大数据实时+离线项目架构----智慧物流大数据平台(超流行框架!)
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实时+离线项目架构----智慧物流大数据平台(超流行框架!)相关的知识,希望对你有一定的参考价值。
智慧物流大数据平台
一、项目背景
本项目基于一家大型物流公司研发的智慧物流大数据平台。该物流公司是国内综合性快递、物流服务商,并在全国各地都有覆盖的网点。经过多年的积累、经营以及布局,拥有大规模的客户群,日订单达上千万。如此规模的业务数据量,传统的数据处理技术已经不能满足企业的经营分析需求。公司需要基于大数据技术构建数据中心,从而挖掘出隐藏在数据背后的信息价值,为企业提供有益的帮助,带来更大的利润和商机。大数据项目主要围绕订单、运输、仓储、搬运装卸、包装以及流通加工等物流环节中
涉及的数据、信息等。通过大数据分析可以提高运输以及配送效率、减少物流成本、更有效地满足客户服务要求,实现快速、高效、经济的物流,并针对数据分析结果,提出具有中观指导意义的解决方案。针对物流行业的特性,大数据应用主要体现在车货匹配、运输路线优化、库存预测、设备修理预测、供应链协同管理等方面。
二、逻辑架构
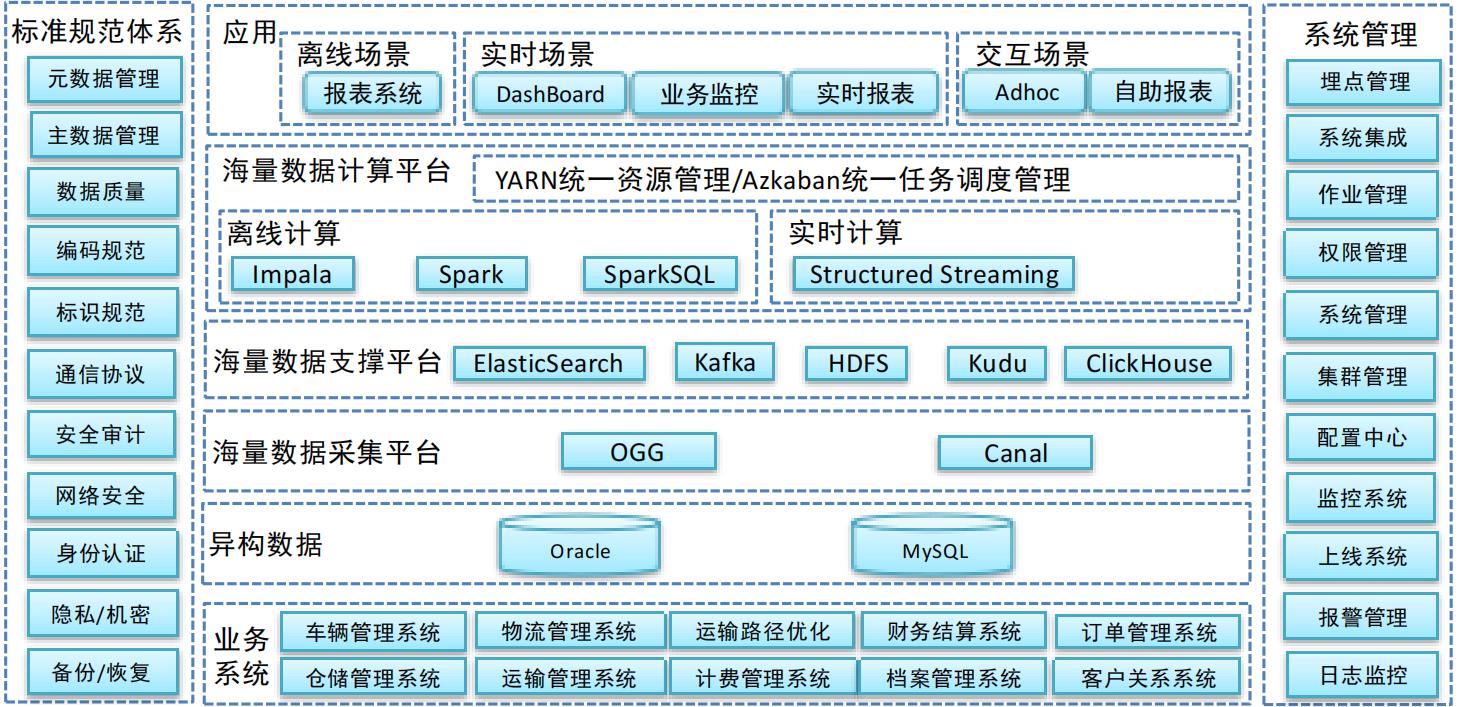
异构数据源
数据源主要有两种方式:Oracle数据库、mysql数据库
数据采集平台
数据采集平台负责将异构数据源采集到数据存储平台,分为批量导入以及实时采集两个部分:
实时采集 Oracle数据库采用ogg进行实时采集,MySQL数据库采用Canal进行实时采集。采集到的数据会存放到消息队列临时存储中。
数据存储平台
本次建设的物流大数据平台存储平台较为丰富。因为不同的业务需要,存储分为以下几个部分
Kafka 作为实时数据的临时存储区,方便进行实时ETL处理
