用Java+Redis+ES+Kibana技术对数百万知乎用户进行了数据分析,得到了这些...
Posted 架构真经
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Java+Redis+ES+Kibana技术对数百万知乎用户进行了数据分析,得到了这些...相关的知识,希望对你有一定的参考价值。
http://tinyurl.com/quscxyl
1. 前言
我是一个真正的知乎小白。
上班的时候,自己手头的事情处理完了,我除了在掘金摸鱼,就是在知乎逛贴。在我的认知中,知乎是一个高质量论坛,基本上各种“疑难杂症”都能在上面找到相应的专业性回答。但平时逗留在知乎的时间过多,我不知道自己是被知乎上面的精彩故事所吸引,还是为知乎上面的高深技术而着迷。
咱是理科生,不太懂过于高深的哲学,自然不会深层次地剖析自己,只能用数据来说话。于是,就有了这篇博客。
相关的项目源码放在:
https://github.com/zhenye163/spider-zhihu
2. 博客结构图
博客的结构图如上所示。这篇博客主要讲述两件事:爬取知乎用户数据和对用户数据进行分析。这个结构图基本能够概述分析知乎用户信息的思路,具体的思路详述和技术实现细节可看博客后面的内容。
3. 爬取知乎用户数据
3.1 知乎用户页面解析
我的知乎主页信息预览如下:
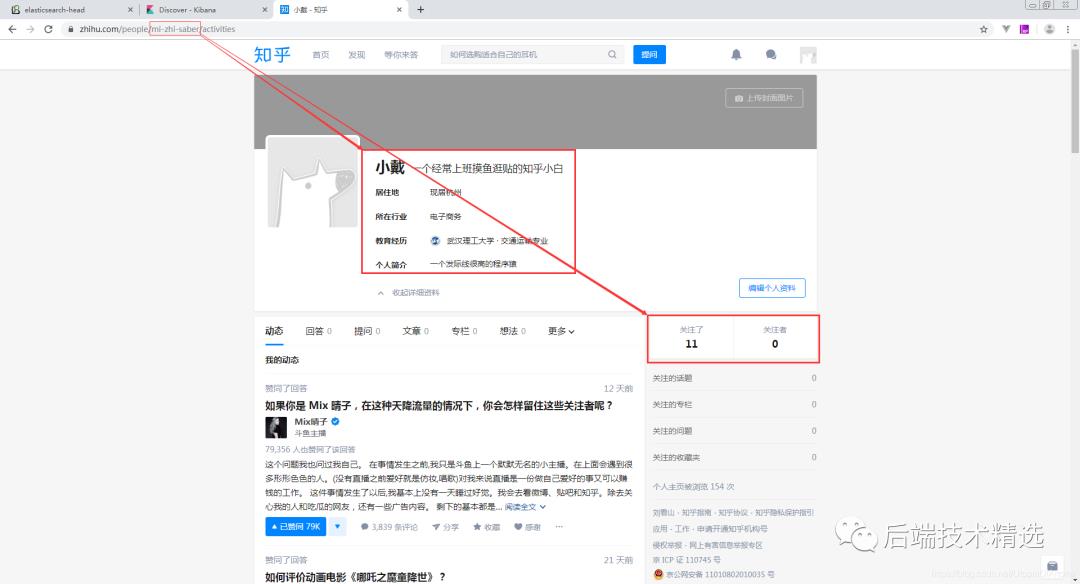
从该页面的内容来看,我当前需要爬取的知乎信息就在两个红框中。然后每个知乎用户主页对应的URL路径应该不一样,这里URL中标识是我的主页就是mi-zhi-saber,这个URL标识就是知乎里面的url_token。也就是说拿到足够多的url_token,就可以自己组装URL来获取用户的信息。
通过分析知乎页面结构,我们可以按照如下思路来爬取用户信息:
-
基于用户的个人主页信息,爬取、解析并保存用户信息。
上面用户主页链接对应的页面内容如下:
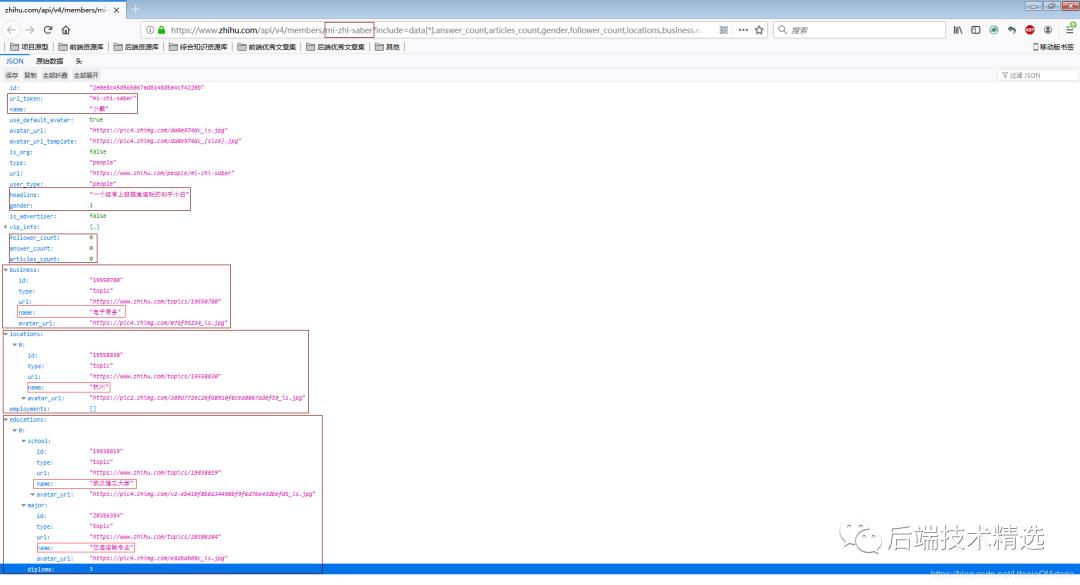
