球迷福利NBA球员数据分析
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了球迷福利NBA球员数据分析相关的知识,希望对你有一定的参考价值。
数据分析综合实战
前言
每个球迷心中都有一个属于自己的迈克尔·乔丹、科比·布莱恩特、勒布朗·詹姆斯。
当然我也是一名热爱篮球的小伙伴,这篇文章很适合篮球爱好者与编程爱好者。
本案例将用jupyter notebook完成NBA菜鸟数据分析初探。 案例中使用的数据是2017年NBA球员基本数据,数据字段见下表:
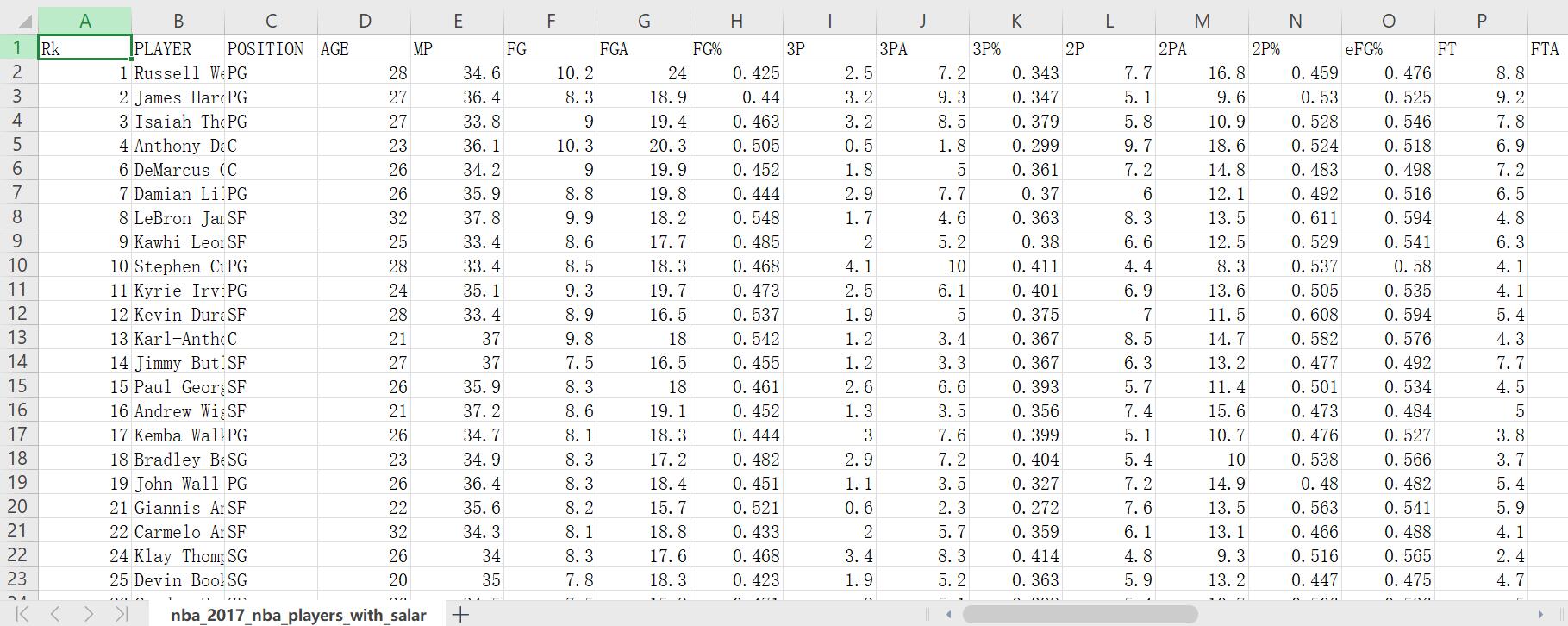
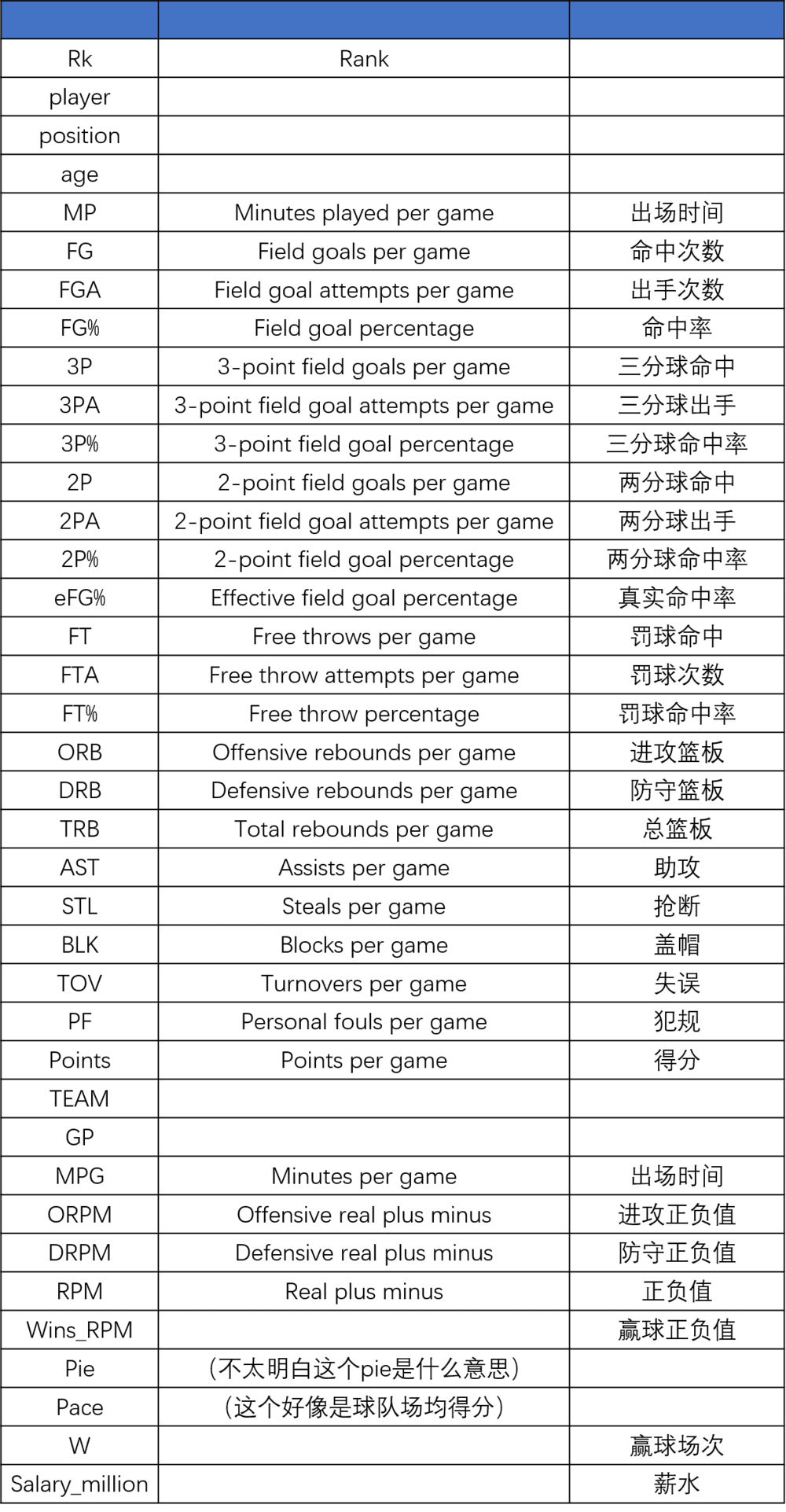
数据解释
数据来源:nba_2017_nba_players_with_salary.csv
导入需要的科学计算库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
导入数据
data = pd.read_csv('./data/nba_2017_nba_players_with_salary.csv')
data.head()
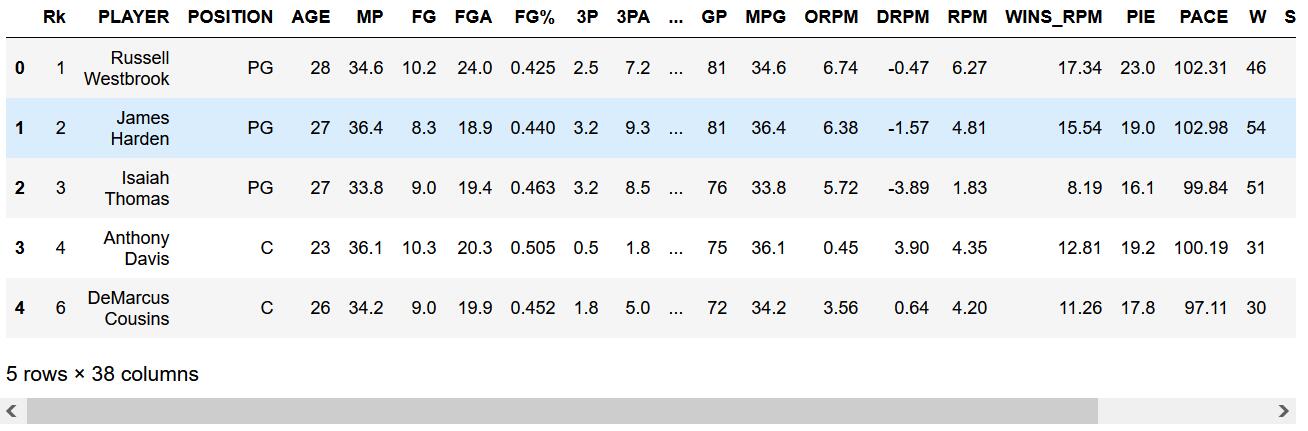
可以看到第一名是维斯布鲁克啊,原来是威少暴走的16-17赛季呀,啊呀呀!!!
我们可以看到该数据的前五列是按当年的得分榜排序的,分别是威少、詹皇、地表最强175、浓眉哥和考神。而数据包含39列,即不同维度的技术统计。而此份数据提供了这300+球员的众多项比赛数据,我希望通过数据分析来发现其中的有趣的信息。
data.shape
(342, 38)
描述统计
data.describe()
