kafka源码分析 生产消息过程
Posted 顧棟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka源码分析 生产消息过程相关的知识,希望对你有一定的参考价值。
kafka 生产消息分析
生产消息的实例代码
package com.example.demo.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.Future;
public class ProducerAnalysis {
public static Properties initConfig() {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, CommonHelper.BROKER_LIST);
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "demo-producer-client-1");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(CommonHelper.TOPIC, "Hello Kafka!");
try {
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get();
System.out.println("topic=" + metadata.topic()
+ ", partition=" + metadata.partition()
+ ", offset=" + metadata.offset());
} catch (Exception e) {
e.printStackTrace();
}
}
}
过程步骤
- 配置生产的客户端的参数以及创建对应的生产者实例
- 构建待发送的消息
- 发送消息
- 关闭生产者实例
参数说明
-
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG:对应的参数其实就是bootstrap.servers,用于建立到Kafka集群的初始连接的主机/端口对列表。客户端将使用所有服务器,而不管这里为引导指定了哪些服务器;此列表只影响用于发现完整服务器集的初始主机。这个列表的格式应该是host1:port1,host2:port2,…。由于这些服务器仅用于初始连接,以发现完整的集群成员(可能会动态更改),因此该列表不需要包含完整的服务器集(但是,在服务器关闭的情况下,您可能需要多个服务器)。 -
ProducerConfig.CLIENT_ID_CONFIG:对应的参数是client.id,当发出请求时传递给服务器的id字符串。这样做的目的是允许在服务器端请求日志中包含逻辑应用程序名,从而能够跟踪请求的来源,而不仅仅是ip/port。 -
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG:key.serializer,关键字的序列化器类,实现了org.apache.kafka.common.serialization.Serializerinterface. -
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG:value.serializer,Serializer类的值实现了org.apache.kafka.common.serialization.Serializerinterface.Note 在创建生产者的时候使用了
ProducerConfig类,在这个类中,是用了static{}块,来初始化一些默认配置。还有一些其他的关于生产者的配置可以在ProducerConfig类中观察到。
创建生产者实例主流程
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null, null, null);
}
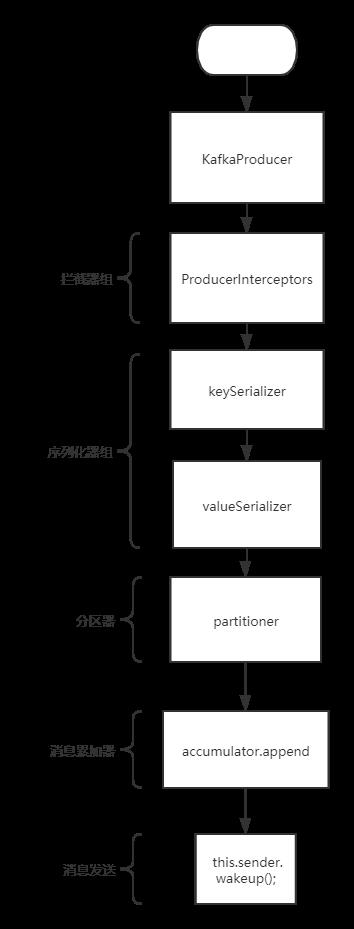
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
Metadata metadata,
KafkaClient kafkaClient) {
try {
// 获取用户提供的配置
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = Time.SYSTEM;
// 获取客户端点的id,如果没有就默认提供一个采用producer-累加
String clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
if (clientId.length() <= 0)
clientId = "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement();
this.clientId = clientId;
// 检查中配置中是否含有事务,构建相应的上下文
String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG) ?