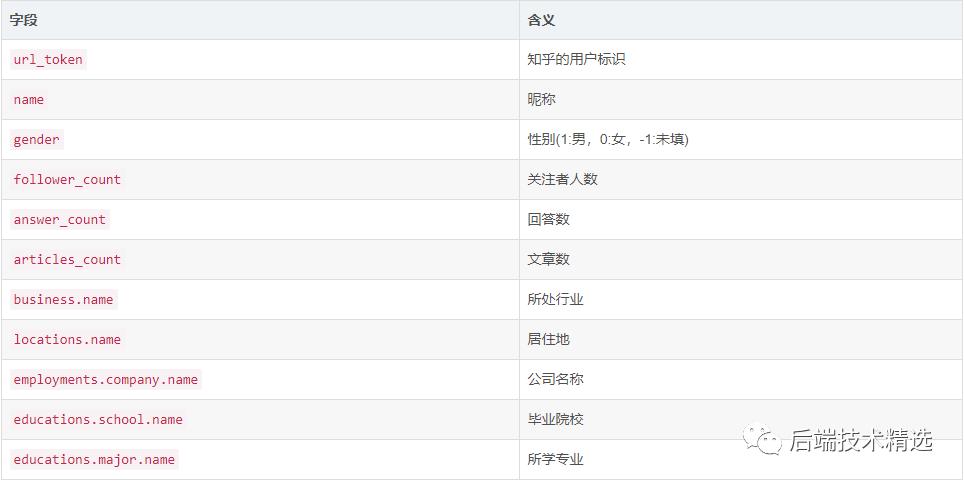
对比这两个页面,可以推断出里面部分字段的意义(其实字段名称已经足够见名知意了)。综合考虑后,我要爬取的字段及其意义如下
-
基于用户关注的知乎用户信息,爬取、解析并保存用户信息。
我关注的知乎用户信息页面内容如下:
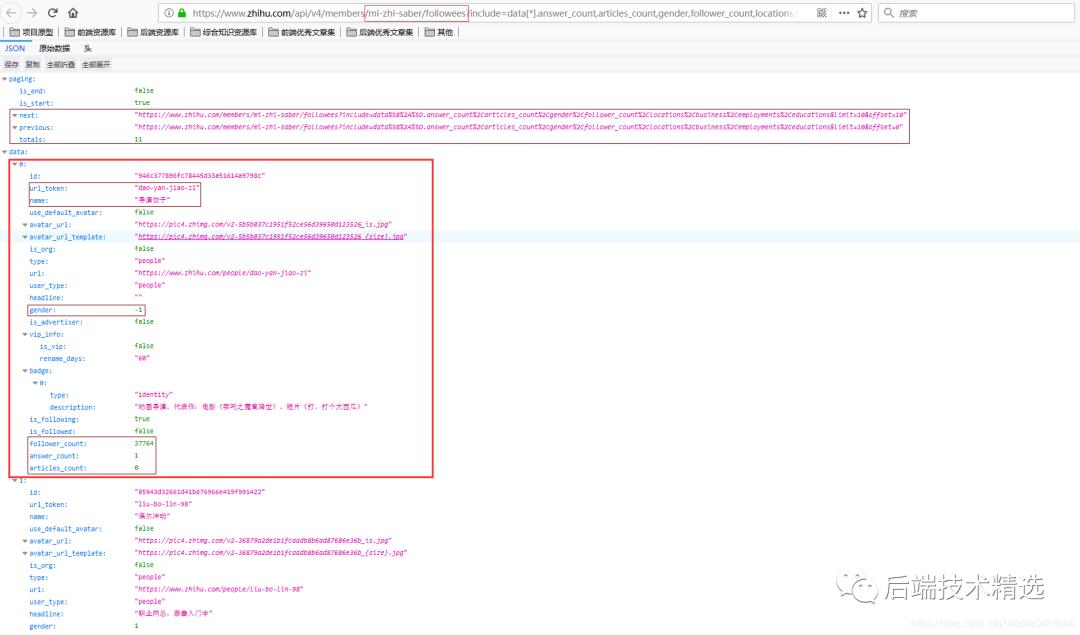
-
基于关注用户的知乎用户信息,爬取、解析并保存用户信息。

理论上,选取一个知乎大V作为根节点,迭代爬取关注者和被关注者的信息,可以拿到绝大部分的知乎用户信息。
3.2 选取爬虫框架
要想对知乎用户进行画像,必须拿到足够多的知乎用户数据。简单来说,就是说要用java爬虫爬取足够多的知乎用户数据。
工欲善其事,必先利其器。常见的Java爬虫框架有很多如:webmagic,crawler4j,SeimiCrawler,jsoup等等。这里选用的是SpringBoot + SeimiCrawler,这个方式可以几乎零配置地使用爬虫爬取知乎用户数据。具体如何使用可见于SeimiCrawler官方文档,或者参考我的源码。
3.3 使用反反爬手段
论坛是靠内容存活的。如果有另外一个盗版论坛大量地爬取知乎内容,然后拷贝到自己的论坛上,知乎肯定会流失大量用户。不用想就知道,知乎肯定是采取了一些反爬手段的。
然后,所谓的“反反爬手段”,就是应对上面所说的反爬手段的。我采取的“反反爬手段”是:
-
收集一些常用的UA,然后每次调用接口访问知乎网站的时候会刷新所使用的UA。 -
自己在项目中维护一个可高用的免费代理池,每次调用接口访问知乎网站的时候会使用高可用代理池的随机一个代理。
实际实践过程中,提供了免费代理的网站有:西刺代理、89免费代理、云代理等等,但实际能够使用的还是只有西刺代理。而且西刺代理的可用数也非常少,导致代理池中可用代理数很少,使用代理池的效果不是很好,这真的是一件很沮丧的事。
免费代理池的架构及其实现思路图:
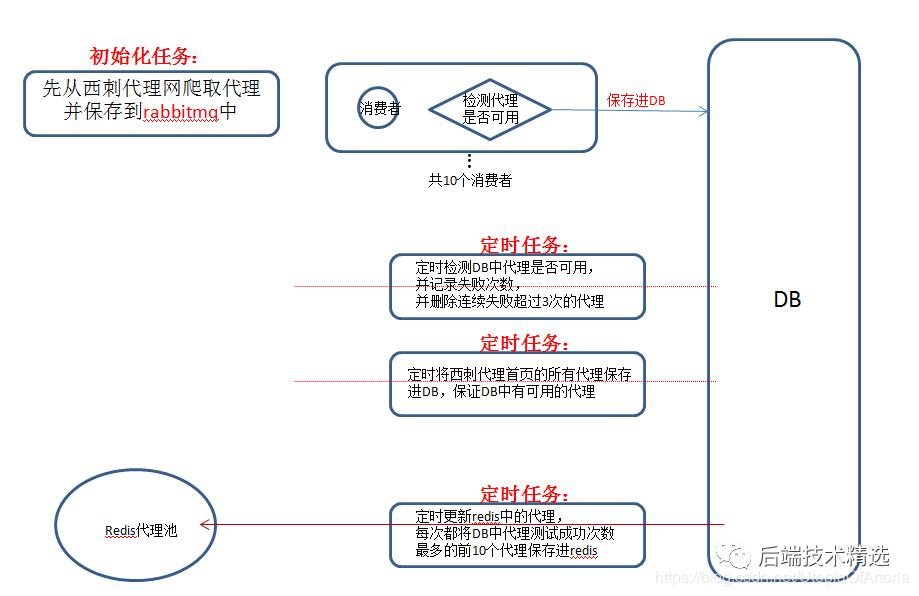
简述一下思路:
-
启动项目时,会自动去爬取西刺代理网站前10页的代理(共1000个代理),并将其保存到RabbitMQ中。RabbitMQ设置有10个消费者,每个消费者会检测代理是否可用,检测完毕后会将该代理的信息及其检测结果保存到DB中。 -
系统设置了一个定时任务,会定时将DB中当前的所有代理再次放到RabbitMQ中,会由10个消费者检测代理是否可用,并将检测结果同时更新到DB中。如果连续3次测试代理不可用,则将该代理从DB中删除。 -
系统设置了一个定时任务,会定时爬取西刺代理网首页的所有代理,会检测代理的可用性,并将其信息及检测结果再次保存到DB中。这样保证DB中会定时获取更多的代理(实际原因是西刺代理可用代理太少,如果不定时获取更多代理,DB中很快就没有可用的代理了)。 -
系统设置了一个定时任务,会自动删除redis中所有的代理。然后再将DB中的代理按检测成功次数进行排序,将连续成功次数最多的前10个代理保存进redis中。这样redis中的代理就是高可用的。
3.4 调用接口爬取数据
项目一定程度地屏蔽了代理池以及知乎用户数据解析的实现复习性,以暴露接口的方式提供爬取知乎用户信息的功能。
在配置好Redis/RabbitMQ环境后,成功启动项目,等项目稳定后(需要等到redis中有高可用的代理,否则就是用本机IP直接进行数据爬取,这样的话本机IP很容易会被封)后,即可通过调用如下接口的方式爬取知乎用户信息。
-
调用接口localhost:8980/users爬取指定知乎用户的信息,修改url_token的值即可爬取不同知乎用户的信息。
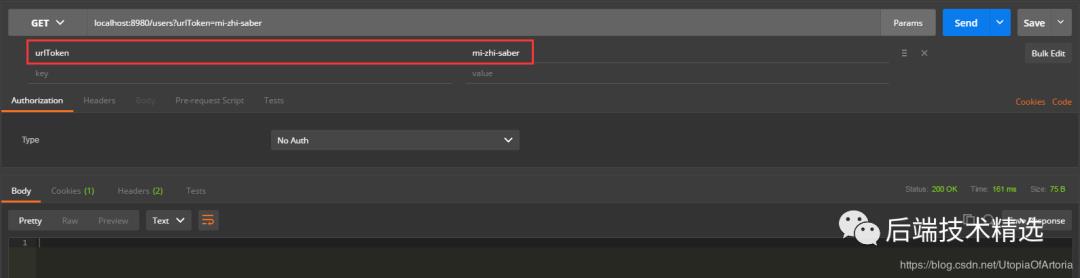
-
调用接口localhost:8980/users/followees爬取关注指定知乎用户的用户信息,修改url_token的值即可爬取关注不同知乎用户的用户信息。
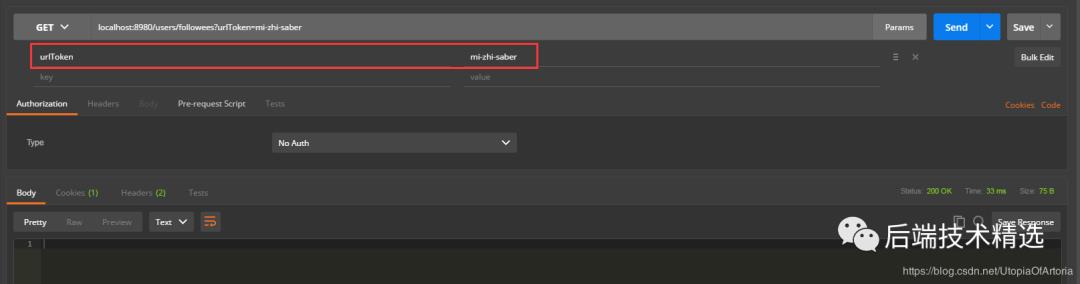
-