Kudu 与Impala mpp计算引擎对接,支持更新,也支持大规模数据的存储
HDFS 存储温数据、冷数据。大规模的分析将基于HDFS存储进行计算。
ElasticSearch 所有业务数据的查询都将基于ElasticSearch来实现
ClickHouse 实时OLAP分析
数据计算平台
数据计算平台主要分为离线计算和实时计算。
离线计算 Impala:提供准实时的高效率OLAP计算、以及快速的数据查询
Spark/ SparkSQL:大批量数据的作业将以Spark方式运行
ElasticSearch 所有业务数据的查询都将基于ElasticSearch来实现
大数据平台应用
离线场景 报表系统
小区画像
实时场景 DashBoard
业务监控
实时报表
交互查询 AdHoc(即席查询)
自助报表
三、解决方案
数据源:关系型数据库Oracle和MySQL
采集:OGG和Canal分别将Oracle和MySQL的增量数据同步到Kafka集群
存储:ETL计算之后分别存储到kudu,Elasticsearch,ClickHouse中
计算引擎:处理数据使用StructuredStreaming
技术亮点:
完整Lambda 架构系统,有离线业务、也有实时业务
ClickHouse实时存储、计算引擎
Kudu + Impala准实时分析系统
基于Docker 搭建异构数据源,还原企业真实应用场景
以企业主流的Spark生态圈为核心技术,例如:Spark、Spark SQL、structured Streaming
Elasticsearch 全文检索
SpringCloud 搭建数据服务
数据流转
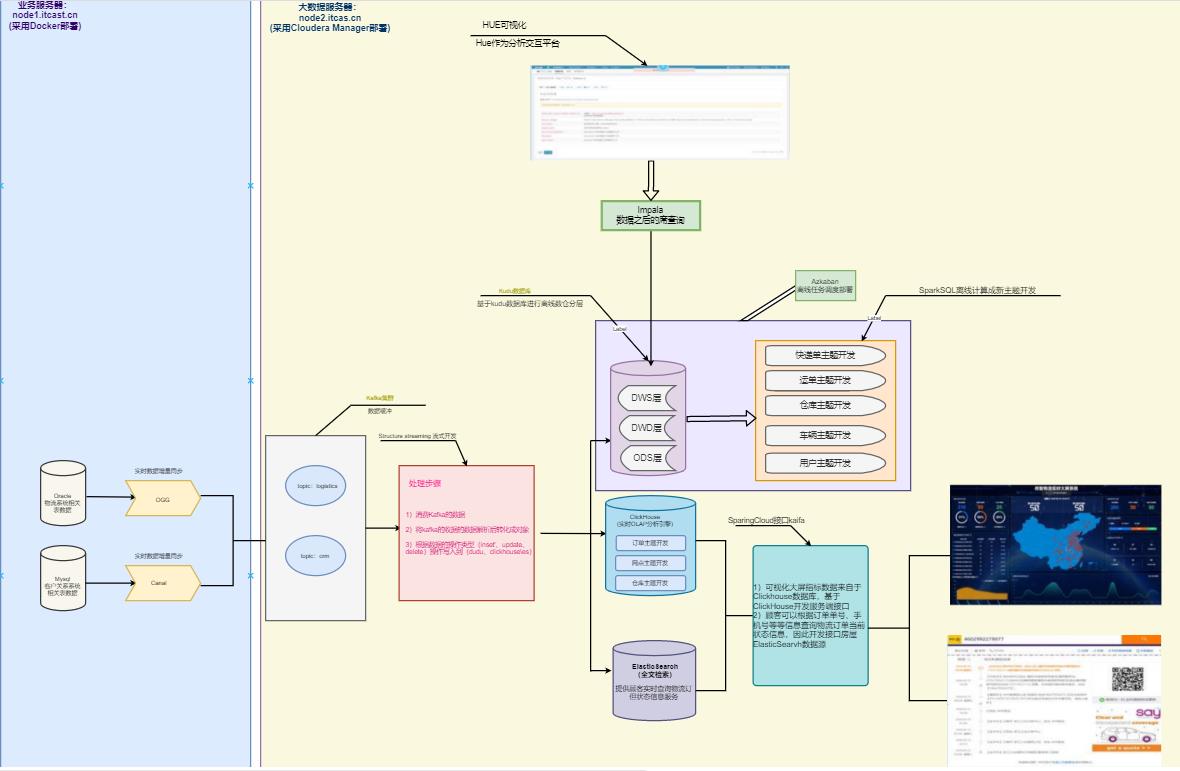
从数据源开始,业务数据主要存放到Oracle和MySQL数据库中,我们使用OGG和Canal分别将Oracle和
