关于线程池的8个灵魂拷问!
Posted 松哥说编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于线程池的8个灵魂拷问!相关的知识,希望对你有一定的参考价值。
大家好,我是松哥,今天给大家分享:线程池
之前的博客里有写过一点线程池,但是只是蜻蜓点水式的谈了一下,恰巧前段时间在工作中有了线程池的使用经验,而且线程池的优化又是一个比较有挑战的难题,所以这里借着实战经验结合原理来一篇线程池的总结文章。
为什么要用线程池?
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
-
频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。 -
对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。 -
系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,就是将资源统一在一起管理的一种思想。
线程池的核心参数
Java中的线程池核心实现类是ThreadPoolExecutor,ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。ThreadPoolExecutor,主要构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:核心线程大小,当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使有其他空闲线程可以处理任务也会创新线程,等到工作的线程数大于核心线程数时就不会在创建了。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前把核心线程都创造好,并启动
maximumPoolSize:线程池允许创建的最大线程数。如果队列满了,并且以创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。如果我们使用了无界队列,那么所有的任务会加入队列,这个参数就没有什么效果了
keepAliveTime:线程池的工作线程空闲后,保持存活的时间。如果没有任务处理了,有些线程会空闲,空闲的时间超过了这个值,会被回收掉。如果任务很多,并且每个任务的执行时间比较短,避免线程重复创建和回收,可以调大这个时间,提高线程的利用率。
unit:keepAliveTIme的时间单位,可以选择的单位有天、小时、分钟、毫秒、微妙、千分之一毫秒和纳秒。类型是一个枚举java.util.concurrent.TimeUnit,这个枚举也经常使用,有兴趣的可以看一下其源码
workQueue:工作队列,用于缓存待处理任务的阻塞队列,常见的有4种,后面有介绍
threadFactory:线程池中创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
handler:饱和策略,当线程池无法处理新来的任务了,那么需要提供一种策略处理提交的新任务,默认有4种策略,文章后面会提到
线程池的简单使用示例代码:
public class Demo1 {
static ThreadPoolExecutor executor = new ThreadPoolExecutor(3,
5,
10,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
int j = i;
String taskName = "任务" + j;
executor.execute(() -> {
//模拟任务内部处理耗时
try {
TimeUnit.SECONDS.sleep(j);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + taskName + "处理完毕");
});
}
//关闭线程池
executor.shutdown();
}
}
任务调度流程
-
首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。 -
如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。 -
如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。 -
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。 -
如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
线程池中常见5种工作队列
任务太多的时候,工作队列用于暂时缓存待处理的任务,JDK中常见的5种阻塞队列:
-
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按照先进先出原则对元素进行排序 -
LinkedBlockingQueue:是一个基于链表结构的阻塞队列,此队列按照先进先出排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool使用了这个队列。 -
SynchronousQueue :一个不存储元素的阻塞队列,每个插入操作必须等到另外一个线程调用移除操作,否则插入操作一直处理阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用这个队列 -
PriorityBlockingQueue:优先级队列,进入队列的元素按照优先级会进行排序
四种常见饱和策略
-
AbortPolicy:直接抛出异常 -
CallerRunsPolicy:在当前调用者的线程中运行任务,即随丢来的任务,由他自己去处理 -
DiscardOldestPolicy:丢弃队列中最老的一个任务,即丢弃队列头部的一个任务,然后执行当前传入的任务 -
DiscardPolicy:不处理,直接丢弃掉,方法内部为空
Executors类
Executors类,提供了一系列工厂方法用于创建线程池,返回的线程池都实现了ExecutorService接口。常用的方法有:
-
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。内部使用了无限容量的LinkedBlockingQueue阻塞队列来缓存任务,任务如果比较多,单线程如果处理不过来,会导致队列堆满,引发OOM。
-
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,在提交新任务,任务将会进入等待队列中等待。如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。内部使用了无限容量的LinkedBlockingQueue阻塞队列来缓存任务,任务如果比较多,如果处理不过来,会导致队列堆满,引发OOM。
-
newCachedThreadPool
public static ExecutorService newCachedThreadPool()
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒处于等待任务到来)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池的最大值是Integer的最大值(2^31-1)。内部使用了SynchronousQueue同步队列来缓存任务,此队列的特性是放入任务时必须要有对应的线程获取任务,任务才可以放入成功。如果处理的任务比较耗时,任务来的速度也比较快,会创建太多的线程引发OOM。
-
newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory)
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过ThreadPoolExecutor方式实现,使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
线程池虽然在并发编程里很强大,但线程池使用面临的核心的问题在于:线程池的参数并不好配置。一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考。
美团方案
比如网上流传的比较多的一个策略:
-
如果是CPU密集型任务,就需要尽量压榨CPU,参考值可以设为 N(CPU)+1(比如是4核心 就配置为5) -
如果是IO密集型任务,参考值可以设置为 2*N(CPU)
CPU密集型的为什么要+1呢?《Java并发编程实战》给出的原因是:即使当计算(CPU)密集型的线程偶尔由于页缺失故障或者其他原因而暂停时,这个“额外”的线程也能确保 CPU 的时钟周期不会被浪费。
这里先来看看美团帮我们总结的现在业界的一些线程池调参方案:

第一套方案是并发编程实战给出的,明显太理论化了,和实际业务想去甚远!