调用接口localhost:8980/users/followers爬取指定知乎用户关注的用户信息,修改url_token的值即可爬取不同知乎用户关注的用户信息。
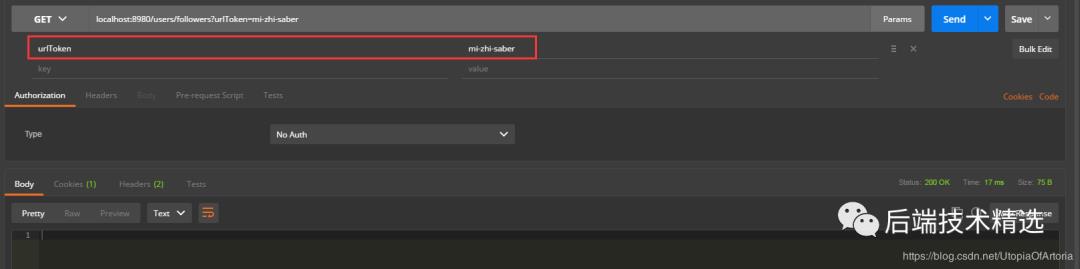
在实际测试爬取知乎网站用户信息的过程中,如果系统只用一个固定IP进行爬取数据,基本爬取不到10万数据该IP就会被封。使用了代理池这种方式后,由于西刺代理网址上可用的免费代理太少了,最终爬取到167万左右数据后,代理池中基本就没有可用的IP了。不过爬取到这么多的数据已经够用了。
4. 分析知乎用户数据
4.1 数据去重
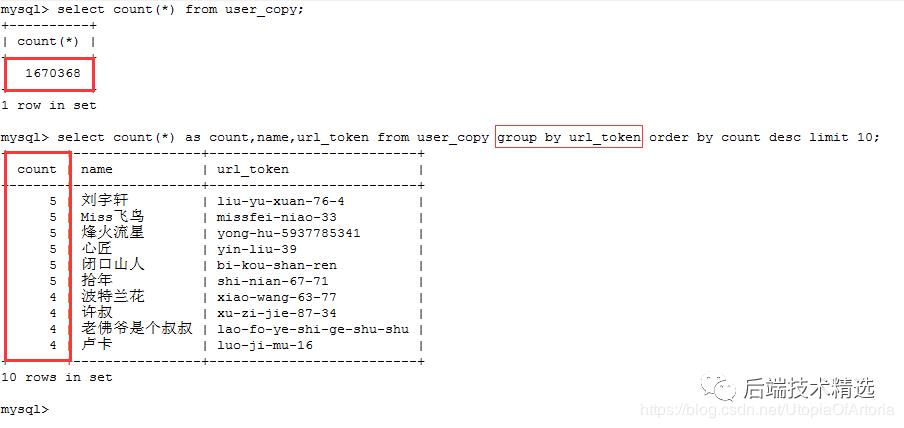
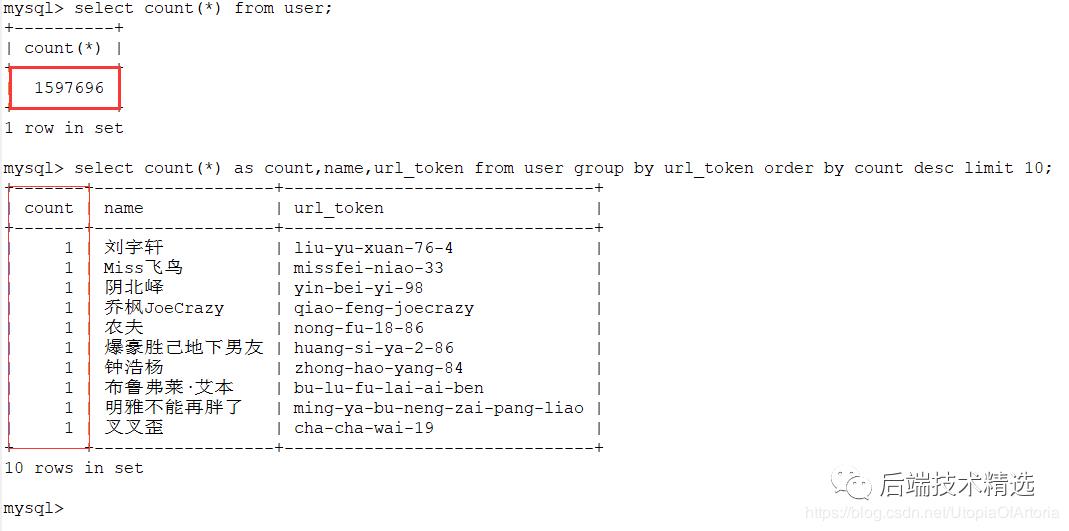
爬取了167万+知乎用户数据后,需要对原始数据进行简单的清理,这里就是去重。每个知乎用户有唯一的url_token,由于这里爬取的是用户的关注者与被关注者,很容易就会有重复的数据。
数据量有167万+,使用Java自带的去重容器Set/Map明显不合适(内存不够,就算内存足够,去重的效率也有待考量)。
项目中实现了一个简单的布隆算法,能够保证过滤后的知乎用户数据绝对没有重复。
布隆算法的实现思路图如下:
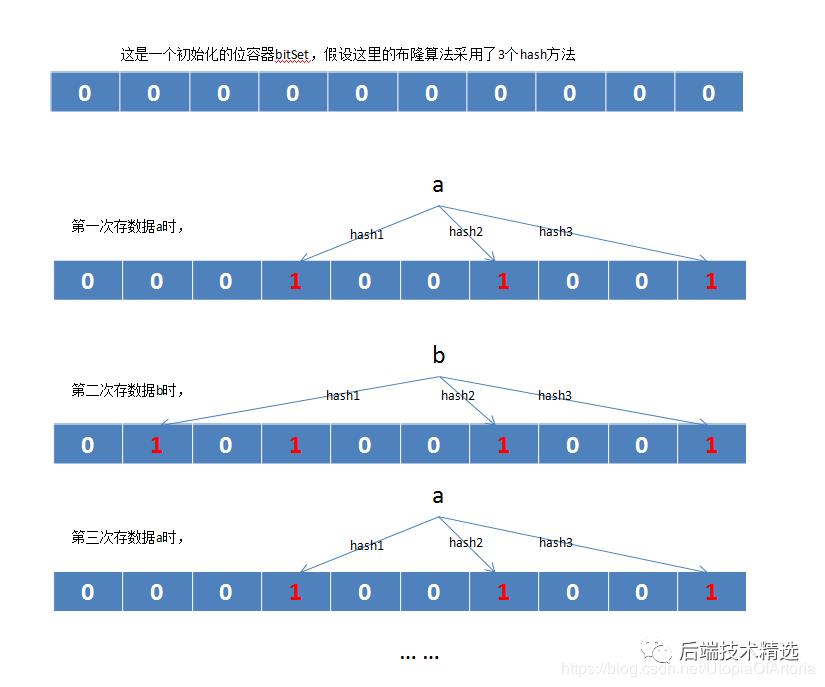
简述布隆算法的实现思路如下:
-
始化一个位容器(每个容器单位的值只能是0或1),并先规定好要使用映射数据用的n个hash方法,hash方法的结果对应于该位容器的一个下标。 -
数据之前,需要先判断该容器中是否已经存过该数据。该数据对应所有hash方法的结果,对应在位容器中的下标只要有一个下标对应的单位的值为0,则表示该容器还没有存过该数据,否则就判定为该容器之前存过该数据。 -
数据之后,需要将该数据所有hash方法结果对应于位容器中的下标的值,都置为1。
这里需要说明一下为什么要使用布隆算法以及布隆算法还有什么缺点。