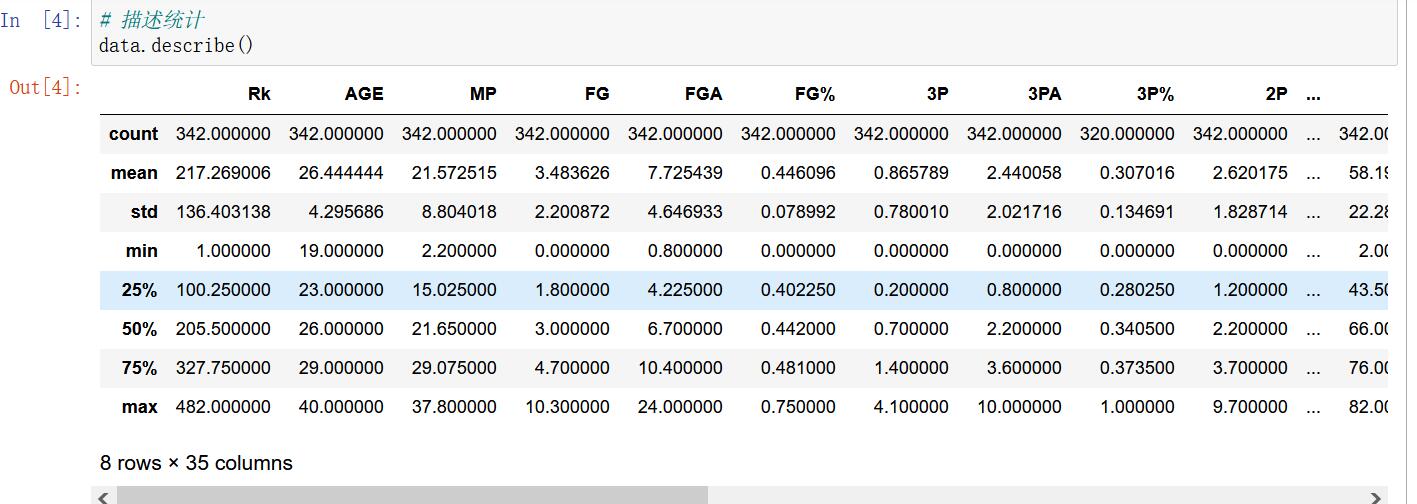
输出结果部分展示:
从数据中看几项比较重要的信息:
球员平均年龄为26.4岁,年龄段在19-40岁;
球员平均年薪为730万美金,当时最大的合同为年薪3000万美金;
球员平均出场时间为21.5分钟,某球员场均出场37.8分钟领跑联盟,当然也有只出场2.2分钟的角色球员,机会来之不易。
类似的信息我们还能总结很多。
数据分析
效率值相关性分析
在众多的数据中,有一项名为“RPM”,标识球员的效率值,该数据反映球员在场时对球队比赛获胜的贡献大小,最能反映球员的综合实力。
我们来看一下它与其他数据的相关性:
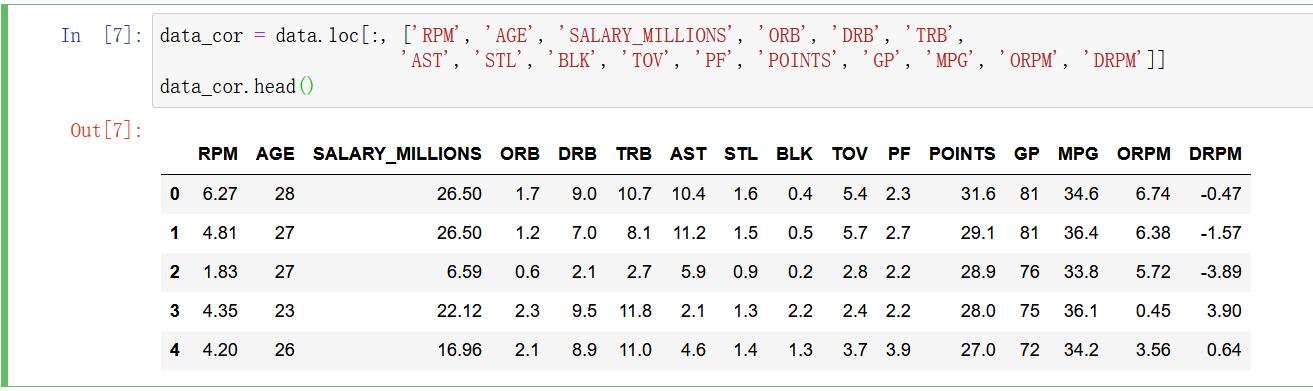
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB',
'AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor.head()
获取两列数据之间的相关性
# 获取两列数据之间的相关性
corr = data_cor.corr()
corr.head()

dat_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB',
'AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
coor = dat_cor.corr()
sns.heatmap(coor, square=True, linewidths=0.02, annot=True)
# annot-是否在热力图中显示数据
# seaborn中的heatmap函数,是将多维度数值变量按数值大小进行交叉热图展示。
plt.show()
