24 基于mmap内存映射实现磁盘文件的高性能读写
Posted 鮀城小帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了24 基于mmap内存映射实现磁盘文件的高性能读写相关的知识,希望对你有一定的参考价值。
1.Broker读写磁盘文件的核心技术
Broker对磁盘文件的写入主要是借助直接写入os cache来实现性能优化的,因为直接写入os cache,相当于就是写入内存一样的性能,后续等os内核中的线程异步把cache中的数据刷入磁盘文件即可。
而这一个过程涉及到了mmap技术。
2.传统文件IO操作的多次数据拷贝问题
多次数据拷贝
如果没有使用mmap技术,RocketMQ就需要使用普通文件IO操作去进行磁盘文件的读写,这一过程涉及到 多次数据拷贝的问题。
读数据
场景:有一个程序需要对磁盘文件发起IO操作读取里面的数据到自己这儿来,会经过以下的顺序:
首先从磁盘上把数据读取到内核IO缓冲区里去,然后再从内核IO缓冲区里读取到用户进程私有空间里去,然后我们才能拿到这个文件里的数据。
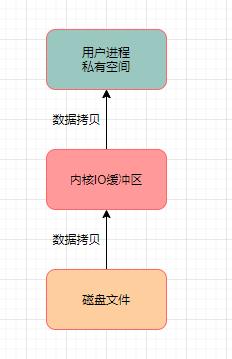
为了读取磁盘文件的数据,这里发生了两次数据拷贝。而这对磁盘读写性能必然造成影响。
写数据
写数据的过程,必须先把数据写入到用户进程私有空间里去,然后从这里再进入内核IO缓冲区,最后进入磁盘文件里去。
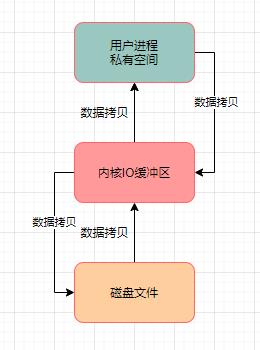
在数据进入磁盘文件的过程中,同样发生了两次数据拷贝。
3.基于mmap技术 + page cache技术优化
mmap技术
RocketMQ底层对CommitLog、ConsumeQueue之类的磁盘文件的读写操作,基本上都会采用mmap技术来实现。
代码层面,就是基于JDK NIO包下的MappedByteBuffer的map() 函数,来先将一个磁盘文件(比如一个CommitLog文件,或者是一个ConsumeQueue文件)映射到内存里来。
内存映射
所谓内存映射,刚开始建立映射的时候,并没有任何的数据拷贝操作,其实磁盘文件还是停留在那里。只不过是把物理上的磁盘文件的一些地址和用户进程私有空间的一些虚拟地址进行了一个映射。当然,最终是要把磁盘文件里的数据给读取到内存里来的。
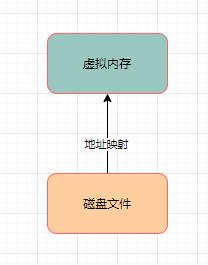
这个地址映射的过程,就是JDK NIO包下的MappedByteBuffer.map()函数干的事情,底层就是基于mmap技术实现的。
扩展: mmap技术在进行文件映射的时候,一般有大小限制,在1.5GB~2GB之间。所以RocketMQ才让CommitLog单个文件在1GB,ConsumeQueue文件在5.72MB,不会太大。
这样限制了RocketMQ底层文件的大小,就可以在进行文件读写的时候,很方便的进行内存映射了。
Page Cache技术
PageCache,实际上就是对应与虚拟内存的。
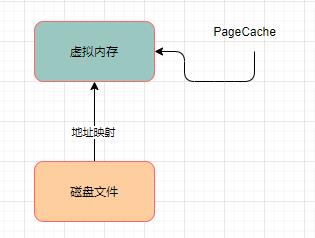
4.基于mmap技术+pagecache技术实现高性能的文件读写
在进行mmap映射之后,这个已经映射到内存里的磁盘文件就可以进行读写操作了,比如要写入消息到CommitLog文件,你先把一个CommitLog文件通过MappedByteBuffer的map()函数映射其地址到你的虚拟内存地址。