(String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG) : null;
LogContext logContext;
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
// 开始启动生产者
// 为这个生产者配置指标采集
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class);
reporters.add(new JmxReporter(JMX_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
// 找到分区器 -默认分区器DefaultPartitioner
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
// 获取在尝试重试对给定主题分区的失败请求之前等待的时间。这避免了在某些失败场景下在紧密循环中重复发送请求
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
// 获取key和value序列化器
if (keySerializer == null) {
this.keySerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = ensureExtended(keySerializer);
}
if (valueSerializer == null) {
this.valueSerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = ensureExtended(valueSerializer);
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
// 获取拦截器
List<ProducerInterceptor<K, V>> interceptorList = (List) (new ProducerConfig(userProvidedConfigs, false)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
this.interceptors = new ProducerInterceptors<>(interceptorList);
// 配置集群资源监听器
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer, valueSerializer, interceptorList, reporters);
// 请求的最大字节数。此设置将限制制作人在单个请求中发送的记录批数,以避免发送大型请求。
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 生产者可以用来缓冲等待发送到服务器的记录的总内存字节大小
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 压缩类型
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
// 配置控制了KafkaProducer.send()和KafkaProducer.partitionsFor()会阻塞多长时间。这些方法可能会被阻塞,要么是因为缓冲区已满,要么是因为元数据不可用。用户提供的序列化器或分区器中的阻塞不会计入此超时。
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
this.requestTimeoutMs = config.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
// 配置事务管理器
this.transactionManager = configureTransactionState(config, logContext, log);
// 请求重试
int retries = configureRetries(config, transactionManager != null, log);
// 最大进行中的请求数
int maxInflightRequests = configureInflightRequests(config, transactionManager != null);
short acks = configureAcks(config, transactionManager != null, log);
// 维护api的版本给networkClient之外进行访问
this.apiVersions = new ApiVersions();
// 记录累加器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time,
apiVersions,
transactionManager);
// 验证转换配置中的服务地址
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
if (metadata != null) {
this.metadata = metadata;
} else {
// 构造元数据信息,并从服务地址进行元数据更新
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
