智汇华云 | RabbitMQ集群揭秘
Posted 华云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智汇华云 | RabbitMQ集群揭秘相关的知识,希望对你有一定的参考价值。

RabbitMQ随着云计算的发展已经成为现在企业中使用最广泛的消息队列,而企业中使用Rabbitmq通常都采用集群模式,通过集群模式,可以相比单节点的rabbitmq提供高可用性,高吞吐量,数据安全。
本期“智汇华云”为您邀请到华云数据网络组高级云计算工程师张胜带来“RabbitMQ集群揭秘”,分享目前Rabbitmq集群模式的常见分区策略使用方式,以及探讨一下常见问题,同时给出解决办法。
本期嘉宾

张胜
华云数据网络组
高级云计算工程师
Rabbitmq集群特点
集群中的所有节点都是平等的,意味着客户端可以连接到任意一个节点进行消息发送接收。
如图:
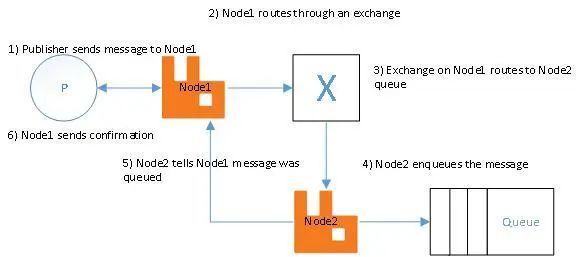
发送者连接到Node1,而队列建立在Node2上,Rabbitmq可以自动把消息发送到Node2上的Queue中,客户端不需要知道消息具体存储在哪个节点。
Rabbitmq集群组成
Erlang虚拟机组成集群。Erlang作为天生支持分布式的语言,轻而易举:
1. 所有节点设置同样的cookie,相当于认证。
2. 加入集群。
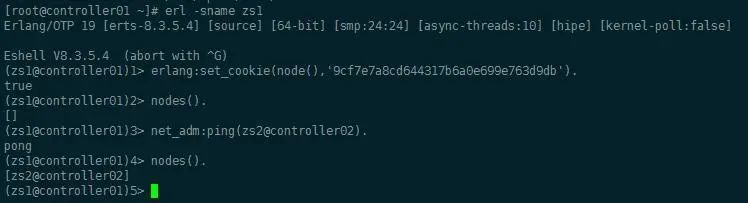
Mnesia分布式数据库组成集群,所有运行时数据在集群内都是同步更新的,除了message queues。

Rabbitmq集群,在前面两个集群都正常的基础上,Rabbitmq对外提供服务。
Rabbitmq集群管理
使用rabbitmqctl命令来进行集群的管理。
创建集群