MySQL的增量数据同步到Kafka集群,然后通过StructuredStreaming程序进行实时ETL处理,将处理的
结果写入到Kudu数据库中,供应用平台进行离线分析处理;为了将一些要求监控的业务实时展示,
StructuredStreaming流处理会将数据写入到ClickHouse,Java Web后端直接将数据查询出来进行实时的数据展示;为了方便业务部门对各类单据的查询,StructuredStreaming流式处理系统同时也将数据经过JOIN处理后,将数据写入到ElasticSearch中,然后基于Spring Cloud开发能够支撑高并发访问的数据服务,方便运营人员、客户的查询;
四、项目的技术选型
4.1流式处理平台
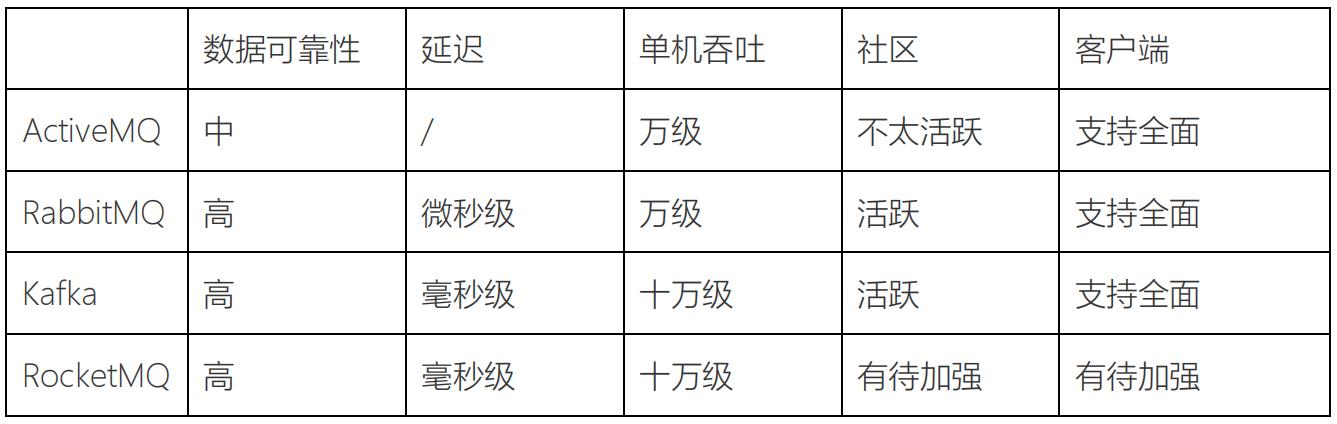
采用Kafka作为消息传输中间介质
Kafka对比其他MQ的优点
可扩展 Kafka集群可以透明的扩展,增加新的服务器进集群。
高性能 Kafka性能远超过传统的ActiveMQ、RabbitMQ等,Kafka支持Batch操作。
容错性 Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将
通知生产者和消费者从而使用其他的Broker。
Kafka对比其他MQ的缺点
重复消息 Kafka保证每条消息至少送达一次,虽然几率很小,但一条消息可能被送达多次。
消息乱序 Kafka某一个固定的Partition内部的消息是保证有序的,如果一个Topic有多个
Partition,partition之间的消息送达不保证有序。
复杂性 Kafka需要Zookeeper的支持,Topic一般需要人工创建,部署和维护比一般MQ成
本更高。
Kafka对比其他MQ的使用场景