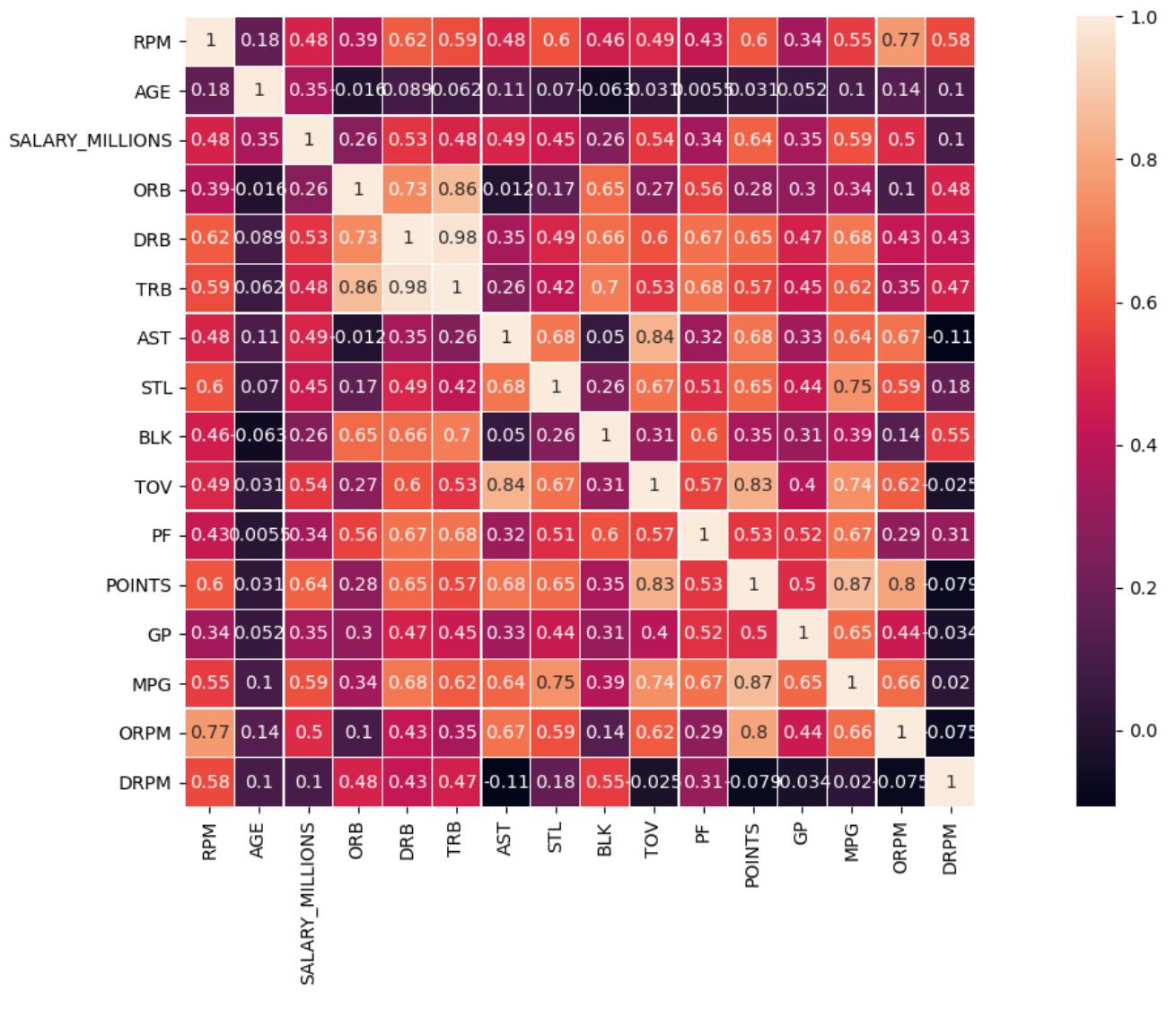
由相关性分析的heatmap图可以看出,RPM值与年龄的相关性最弱,与“进攻效率值-ORPM”、“场均得分-POINTS”、“场均抢断数-STL”等比赛技术数据的相关性最强。
接下来的分析中将把RPM作为评价一个球员能力及状态的直观反应因素之一。
球员数据分析
基本数据排名分析
薪资最高的10名球星
此处练习了一下pandas基本的数据框相关操作,包括提取部分列、head()展示、排序等,简单通过几个维度的展示,笼统地看一下16-17赛季那些球员冲在联盟的最前头。
# 薪资最高的10名运动员
data.loc[:, ['PLAYER', 'SALARY_MILLIONS', 'RPM', 'AGE', 'MPG']
].sort_values(by='SALARY_MILLIONS', ascending=False).head(10)
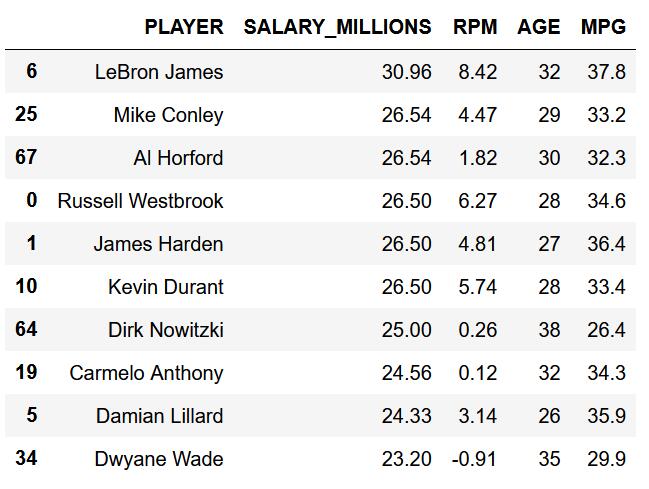
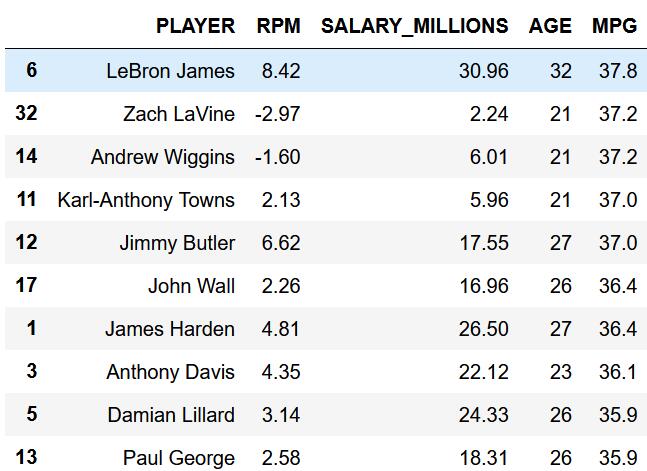
勒布朗詹姆斯为该赛季薪水最高的球员,麦克康利拿到了大合同,但是在群星璀璨的薪金榜单上略显黯淡。同样出现在榜单的还有威少、哈登、杜兰特等球星,库里由于之前的合同太小,并没有出现在前10名里。
效率值最高的10名球星
# 效率值最高的10名运动员
data.loc[:, ['PLAYER', 'RPM', 'SALARY_MILLIONS', 'AGE', 'MPG']
].sort_values(by='RPM', ascending=False).head(10)
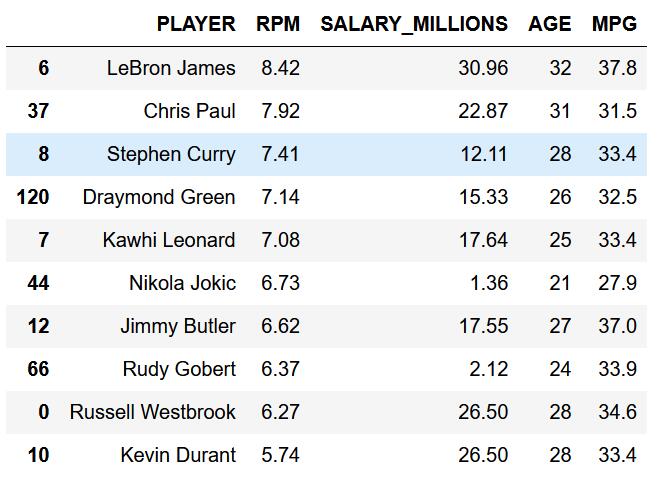
詹皇拿着联盟最高的薪水,打球也毫不含糊,效率值排名第一。
