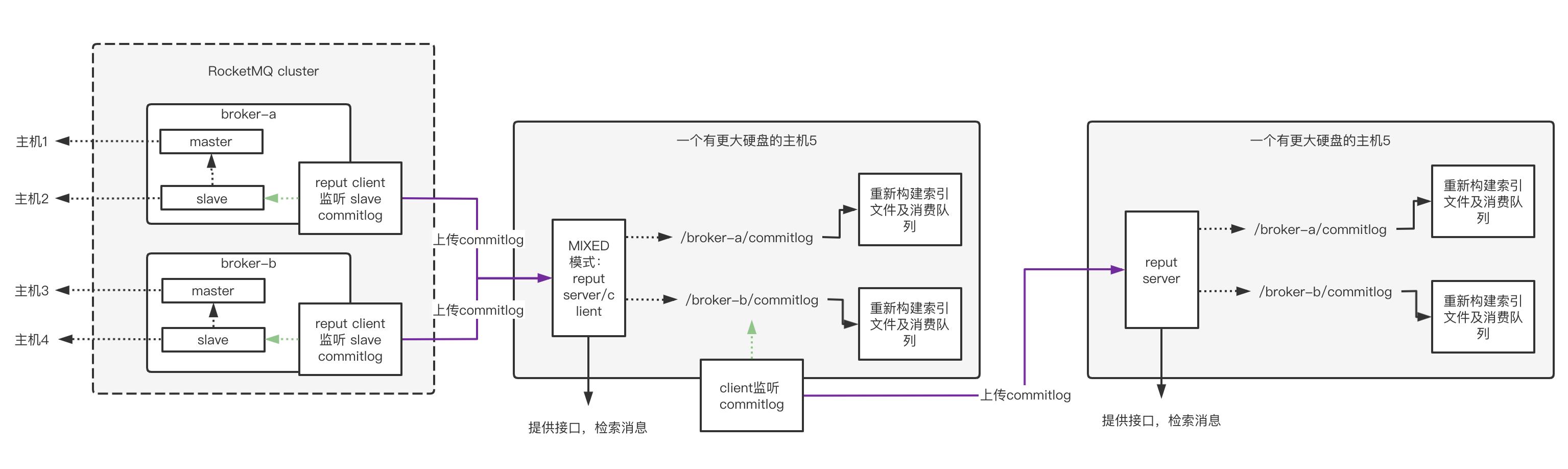
就以这种接力的方式一直保存下去,一个主机保存2天,想要保存多久,就申请多少主机吧。
消息检索
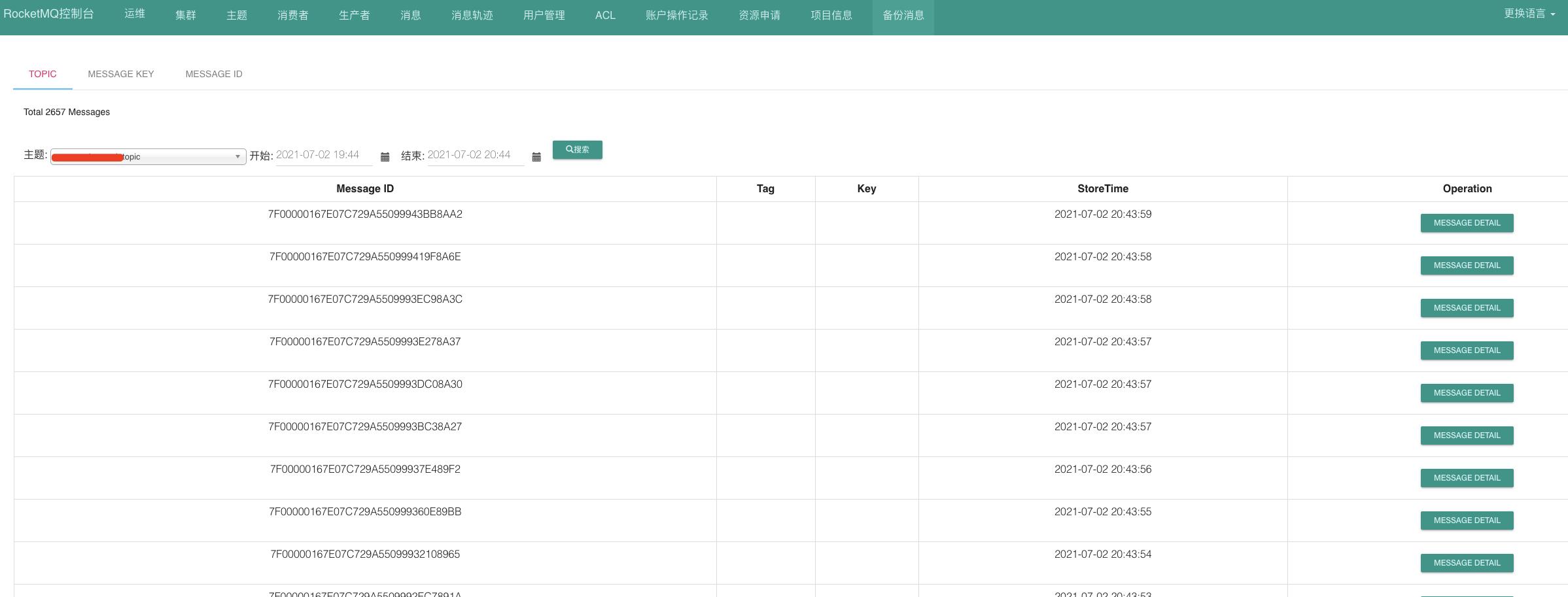
消息检索,为了方便和省事,我直接在rocketmq-console控制台新开发一个历史消息的页面用来查询消息,reput server会以心跳的方式将自己可查询的时间段及地址注册到控制台上。
在控制台上选择topic和时间段,然后根据选择的时间段符合条件的一个或多个reput server上获取消息。如果是消息ID或消息key,那就只能到所有的server上一起查了,只要消息还在,总能查到返回。
效果如下,我还可以查到4天前的消息(测试的这个集群配置的是保存2天的数据):
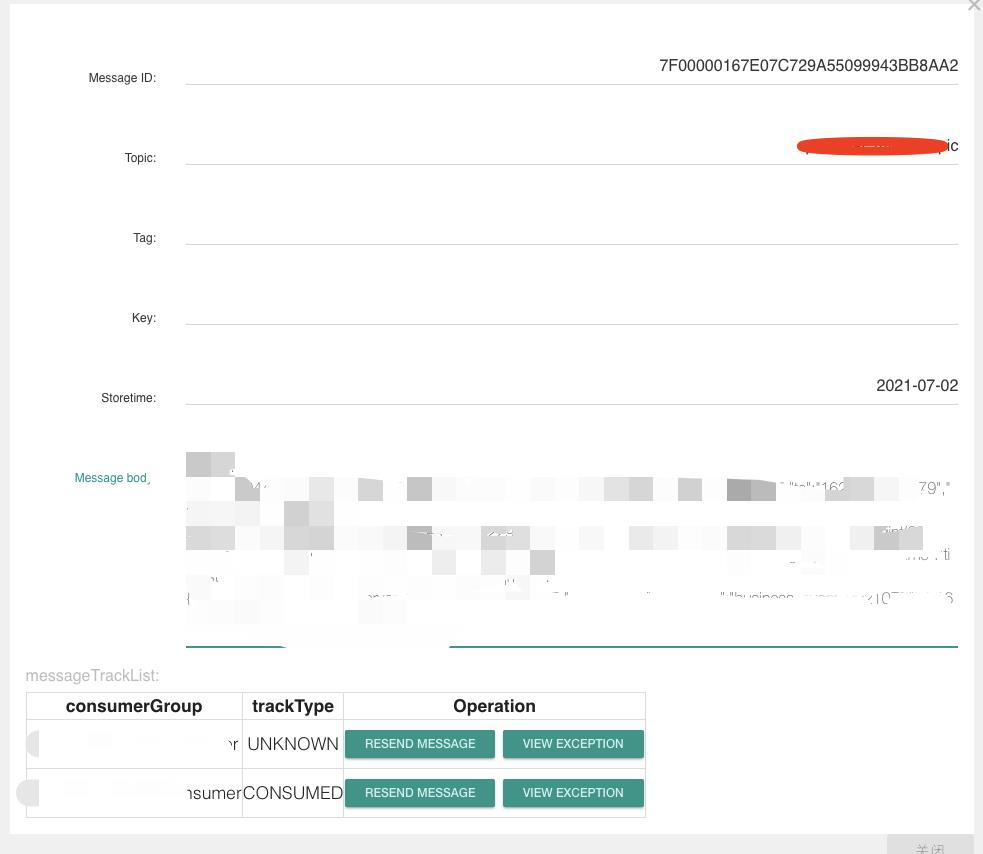
重新消费
重新消费可以将要消费的历史消息检索出来,重新发回broker。
写在最后
其实开发上还是遇到不少问题点,比如因为commtlog的生成方式和rocketmq自身的生成是不一样的,rocketmq是在写入消息的时候,commitlog写不下了才会创建。在重新构建索引和消息队列的时候基于原有流程有些场景走不通,无法直接滚到下个文件等。
我是每个环节一一开发进行验证的,最终把所有环节走通,写了个完整流程的demo。这个demo最初验证的时候,我是直接提到github了,基本功能性也都有,感兴趣可以玩一下:https://github.com/xxd763795151/rocketmq-reput
我把基本启停脚本也简单补充了下,只是上面有些bug后来就没在修改。
整个流程走通后,我就修改包名提交到私服了,后续的开发包括和rocketmq-console的联调,支持可视化检索消息等都是在私服的代码仓库上,这部分功能及后续的bug修复,这个demo上是没有了。但是这份demo代码已支持消息检索,也提供的有接口,可以直接调用接口检索消息看结果,接口说明如下:
/**
* get the total of message between startTime and endTime.
*
* @param topic topic name.
* @param startTime start time.
* @param endTime end time.
* @return a long value, the total of message between startTime and endTime.
*/
@GetMapping("/total/{topic}/{startTime}/{endTime}")