Kafka 主要用于处理活跃的流式数据,大数据量的数据处理上
其他MQ 用在对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量还在其次,
更适合于企业级的开发
总结
4.2 分布式计算平台
分布式计算采用Spark生态
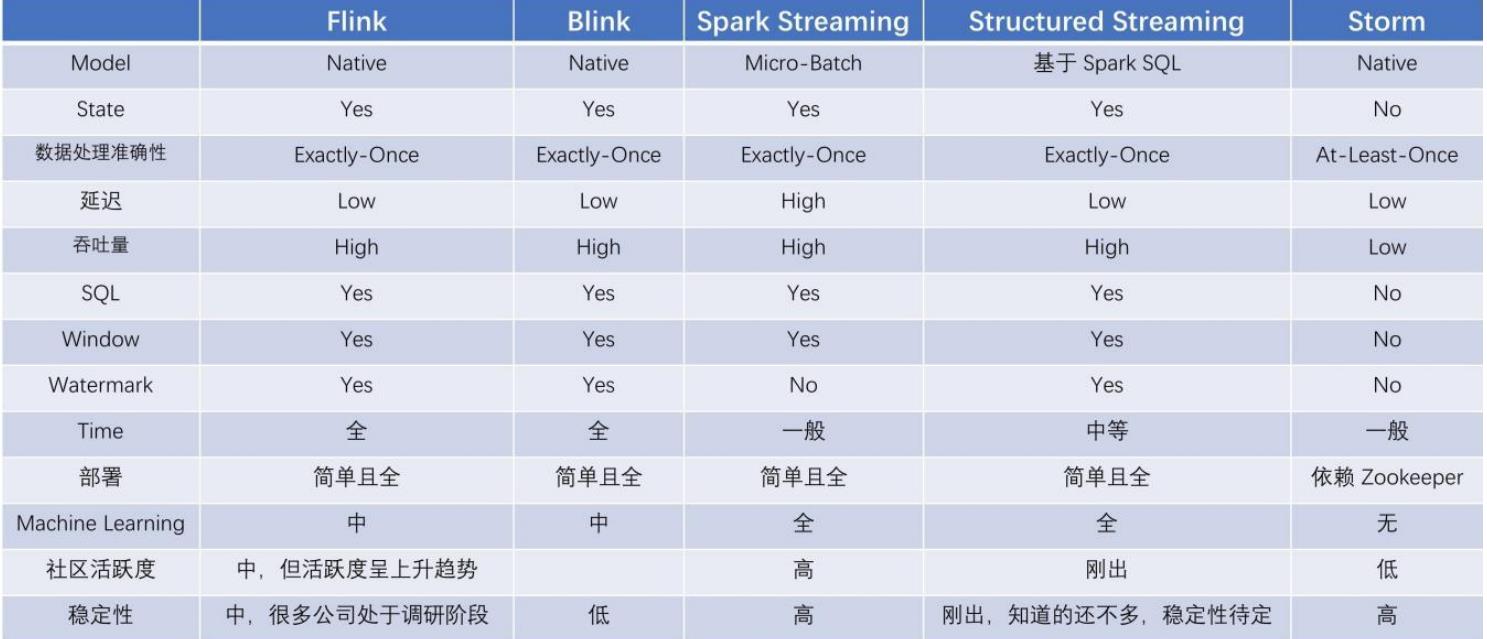
如果对延迟要求不高的情况下,可以使用 Spark Streaming,它拥有丰富的高级 API,使用
简单,并且 Spark 生态也比较成熟,吞吐量大,部署简单,社区活跃度较高,从 GitHub 的
star 数量也可以看得出来现在公司用 Spark 还是居多的,并且在新版本还引入了
Structured Streaming,这也会让 Spark 的体系更加完善。
如果对延迟性要求非常高的话,可以使用当下最火的流处理框架 Flink,采用原生的流处理系
统,保证了低延迟性,在 API 和容错性方面做的也比较完善,使用和部署相对来说也是比较
简单的,加上国内阿里贡献的 Blink,相信接下来 Flink 的功能将会更加完善,发展也会更加
好,社区问题的响应速度也是非常快的,另外还有专门的钉钉大群和中文列表供大家提问,
每周还会有专家进行直播讲解和答疑。
结论:本项目使用Structured Streaming开发实时部分,同时离线计算使用到SparkSQL,而Spark的生
态相对于Flink更加成熟,因此采用Spark开发
4.3 海量数据存储
ETL后的数据存储到Kudu中,供实时、准实时查询、分析
Kudu是一个与HBase类似的列式存储分布式数据库,官方给Kudu的定位是:在更新更及时的
基础上实现更快的数据分析
Kudu对比其他列式存储(HBase、HDFS)