保罗和库里紧随其后,在前10的榜单里,宇宙勇占据3席。
值得一提的是,掘金队的约基奇和爵士队的戈贝尔,拿着较为微薄的工资却打出了联盟前10的效率,这也为他们接下来的大合同奠定了基础。
出场时间最高的10名球星
# 出场时间最高的10名运动员
data.loc[:, ['PLAYER', 'RPM', 'SALARY_MILLIONS', 'AGE', 'MPG']
].sort_values(by='MPG', ascending=False).head(10)
Seaborn常用的三个数据可视化方法
单变量
我们先利用seaborn中的distplot绘图来分别看一下球员薪水、效率值、年龄这三个信息的分布情况,上代码:
# 利用seaborn中的displot绘图来分别看一下球员的薪水、效率值、年龄这三个信息的分布情况
# 分布及核密度展示
sns.set_style('darkgrid') # 设置seaborn的面板风格
# 获取画布
plt.figure(figsize=(10, 10))
# 拆分页面,多图展示
plt.subplot(3, 1, 1)
# 绘制直方图图像
sns.distplot(data['SALARY_MILLIONS'])
# 把0--40之间,分成9个间隔(包含0和40)
plt.xticks(np.linspace(0, 40, 9))
# y轴标签
plt.ylabel('Salary', size=10) # size:设置字体大小
# 拆分画布
plt.subplot(3, 1, 2)
# 绘制直方图图像
sns.distplot(data['RPM'])
plt.xticks(np.linspace(-10, 10, 9))
# y轴标签
plt.ylabel('RPM', size=10)