true, true, clusterResourceListeners);
this.metadata.update(Cluster.bootstrap(addresses), Collections.<String>emptySet(), time.milliseconds());
}
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
// 构建基于nio.channels.Selector的网络客户端封装的kafkaClient
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
this.metadata,
clientId,
maxInflightRequests,
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs,
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
// 构建处理向 Kafka 集群发送生产请求的后台线程实例。线程名 kafka-producer-network-thread|Client号
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
this.errors = this.metrics.sensor("errors");
config.logUnused();
// 注册指标信息,同时会获取client版本信息和commit信息
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics);
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(0, TimeUnit.MILLISECONDS, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
sender的run流程
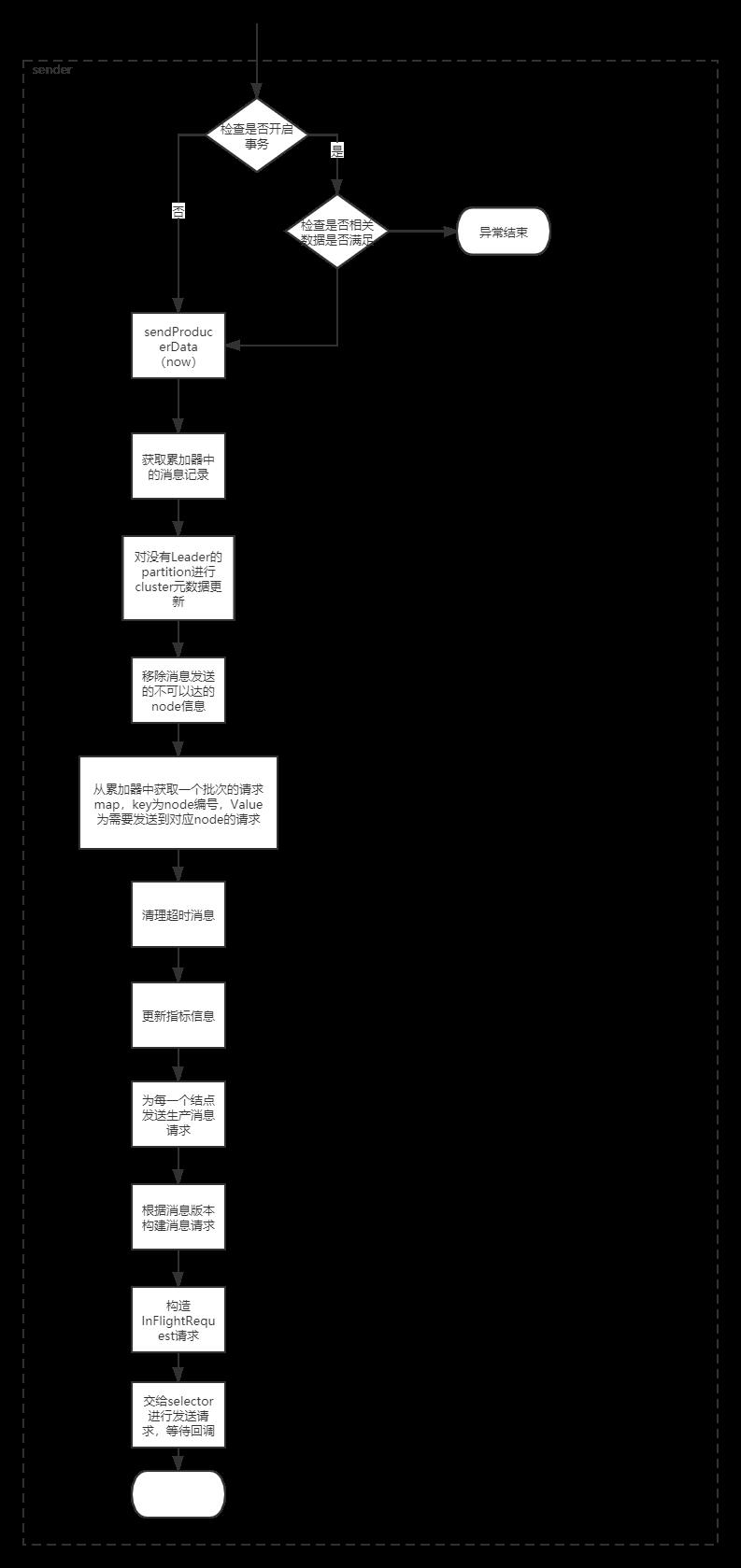
void run(long now) {
// 若开启事务管理器
if (transactionManager != null) {
try {
// 检查是否有任何带有未解析分区的分区,这些分区现在可以解析。 如果生产者 ID 需要重置,则返回 true,否则返回 false。
if (transactionManager.shouldResetProducerStateAfterResolvingSequences())
// Check if the previous run expired batches which requires a reset of the producer state.
transactionManager.resetProducerId();
if (!transactionManager.isTransactional()) {
// this is an idempotent producer, so make sure we have a producer id
// 这是一个幂等的生产者,所以请确保我们有一个生产者 ID
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(new KafkaException("The client hasn't received acknowledgment for " +
"some previously sent messages and can no longer retry them. It isn't safe to continue."));
} else if (transactionManager.hasInFlightTransactionalRequest() || maybeSendTransactionalRequest(now)) {
// as long as there are outstanding transactional requests, we simply wait for them to return
client.poll(retryBackoffMs, now);
return;
}
// do not continue sending if the transaction manager is in a failed state or if there
// is no producer id (for the idempotent case).
// 如果事务管理器处于失败状态或没有生产者 ID(对于幂等情况),则不要继续发送。
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, now);
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request: {}", e);
transactionManager.authenticationFailed(e);
}
}
long pollTimeout = sendProducerData(now);
client.poll(pollTimeout, now);
}
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
以上是关于kafka源码分析 生产消息过程的主要内容,如果未能解决你的问题,请参考以下文章