HDFS 使用列式存储格式Apache Parquet,Apache ORC,适合离线分析,不支持单条纪录
级别的update操作,随机读写性能差
HBASE 可以进行高效随机读写,却并不适用于基于SQL的数据分析方向,大批量数据获取时
的性能较差。
KUDU KUDU较好的解决了HDFS与HBASE的这些缺点,它不及HDFS批处理快,也不及HBase
随机读写能力强,但是反过来它比HBase批处理快(适用于OLAP的分析场景),而
且比HDFS随机读写能力强(适用于实时写入或者更新的场景),这就是它能解决的
问题。
Elastic Search作为单据数据的存储介质,供顾客查询订单信息
Elasticsearch的使用场景
记录和日志分析 围绕Elasticsearch构建的生态系统使其成为最容易实施和扩展日志记录
解决方案之一,利用这一点来将日志记录添加到他们的主要用例中,或
者将我们纯粹用于日志记录。
采集和组合公共数据 Elasticsearch可以灵活地接收多个不同的数据源,并能使得这些数据可
以管理和搜索
全文搜索 非常强大的全文检索功能,方便顾客查询订单相关的数据
事件数据和指标 Elasticsearch还可以很好地处理时间序列数据,如指标(metrics )和应
用程序事件
数据可视化 凭借大量的图表选项,地理数据的平铺服务和时间序列数据的
TimeLion,Kibana是一款功能强大且易于使用的可视化工具。对于上面
的每个用例,Kibana都会处理一些可视化组件。
ClickHouse作为实时数据的指标计算存储数据库
ClickHouse与其他的OLAP框架的比较
直接查询,ClickHouse支持类SQL语
言,提供了传统关系型数据的便利
框架软件版本


以上是关于大数据实时+离线项目架构----智慧物流大数据平台(超流行框架!)的主要内容,如果未能解决你的问题,请参考以下文章