使用布隆算法的理由:我们是依靠url_token来判断一个用户是否重复的,但url_token的长度是不确定的,这里存放一个url_token所需要的空间按上图DB中来看基本上有10字节以上。如果使用java容器进行去重,那么该容器至少需要的空间:10 * 1670000 byte 即大约15.93MB(这里貌似还是可以使用java容器进行去重,但其实这里还没有考虑容器中还需要存的其他信息)。
而使用布隆算法,需要的空间:n * 1670000 bit ,使用的hash方法一般是3-10个左右,即一般至多只需要15.9KB左右的空间(我在项目中使用的是2 << 24 bit即16KB的容量)。如果数据量继续增大,布隆算法的优势会越来越大。
算法的缺点: 地,这种hash映射存储的方式肯定会有误判的情况。即bitSet容器中明明没有存储该数据,却认为之前已经存储过该数据。但是只要hash方法的个数以及其实现设计得合理,那么这个误判率能够大大降低(笔者水平有限,具体怎么降低并计算误判率可自行谷歌或百度)。而且基于大数据分析来说,一定数据的缺失是可以允许的,只要保证过滤后有足够的不重复的数据进行分析就行。
项目中屏蔽了布隆算法实现的复杂性,直接调用接口localhost:8980/users/filter,即可将DB中的用户数据进行去重。
过滤之后,还有160万左右不重复的数据,说明布隆算法误判率导致的数据流失,对大量的数据来说影响是可以接受的。
4.2 数据导入ElasticSearch
mysql是一个用来持久化数据的工具,直接用来进行数据分析明显效果不太好(而且数据量较大时,查询效率极低),这里就需要使用更加合适的工具—ElasticSearch。简单学习一下ElasticSearch,可以参考elasticsearch官网。
配置好ElasticSearch环境,然后修改配置文件中ElasticSearch相关的配置。调用接口localhost:8980/users/transfer,即可将DB中的用户数据迁移到ES中。
