从0到1Flink的成长之路(二十)-Flink 高级特性之End-to-End Exactly-Once 实现
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(二十)-Flink 高级特性之End-to-End Exactly-Once 实现相关的知识,希望对你有一定的参考价值。
End-to-End Exactly-Once 实现
Flink内部借助分布式快照Checkpoint已经实现了内部的Exactly-Once,但是Flink自身是无法保证外部其他系统“精确一次”语义的,所以Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;然后借助一些其他手段才能实现
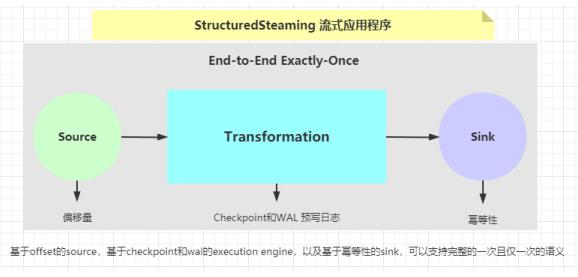
StructuredStreaming 流式应用程序精确一次性语义实现:
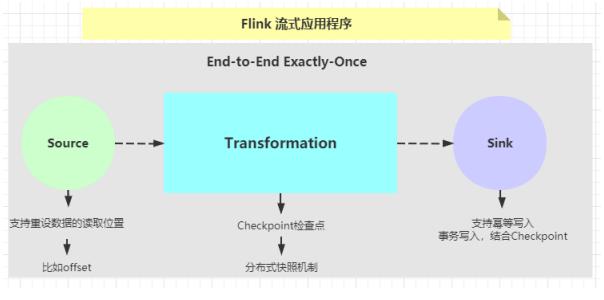
Flink 流式应用程序精确一次性语义实现
Source
发生故障时需要支持重设数据的读取位置,如Kafka可以通过offset来实现(其他的没有offset系统,可以自己实现累加器计数)。
Transformation
Flink内部已经通过Checkpoint保证了,如果发生故障或出错时,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般。
分布式快照机制
在之前的课程中讲解过 Flink 的容错机制,Flink 提供了失败恢复的容错机制,而这个容错机制的核心就是持续创建分布式数据流的快照来实现。
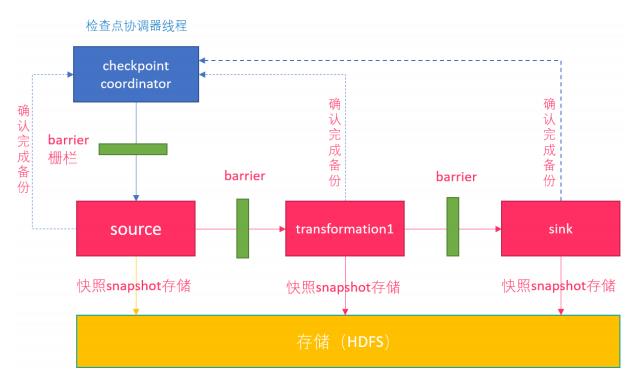
同 Spark 相比,Spark 仅仅是针对 Driver 的故障恢复 Checkpoint。而 Flink 的快照可以到算子级别,并且对全局数据也可以做快照。Flink 的分布式快照受到 Chandy-Lamport 分布式快照算法启发,同时进行了量身定做。
Barrier
Flink 分布式快照的核心元素之一是 Barrier(数据栅栏),也可以把 Barrier 简单地理解成一个标记,该标记是严格有序的,并且随着数据流往下流动。每个 Barrier 都带有自己的 ID,Barrier 极其轻量,并不会干扰正常的数据处理。
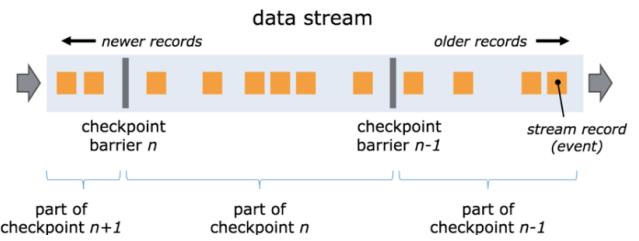
如上图所示,假如有一个从左向右流动的数据流,Flink 会依次生成 snapshot 1、 snapshot
2、snapshot 3……Flink 中有一个专门的“协调者”负责收集每个 snapshot 的位置信息,这个“协调
者”也是高可用的。
Barrier 会随着正常数据继续往下流动,每当遇到一个算子,算子会插入一个标识,这个标识的插入时间是上游所有的输入流都接收到 snapshot n。与此同时,当sink 算子接收到所有上游流发送的 Barrier 时,那么就表明这一批数据处理完毕,Flink 会向“协调者”发送确认消息,表明当前的 snapshot n 完成了。当所有的 sink 算子都确认这批数据成功处理后,那么本次的snapshot 被标识为完成
有一个问题,因为 Flink 运行在分布式环境中,一个 operator 的上游会有很多流,每个流的 barrier n 到达的时间不一致怎么办?这里 Flink 采取的措施是:快流等慢流。
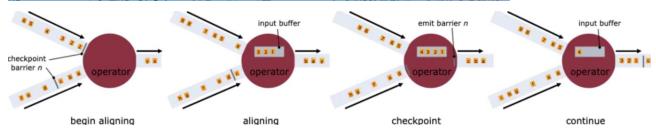
拿上图的 barrier n 来说,其中一个流到的早,其他的流到的比较晚。当第一个 barrier n到来后,当前的 operator 会继续等待其他流的 barrier n。直到所有的barrier n 到来后,operator 才会把所有的数据向下发送。
异步和增量
按照上面介绍的机制,每次在把快照存储到我状态后端时,如果是同步进行就会阻塞正常任务,从而引入延迟。因此 Flink 在做快照存储时,可采用异步方式。
此外,由于 checkpoint 是一个全局状态,用户保存的状态可能非常大,多数达 G 或者 T 级别。在这种情况下,checkpoint 的创建会非常慢,而且执行时占用的资源也比较多,因此Flink 提出了增量快照的概念。也就是说,每次都是进行的全量 checkpoint,是基于上次进行更新的。
以上是关于从0到1Flink的成长之路(二十)-Flink 高级特性之End-to-End Exactly-Once 实现的主要内容,如果未能解决你的问题,请参考以下文章