N(threads) = N(Cpu个数)*U(cpu的使用率)*(1+ 等待时间/计算时间)
第二套方案就没有考虑多个业务线程池的情况。第三套方案的用到了TPS来参与计算,但是这也是流量恒定情况下算出来的,真实情况往往比较随机。
有啥比较好的办法吗?——那就是:线程池参数动态化,采用这种方案最好就是用这么一个办法来做:
-
简化线程池配置:线程池构造参数有8个,但是最核心的是3个:corePoolSize、maximumPoolSize,workQueue,它们最大程度地决定了线程池的任务分配和线程分配策略 -
参数可动态修改:为了解决参数不好配,修改参数成本高等问题 -
加线程池监控
为什么能做到动态修改线程池参数呢?这是因为JDK本身就提供api方法支持动态的修改:
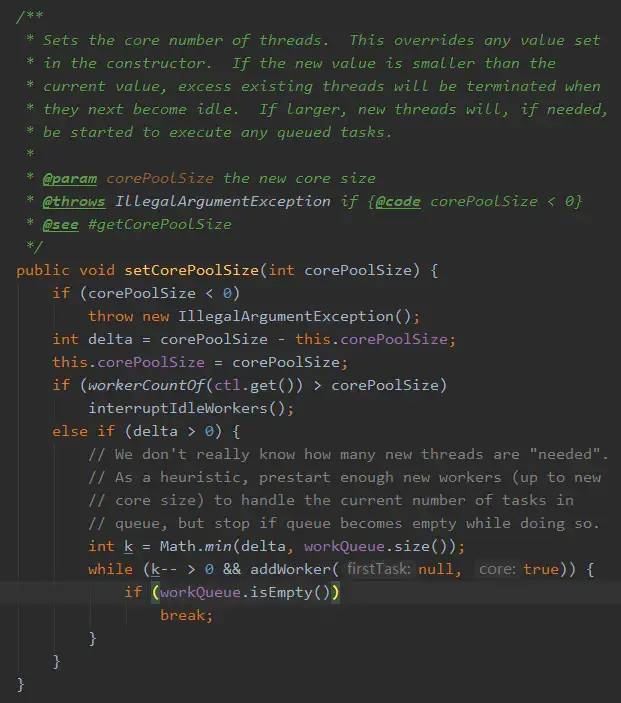
至于如何在运行时状态实时查看,这里也有一个办法:用户基于JDK原生线程池ThreadPoolExecutor提供的几个public的getter方法,可以读取到当前线程池的运行状态以及参数:

用户基于这个功能可以了解线程池的实时状态,比如当前有多少个工作线程,执行了多少个任务,队列中等待的任务数等等。
Netty进阶指南给出来的方案
在Netty服务编写的过程中,也要涉及到两个线程池的参数配置,尤其是IO线程池的配置,这里书中也给了一套经验方案来针对线程的监控情况,可以参考:同样的先用CPU核数*2,看看是否存在瓶颈,运行时的监控则用比较土的办法了:
-
打印 thread dump,同时获取当时cpu排在前面几个的线程号 -
然后在线程dump文件中去对应的线程号堆栈 -
然后在堆栈中查找是否有 SelectotImpl.lookAndDoSelect处的lock信息
如果多次采集都发现有这堆信息的话,说明此时此刻的IO线程比较空闲,无需调整;但是如果一直在read或者write的执行处,则说明IO较为繁忙,可以适当的去调大NioEventLoop线程的个数来提升网络的读写性能。但是这边线程数的改动就不是动态化的了,服务启动后指定的线程数就不能再修改了。
好了,今天的分享就到这里了,记得关注松哥哟!
以上是关于关于线程池的8个灵魂拷问!的主要内容,如果未能解决你的问题,请参考以下文章