# 拆分画布
plt.subplot(3, 1, 3)
# 绘制直方图图像
sns.distplot(data['AGE'])
plt.xticks(np.linspace(20, 40, 11))
# y轴标签
plt.ylabel('AGE', size=10)
plt.show()
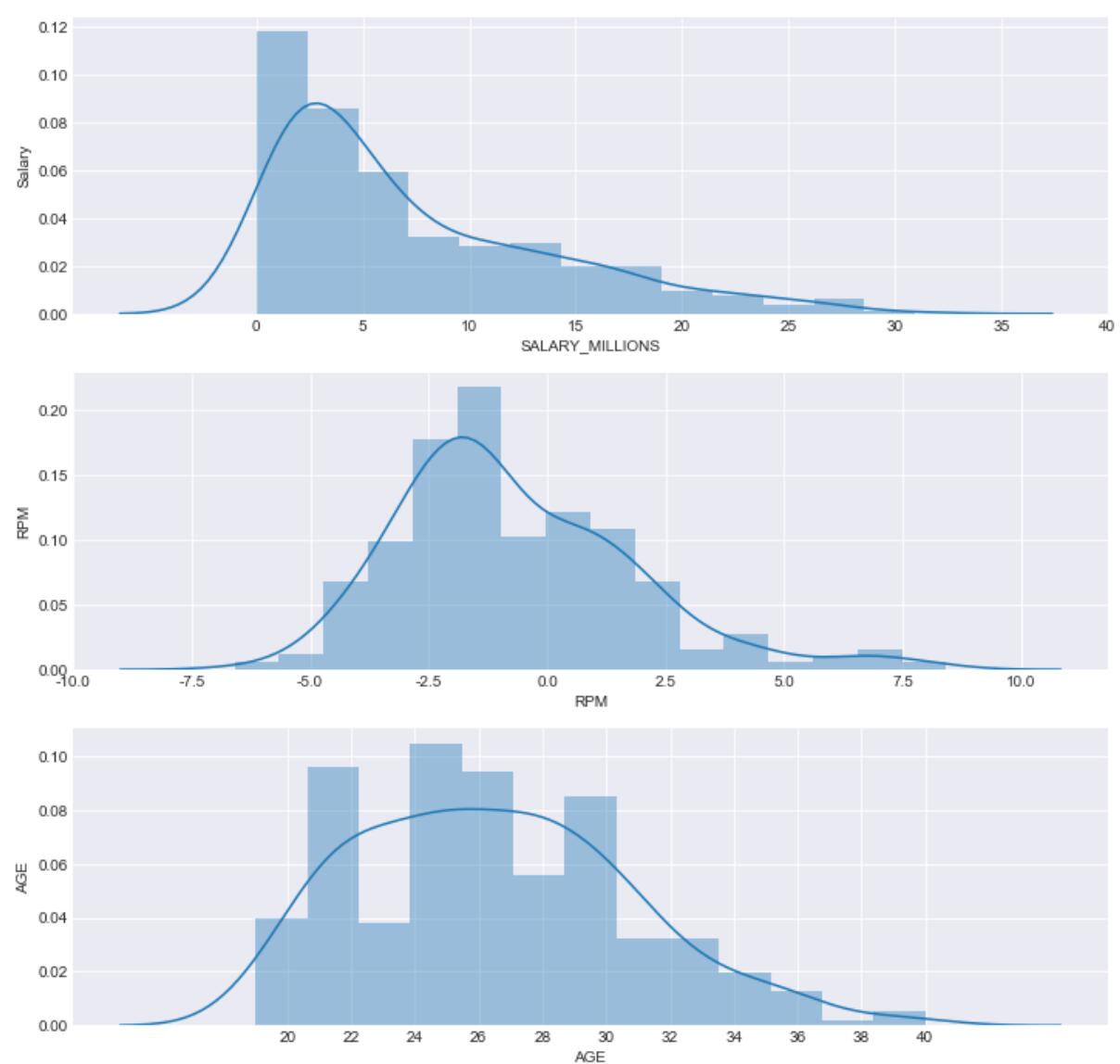
可见年龄和效率值更符合正态分布,而球员薪水更像一个偏态分布,拿高薪的球员占据较小的比例。
这些与我们的主观感受基本一致,那么这些变量之间是否有什么隐藏的关系呢?
这里可以用seaborn中的pairplot绘图展示多个变量之间的关系:
双变量
二维直方图hex
# 使用jointplot查看年龄和薪水之间的关系
dat1 = data.loc[:, ['RPM', 'SALARY_MILLIONS', 'AGE', 'POINTS']]
sns.jointplot(dat1.SALARY_MILLIONS, dat1.AGE, kind='kde', height=8)
plt.show()
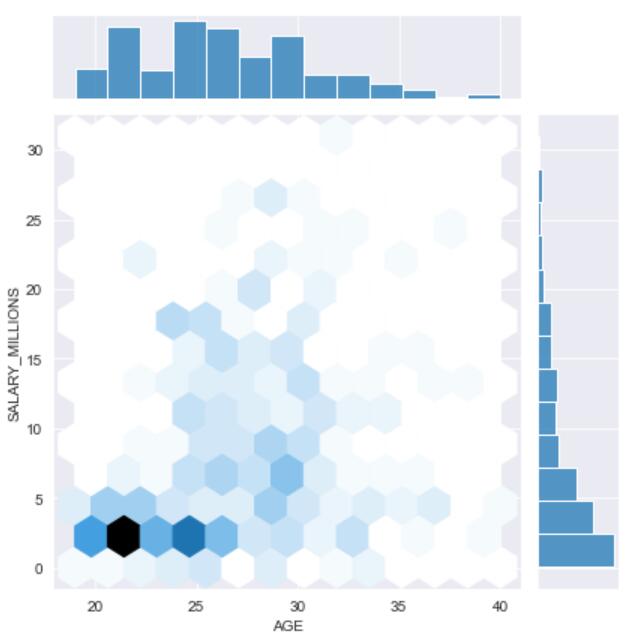
hex:二维直方图类似于“六边形”图,主要是因为它显示了落在六角形区域内的观察值的计数,适用于较大的数据集。当调用 jointplot()函数时,只要传入kind=“hex”,就可以绘制二维直方图。
核密度估计kde
# 使用jointplot查看年龄和薪水之间的关系
dat1 = data.loc[:, ['RPM', 'SALARY_MILLIONS', 'AGE', 'POINTS']]
sns.jointplot(dat1.SALARY_MILLIONS, dat1.AGE, kind='kde', height=8)