写操作
接着就可以对这个MappedByteBuffer执行写入操作了,写入的时候它会直接进入PageCache中,然后过一段时间之后,由os的线程异步刷入磁盘中。
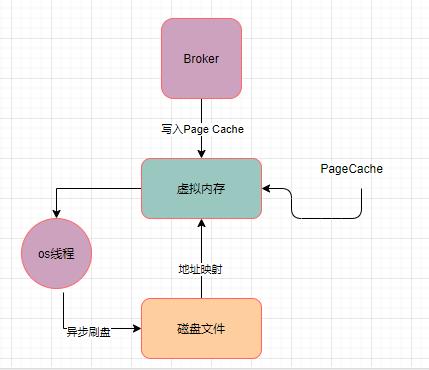
在上述的流程中,只有一次数据拷贝的过程,它就是从PageCache里拷贝到磁盘文件里而已。这个就是使用了mmap技术之后,相比较于传统磁盘IO的一个性能优化。
读操作
如果要从磁盘文件里读取数据,就会先判断一下,要读取的数据是否在PageCache里。如果有,就直接从PageCache里读取。
如果PageCache里没有你要的数据,那么此时就会从磁盘文件里加载数据到PageCache中去。
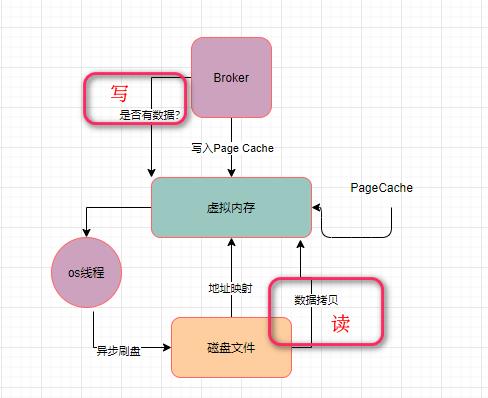
而且PageCache技术在加载数据的时候,还会将你加载的数据块的临近的其他数据块也一起加载到PageCache里去。
可以看出,在读取数据的时候,也是只发生了一次拷贝,而不是两次拷贝,所以这个性能相较于传统IO来说,肯定又是提高了。
5.预映射机制 + 文件预热机制
以下是Broker针对上述的磁盘文件高性能读写机制做的一些优化:
(1)内存预映射机制:Broker会针对磁盘上的各种CommitLog、ConsumeQueue文件预先分配好MappedFile,也就是提前对一些可能接下来要读写的磁盘文件,提前使用MappedByteBuffer执行map()函数完成映射,这样后续读写文件的时候,就可以直接执行了。
(2)文件预热:在提前对一些文件完成映射之后,因为映射不会直接将数据加载到内存里来,那么后续在读取尤其是CommitLog、ConsumeQueue的时候,其实有可能会频繁的从磁盘里加载数据到内存里去。
所以其实在执行完map()函数之后,会进行madvise系统调用,就是提前尽可能多的把磁盘文件加载到内存里去。
通过上述优化,才真正能实现一个效果,就是写磁盘文件的时候都是进入PageCache的,保证写入高性能;同时尽可能多的通过 map + madvise 的映射后预热机制,把磁盘文件里的数据尽可能多的加载到PageCache里来,后续对ConsumeQueue、CommitLog进行读取的时候,才能尽可能从内存里读取数据。
总结:mmap的读数据对比正常的从磁盘读取数据少一次从内核IO缓冲区拷贝到用户缓冲区的过程;首先数据从磁盘进行一次DMA拷贝数据到内核IO缓冲区中,内核IO缓冲区和用户缓冲区进行内存映射,从用户态切换为内核态进行映射拷贝,在从内核态切换到用户态进行内存映射减少一次拷贝还是两次切换,再从用户态切换到内存态进行CPU拷贝数据到socket缓存中,在进行DMA拷贝到网络引擎中最后切换为用户态,整个过程是3次拷贝4次切换,写数据即反过来。
思考: Java工程师真的只会Java就可以了吗?
答:不是的,作为Java开发,还需要懂测试、运维、架构、计算机底层原理、操作系统原理。
同时,最好还要有一门辅助语言比如Python go之类的,还要去学习人工智能,同时前后端的流程需要弄清楚。
以上是关于24 基于mmap内存映射实现磁盘文件的高性能读写的主要内容,如果未能解决你的问题,请参考以下文章