SpringBoot整合ElasticSearch非常简单,直接在项目中导入ElasticSearch的自动配置依赖包
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
然后让相应的DAO层继承ElasticsearchRepository即可在项目中使用ElasticSearch。具体如何在springboot项目中使用ElasticSearch,可以参考SpringBoot-ElasticSearch官方文档,也可参考我项目中源码。
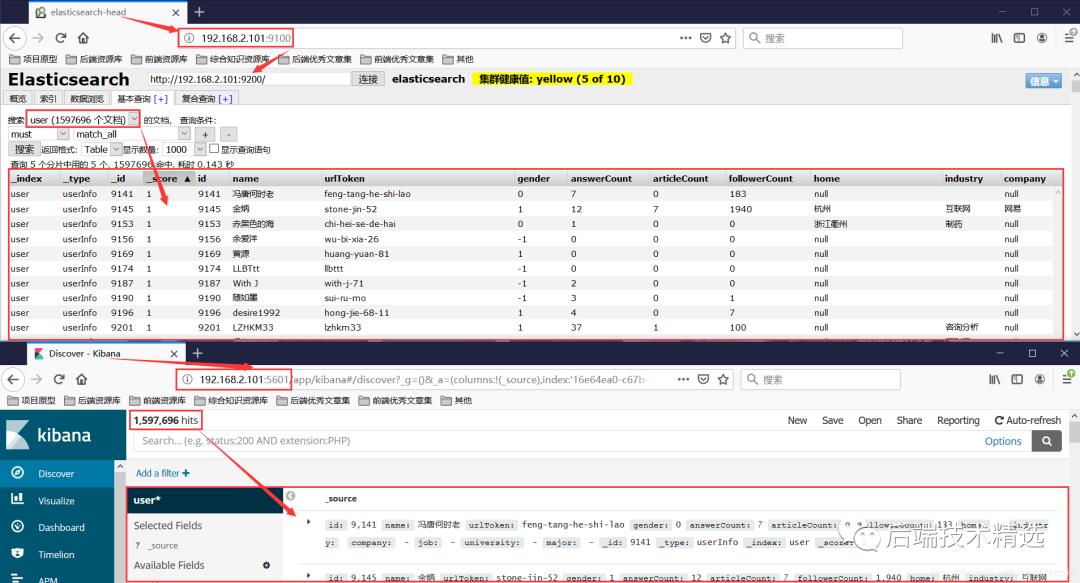
数据导入ES后,可以在head插件或者kibana插件中查看ES中的数据(head插件或kibana插件可以看去重之后导入ES中的数据有1597696条)。
4.3 kibana分析知乎数据
我们已经拿到足够多的用户数据了,现在需要利用kibana插件来分析数据。我们在Management > Kibana > Index Patterns中将创建关联的索引user后,即可使用kibana插件辅助我们来分析数据。
下面举几个例子来表示如何使用Kibana来分析大数据。
-
查询关注数在100万及以上的用户
# 查询关注数在100万及以上的用户
GET user/userInfo/_search
{
"query": {
"range" : {
"followerCount" : {
"gte": 1000000
}
}
}
}
查询结果图如下:
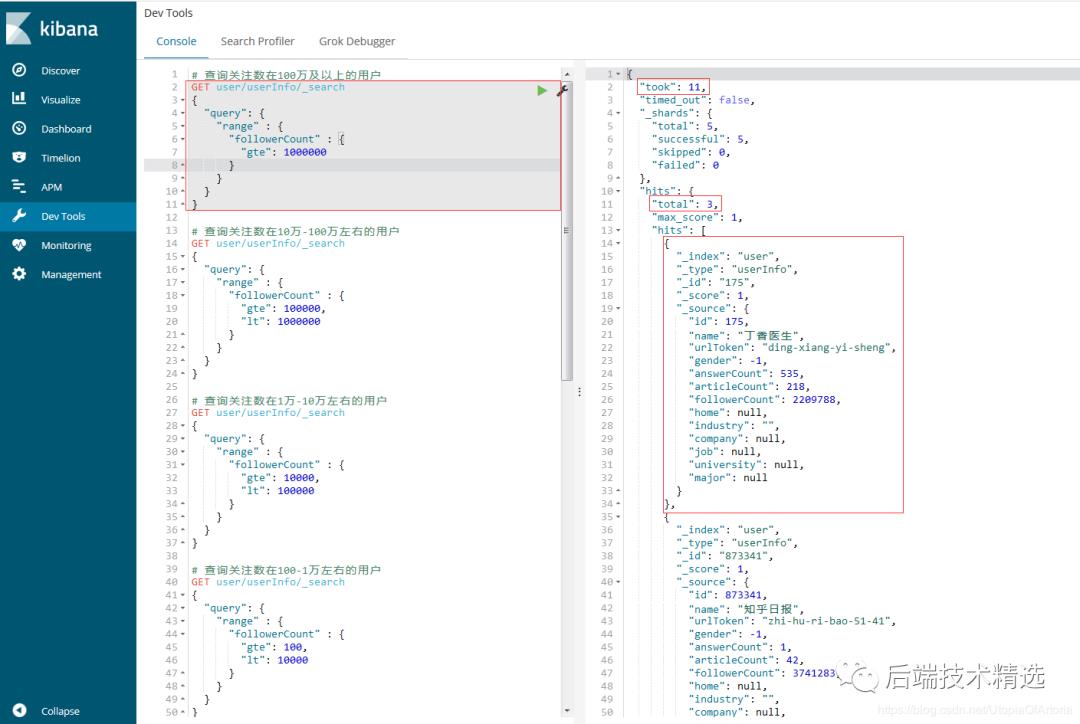
简单地解释一下结果集中部分字段的意义。took是指本次查询的耗时,单位是毫秒。hits.total表示的是符合条件的结果条数。hits._score表示的是与查询条件的相关度得分情况,默认降序排序。
-
聚合查询知乎用户的性别比
# 查询知乎用户男女性别比
GET /user/userInfo/_search
{
"size": 0,
"aggs": {
"messages": {