plt.show()
kde:利用核密度估计同样可以查看二元分布,其用等高线图来表示。当调用jointplot()函数时只要传入ind=“kde”,就可以绘制核密度估计图形
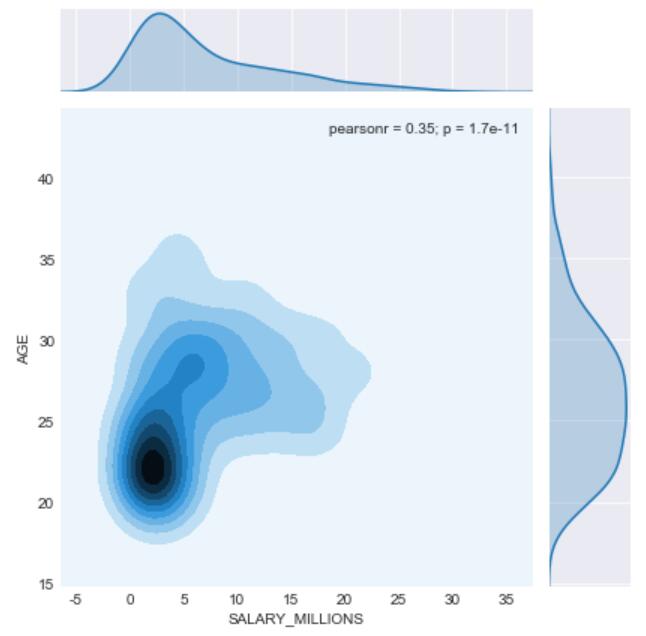
上图展示的是球员薪水与年龄的关系,采用不同的kind方式(等高线图/hex/散点等),我们可以整体感受一下年龄和薪水的集中特点,大部分球员集中在22-25岁拿到5million以下的薪水,当然也有“年少成名”和“越老越妖”的情况。
多变量
用seaborn中的pairplot绘图展示多个变量之间的关系
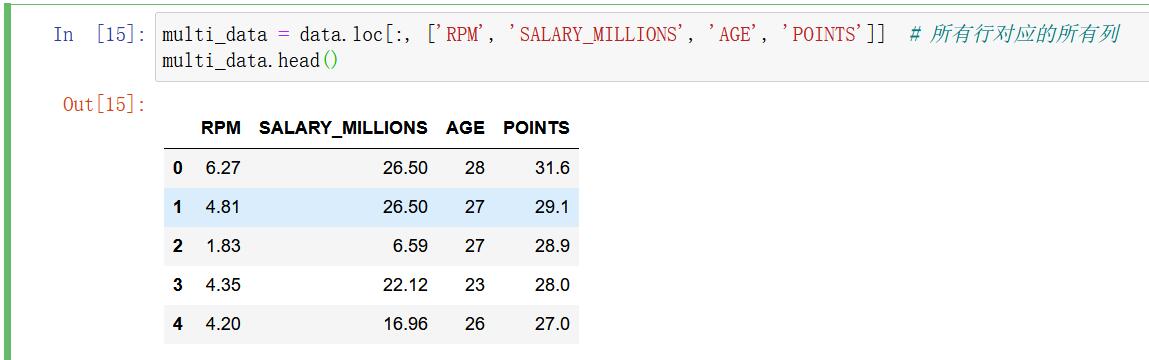
multi_data = data.loc[:, ['RPM', 'SALARY_MILLIONS', 'AGE', 'POINTS']] # 所有行对应的所有列
multi_data.head()
# 用seaborn中的pairplot绘图展示多个变量之间的关系
# 所有行对应的所有列
dat1=data.loc[:,['RPM','SALARY_MILLIONS','AGE','POINTS']]
#相关性展示,斜对角为分布展示,可以直观地看变量是否具有现行关系
sns.pairplot(dat1)
plt.show()
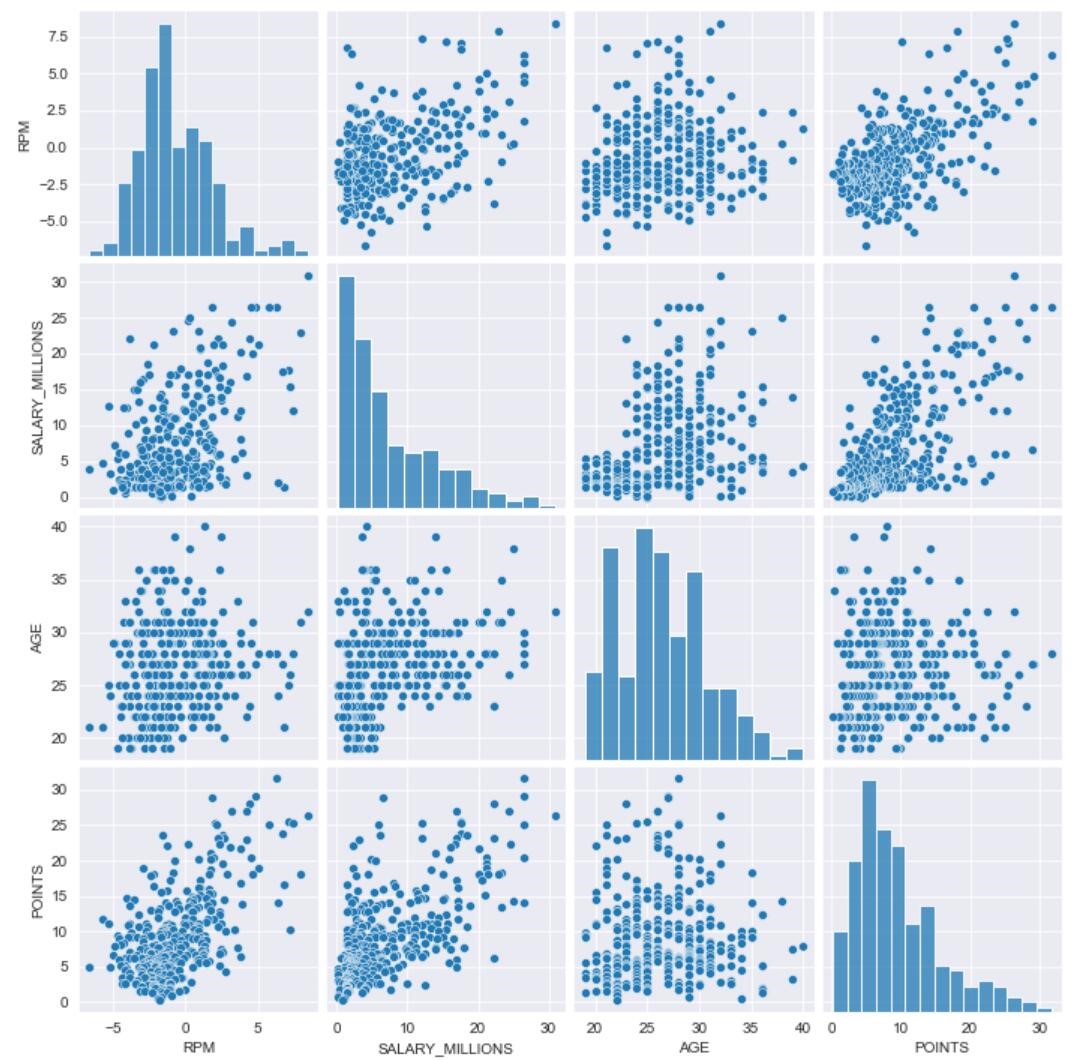
上图展示的是球员薪水、效率值、年龄及场均得分四个变量间的两两相关关系,对角线展示的是本身的分布图,由散点的趋势我们可以看出不同特征的相关程度。
整体看各维度的相关性都不是很强,正负值与薪水和场均得分呈较弱的正相关性,而年龄这一属性和其他的变量相关性较弱,究竟是家有一老如有一宝还是廉颇老矣,接下来我们从年龄维度入手进一步分析.