离开集群

Rabbitmq集群分区策略
分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。1998年,加州大学的计算机科学家 Eric Brewer 提出,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
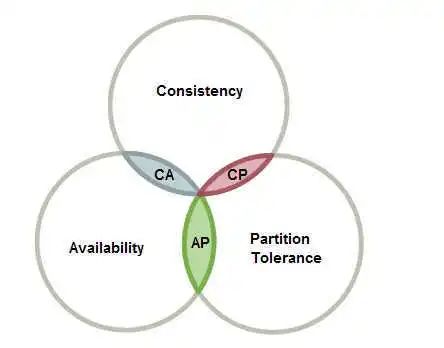
CP:网络分区的时候某些数据会不可用,MongoDB,Hbase,Memcache,Redis
AP:网络分区的时候客户端读到不一致的数据,Cassandra,Riak,CouchDB
CA:网络分区的时候停止系统,传统mysql
Rabbitmq集群也是逃不掉这个定理,使用的Mnesia分布式数据库属于AP类型。
Rabbitmq使用cluster_partition_handling参数对分区策略进行配置。
ignore(默认)不做任何处理,该怎么样就怎么样,就像没发生过。
autoheal 分区结束的时候自动从client数最多的分区恢复数据库。达到自动愈合的效果。
pause_minority 分区开始的时候自动停止少数派(小于n/2+1)
pause_if_all_down(复杂)还带两个额外参数
· nodes 定义这些节点联系不上的时候本节点就停止工作
· recover 定义节点重新连接上时执行什么策略恢复· ignore
· autoheal
这里我主要介绍一下pause_minority模式以及其中的坑。
代码文件rabbit_node_monitor.erl负责集群的状态监控,使用了OTP的gen_server behavior,直接定位到handle_info监听nodedown信息的地方。
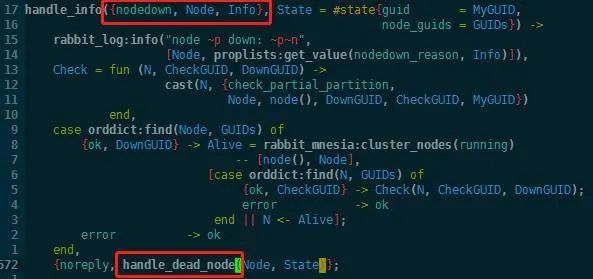
代码中最后对这个dead节点执行handle_dead_node操作:
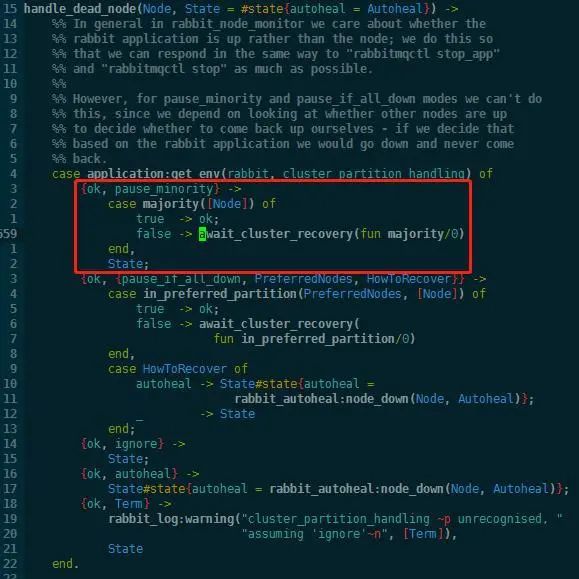
这里主要关注pause_minority分支,如果自己所在分区不是majority,就要等待集群恢复到majority才对外服务,调用rabbit:stop停止服务,然后等待。
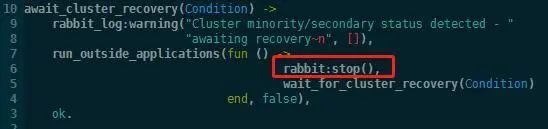
持续ping对方,每一秒ping一次。

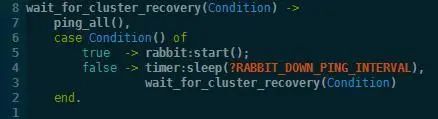
少数方停止,多数方继续对外服务,网络恢复之后,erlang集群恢复正常,ping通过,执行rabbit:start启动服务。
程序逻辑看上去没有问题,但是实际使用中,经常会报出集群脑裂,少数方也开始对外提供服务了。
经过调查,发现是当少数方等待集群回复正常的期间,被systemctl restart了,导致erlang虚拟机重启,而rabbitmq在erlang重启的时候不会认为自己是少数方,就开始对外服务了。
之后网络分区恢复,就出现了mnesia数据库不一致。
所以在使用pause_minority模式时,不能随意重启rabbitmq-server,程序会在分区恢复的时候自动对外服务。
另外pause_minority也不适用于双节点集群,还有不能让电脑休眠,大家想想是为什么呢?
模式的选择使用参考
Rabbitmq集群未来
Rabbitmq 4.0版本中预计会引入mnevis(mnesia分布式数据库的raft版本)。
An update from the RabbitMQ team (version 3.8)
利用Raft共识算法从数据库层面解决网络分区导致的数据一致性问题。
实验性的测试版本在:
https://github.com/rabbitmq/mnevis
https://github.com/rabbitmq/rabbitmq-server/tree/mnevis-experimental
感兴趣的可以自己玩玩看。最后问一下使用了Raft共识算法的Rabbitmq集群是CAP中的哪种呢?
相关阅读
点击原文链接,了解华云数据更多信息
以上是关于智汇华云 | RabbitMQ集群揭秘的主要内容,如果未能解决你的问题,请参考以下文章
智汇华云 | 通过TProxy实现haproxy 透传用户IP