"terms": {
"field": "gender"
}
}
}
}
查询结果图如下:
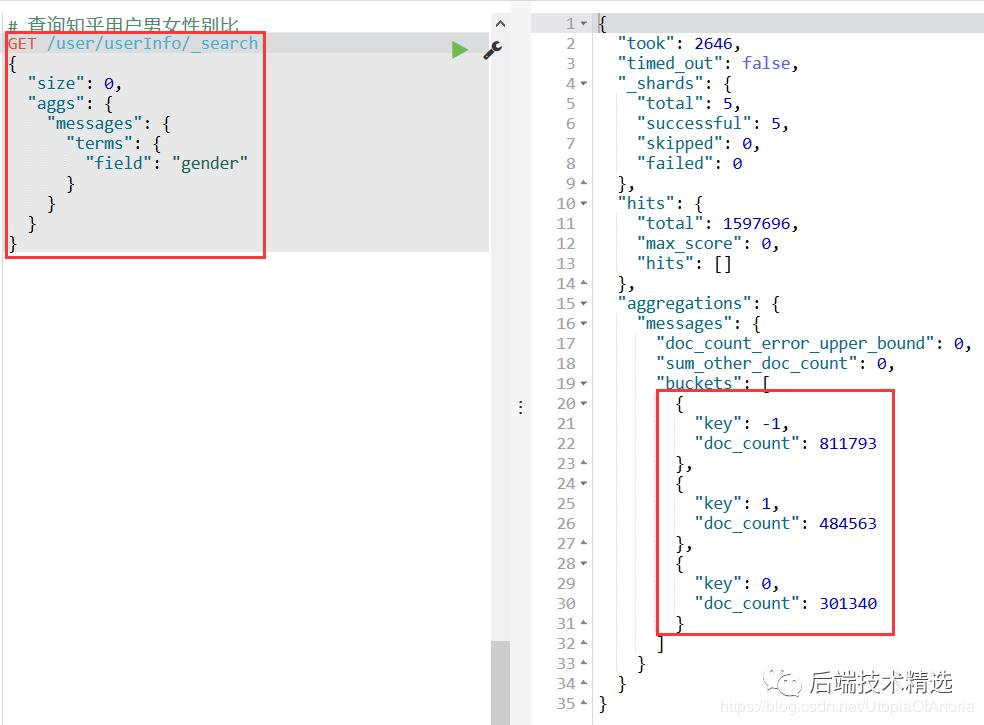
直接看数据可能不太直观,我们还可以直接通过kibana插件不画相应的结果图(-1:未填,1:男, 0:女):
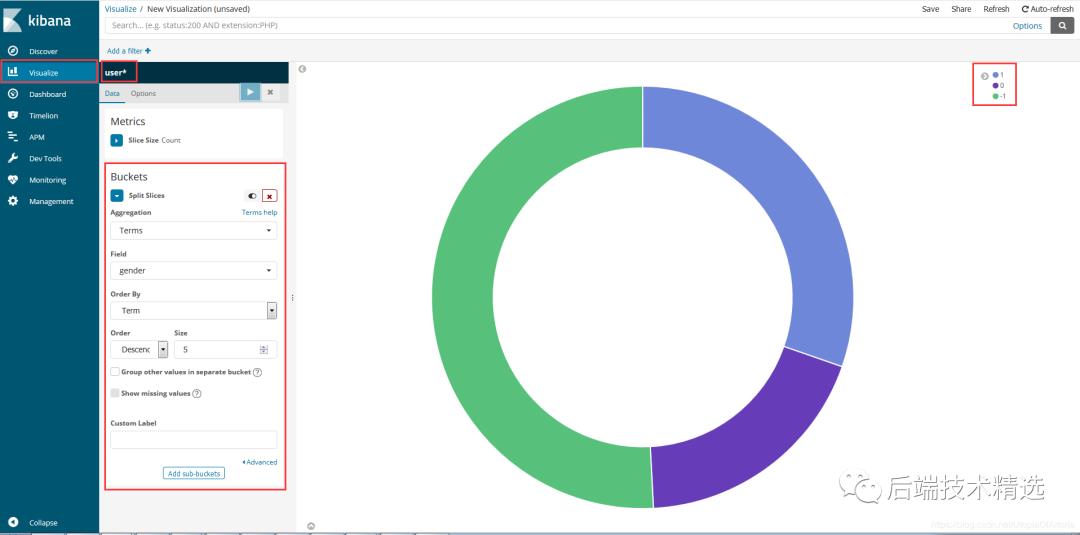
从结果图来看,目前知乎的男女比还不算离谱,比例接近3:2(这里让我有点儿怀疑自己爬取的数据有问题)。
-
聚合查询人口最集中的前10个城市
# 查询现居地最多的前10个城市
GET /user/userInfo/_search
{
"size": 0,
"aggs": {
"messages": {
"terms": {
"field": "home",
"size": 10
}
}
}
}
查询结果图如下:
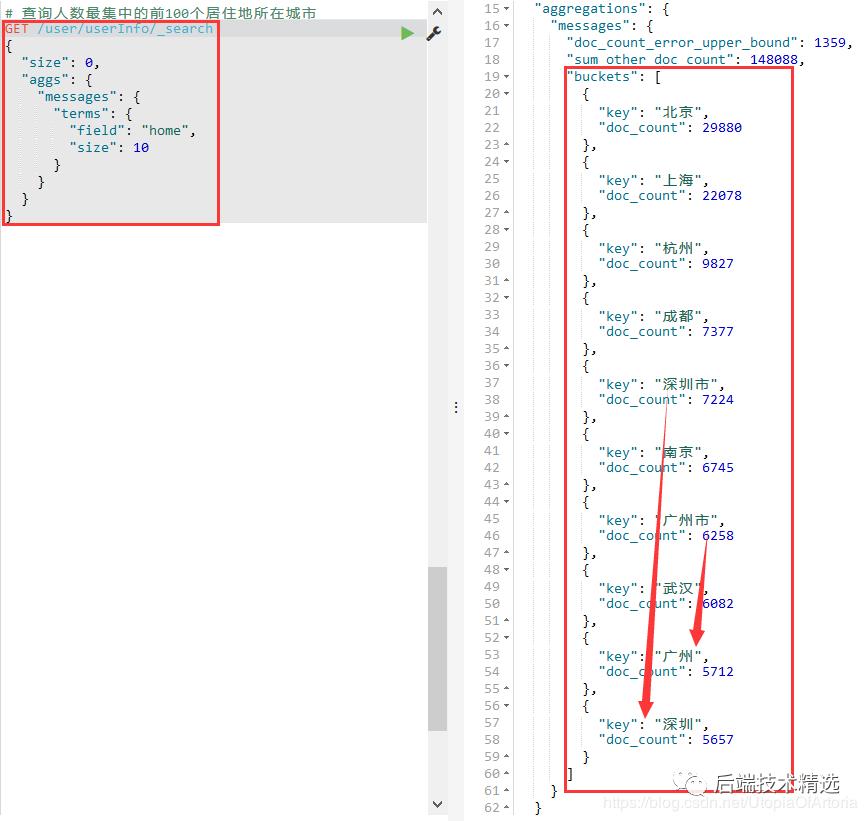
从这里的查询结果,很容易就可以看出,“深圳”和“深圳市”、“广州”和“广州市”其实各自指的都是同一地方。但是当前ES不能智能地识别并归类(ps: 可能有方法可以归类但笔者不会…)。因此这里需要后续手动地将类似信息进行处理归类。
-
模糊搜索
全字段匹配,“模糊”搜索含有“知乎”的数据,搜索结果图如下:
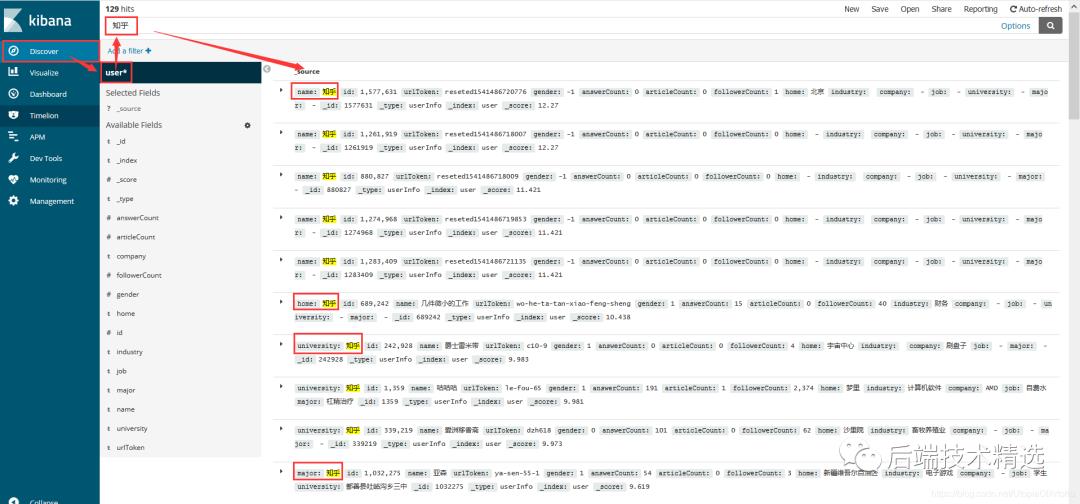
4.4 echarts作图
从上面的kibana画图效果来看,真的一般般。这里更推荐使用kibana收集数据,利用百度开源的数据可视化工具echarts来作图。
最终的数据汇总以及echarts绘图效果图如下:
-
关注数层级统计
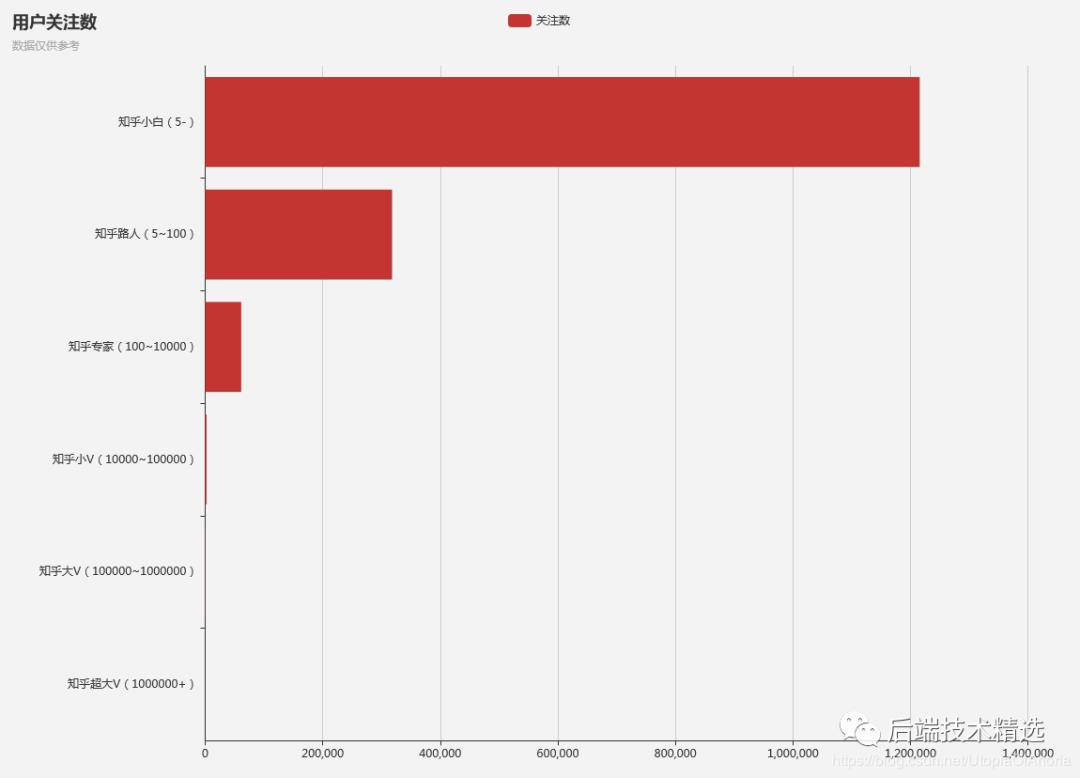
很明显地,绝大部分知乎用户都是“知乎小白”或者“知乎路人”。这里的“知乎超大V(1000000+)”的用户只有3个:“丁香医生”、“知乎日报”、“张佳玮”。
-
行业信息统计
手动整理后的行业信息图如下:
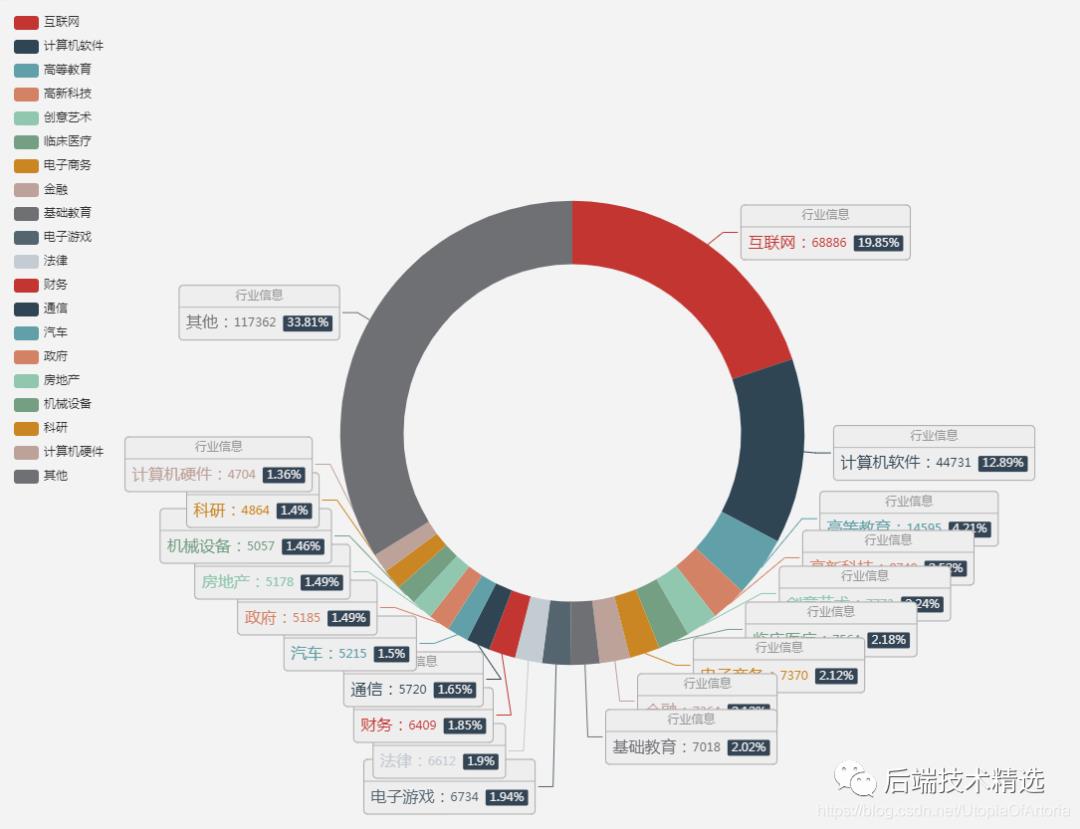
很明显地能够看出,大部分知乎用户所处的行业都与计算机或者互联网相关。
-
公司信息统计
统计了出现频率最多的前15名所属公司统计图如下:
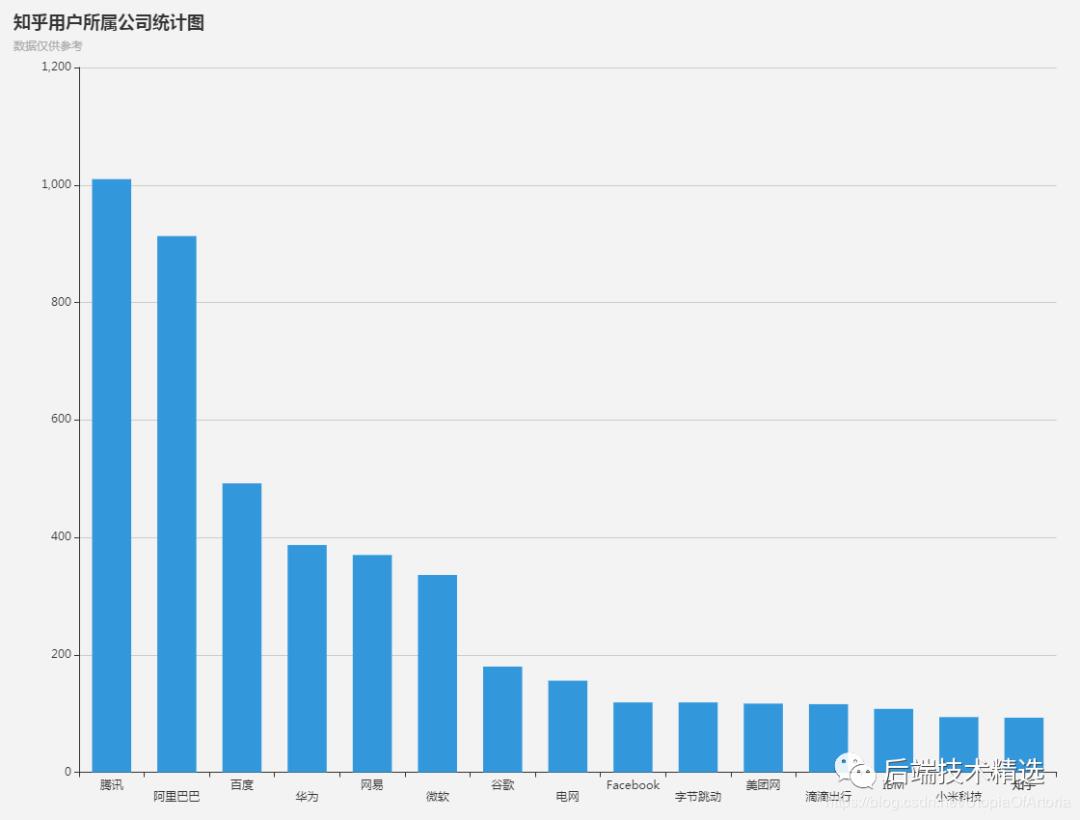
可以看到,“腾讯”、“阿里”的员工数量遥遥领先。虽然“百度”还是排名第三,但已经不在一个数量级。(“BAT”的时代真的一去不复返了吗?)
-
职位信息统计
基于职位信息统计图,利用中文在线词云生成器优词云,生成出现频率最多的前100名的职位词云图:

可以看出,除了学生以外,很多知乎用户都从事计算机或者软件编程相关的工作,也就是说,知乎用户中“程序猿/媛”所占的比重极其的大。
-
大学信息统计
统计了出现频率最多的前20名毕业院校统计图如下:
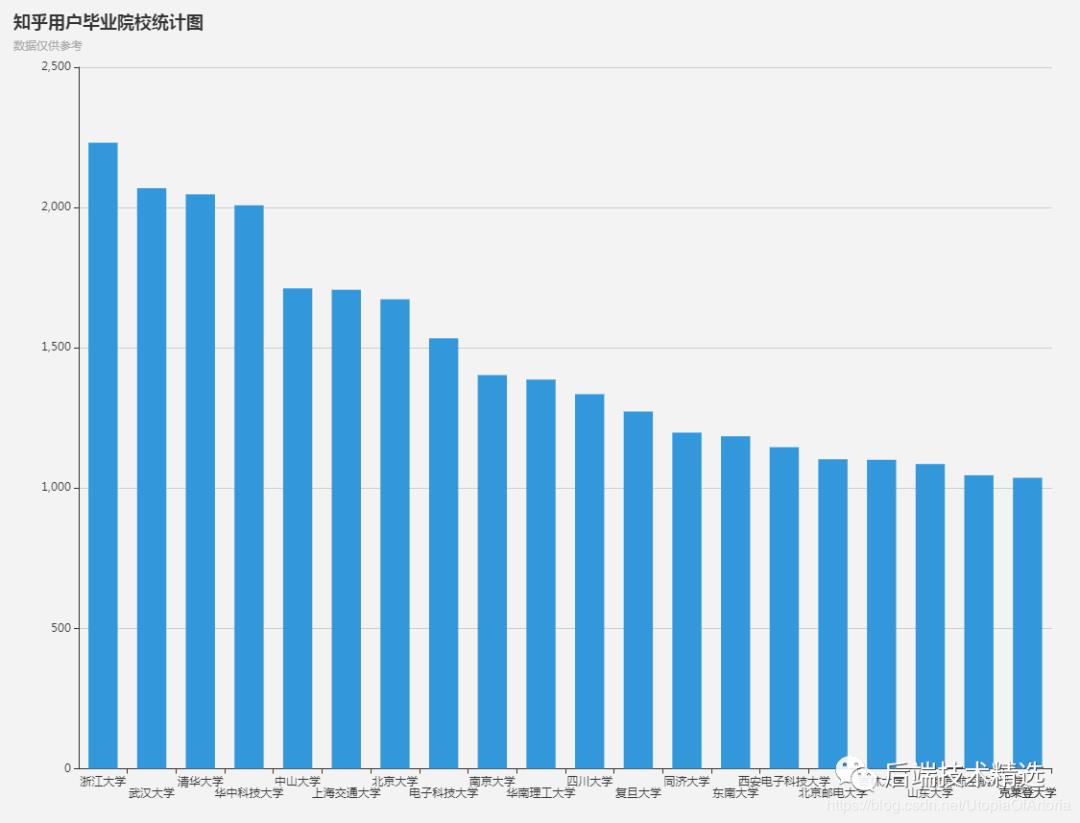
可以看到,填写了毕业院校的知乎用户(其实还有绝大部分人没有完善该信息),这些毕业院校的实力和名气那是杠杠的。
-
专业信息统计
统计了出现频率最多的前20名专业统计图如下:
可以看到,“计算机科学与技术”和“软件工程”这两个专业的人数遥遥领先。
-
居住城市信息统计
统计了出现频率最多的前20名居住城市统计图如下:
很明显地,“帝都”和“魔都”的人数遥遥领先。(这里可以做一个相关性不大、准确度不高的推论:杭州将是下一个“新一线城市”最有力的竞争者。)
5. 总结
从最终的信息统计结果来看,大部分的知乎用户信息不算完善(信息比例)。但这些统计结果图,都是基于知乎用户已经完善的信息进行整理并分析的。很明显地可以看出,已完善信息的知乎用户,基本都在发达城市大公司任职,而且其中的很大一部分是“程序猿/媛”。
也就是说,如果我(码农一枚)在工作中遇到什么专业难题时,在知乎中寻求到的答案是专业可信的。
以上是关于用Java+Redis+ES+Kibana技术对数百万知乎用户进行了数据分析,得到了这些...的主要内容,如果未能解决你的问题,请参考以下文章