衍生变量的一些可视化实践
以年龄为例
在已有的数据集里想要生成新的变量,例如:把球员按年龄分为老中青三代,可以借助定义一个函数,再利用apply的方式,生成新的变量。
# 思路tips: 根据已有变量生成新的变量
data['avg_point'] = data['POINTS']/data['MP'] # 每分钟得分
# 分割年龄
def age_cut(df):
if df.AGE <= 24:
return 'young'
elif df.AGE >= 30:
return 'old'
else:
return 'best'
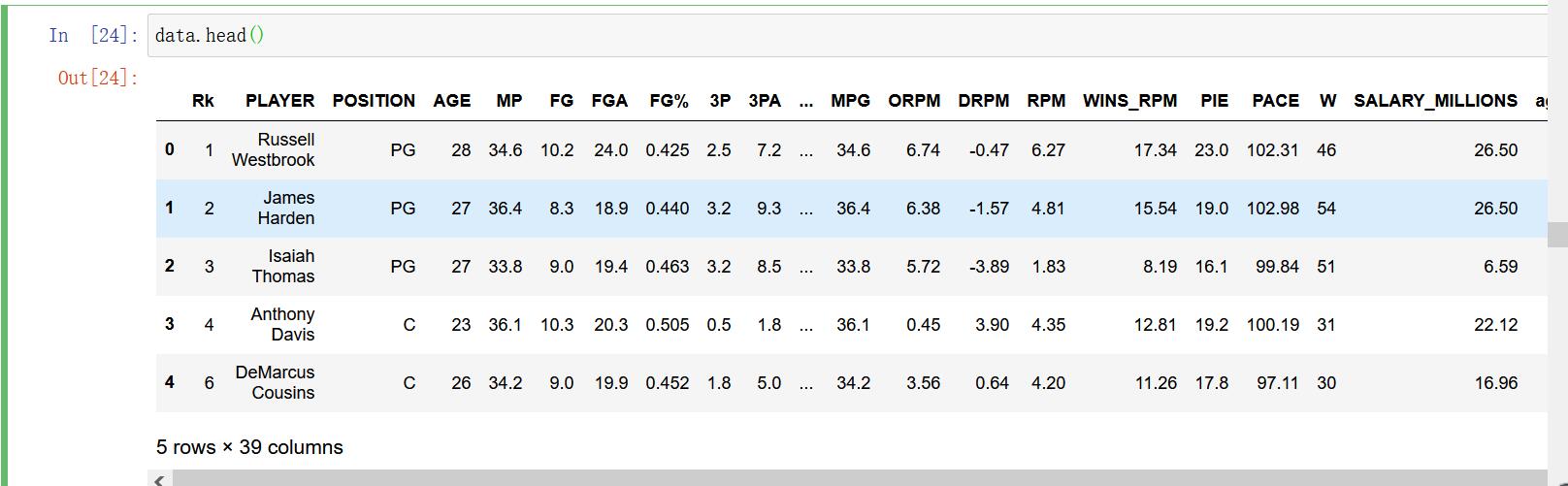
data['age_cut'] = data.apply(lambda x: age_cut(x), axis=1) # 球员是否处于黄金年龄
data['cnt'] = 1 # 计数用
data.head()
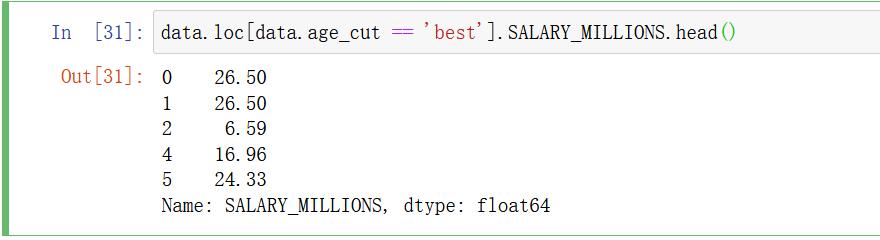
data.loc[data.age_cut == 'best'].SALARY_MILLIONS.head()
既然得到了老中青三代的标签,我们来看一下不同年龄段球员的RPM(正负值)与薪水之前的关系如何:
# 球员薪水与效率值 按年龄段来看
sns.set_style('darkgrid') # 设置seaborn的面板风格
plt.figure(figsize=(8, 8), dpi=100)
plt.title('RPM and SALARY', size=15)
X1 = data.loc[data.age_cut == 'old'].SALARY_MILLIONS
Y1 = data.loc[data.age_cut == 'old'].RPM
plt.plot(X1, Y1, '.')
X2 = data.loc[data.age_cut == 'best'].SALARY_MILLIONS
Y2 = data.loc[data.age_cut == 'best'].RPM
plt.plot(X2, Y2, '^')
X3 = data.loc[data.age_cut == 'young'].SALARY_MILLIONS
Y3 = data.loc[data.age_cut == 'young'].RPM
plt.plot(X3, Y3, '.')