public Object getMessageTotalByTime(@PathVariable String topic, @PathVariable long startTime,
@PathVariable long endTime) {
return ResponseData.create().success().data(messageService.getMessageTotalByTime(topic, startTime, endTime));
}
/**
* get the message list between startTime and endTime.
*
* @param topic topic name.
* @param startTime start time.
* @param endTime end time.
* @return List(MessageExt), he message list between startTime and endTime.
*/
@GetMapping("/list/{topic}/{startTime}/{endTime}")
public Object getMessageByTime(@PathVariable String topic, @PathVariable long startTime,
@PathVariable long endTime) {
return ResponseData.create().success().data(messageService.getMessageByTime(topic, startTime, endTime));
}
/**
* get the message list between startTime and endTime. It differs from the above getMessageByTime is that the
* message body is null , as a result, the size is smaller when return the same messages.
*
* @param topic topic name.
* @param startTime start time.
* @param endTime end time.
* @return List(MessageExt), he message list between startTime and endTime.
*/
@GetMapping("/view/{topic}/{startTime}/{endTime}")
public Object viewMessageList(@PathVariable String topic, @PathVariable long startTime,
@PathVariable long endTime) {
return ResponseData.create().success().data(messageService.viewMessageList(topic, startTime, endTime));
}
/**
* get message by message id(server id(offset id) or client id(unique key)).
*
* @param topic topic name
* @param msgId msg id: server id/ client id.
* @return {@link org.apache.rocketmq.common.message.MessageExt}
*/
@GetMapping("/id/{topic}/{msgId}")
public Object queryMessageByMsgId(@PathVariable final String topic, @PathVariable final String msgId) {
return ResponseData.create().success().data(messageService.queryMessageByMsgId(topic, msgId));
}
/**
* get message by message key.
*
* @param topic topic name
* @param key msg key: custom business key/ client id.
* @return {@link org.apache.rocketmq.common.message.MessageExt}
*/
@GetMapping("/key/{topic}/{key}")
public Object queryMessageByKey(@PathVariable final String topic, @PathVariable final String key) {
return ResponseData.create().success().data(messageService.queryMessageByKey(topic, key));
}这个实现是支持Dledger模式与常规的部署模型的。最近在测试环境(2主2从非DLedger模式)运行了几天,看了下效果,结果挺预期的,可以验证该方案是完全可行的。
以上是关于RocketMQ主机磁盘空间有限,无限期延长消息存储的一种解决方案的主要内容,如果未能解决你的问题,请参考以下文章