plt.xlim(0, 30)
plt.ylim(-8, 8)
plt.xlabel('Salary')
plt.ylabel('RPM')
plt.xticks(np.arange(0, 30, 3))
# 绘制图例
plt.legend(['old', 'best', 'young'])
# 显示图像
plt.show()
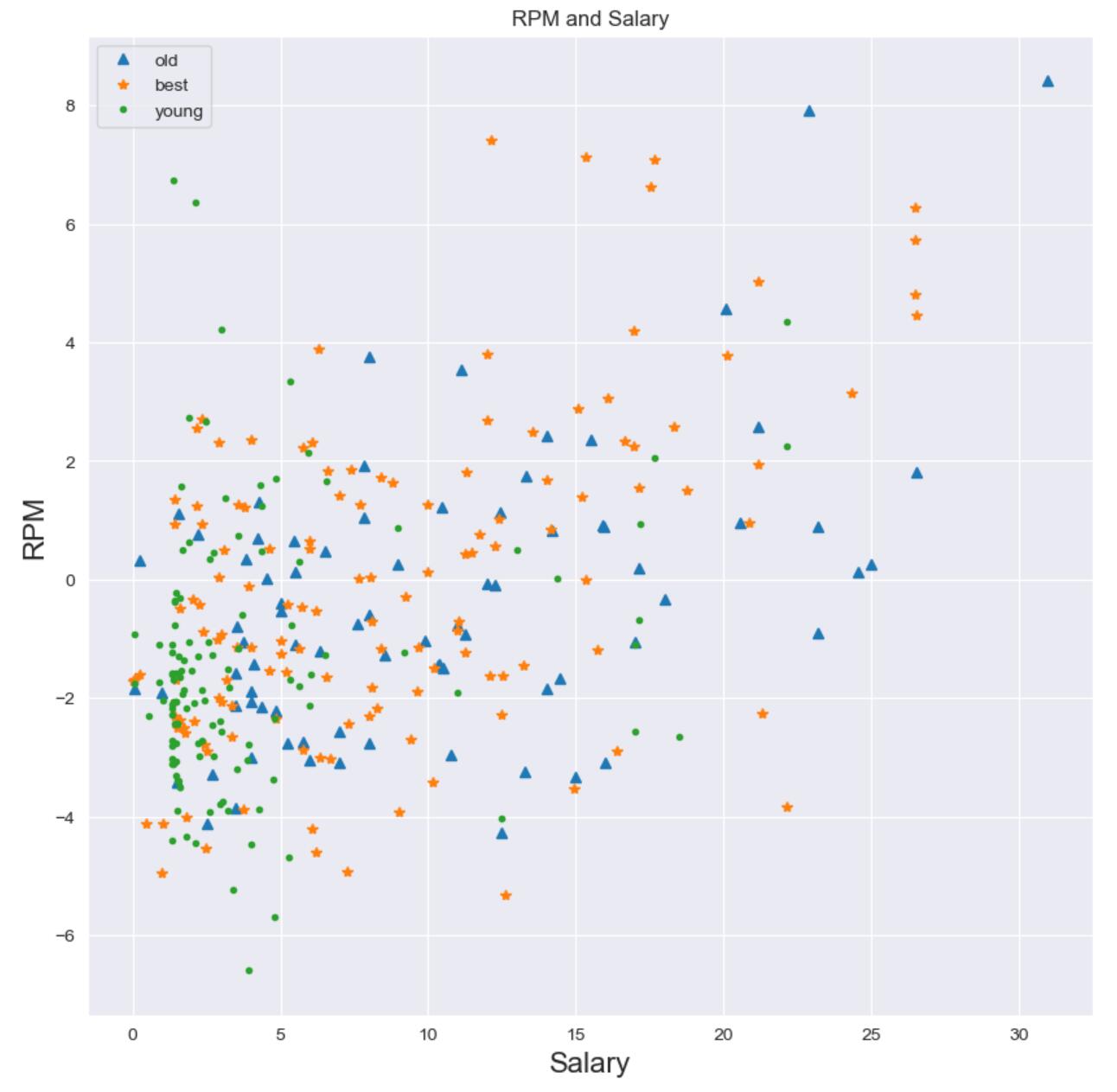
点图横坐标为球员薪水,纵坐标为效率值。可以观测到:
绝大部分的年轻球员拿着较低的薪水,数据非常集中。有两个离群点,是上文提到的戈贝尔和约基奇,两个小兄弟前途无量啊。
黄金年龄的球员和老球员的数据相对发散,黄金年龄球员薪水与效率值正相关性更强。第一集团有几个全明星排头兵。
老球员过了呼风唤雨的年纪,运动状态有所下滑,“高薪低效”的球员也稍微多一些。
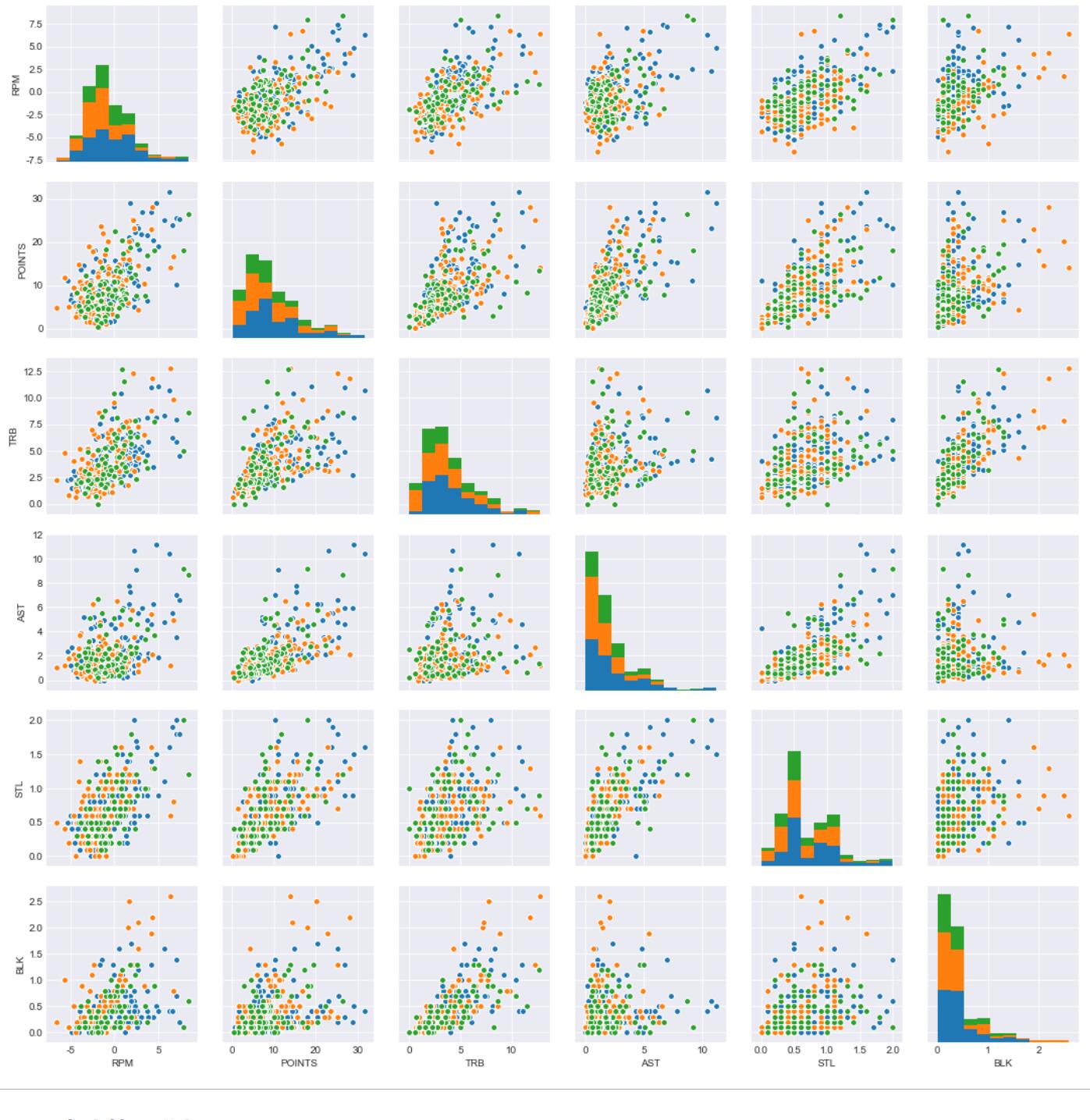
用上篇的方法看一下老中青三代各技术统计的分布情况:
dat2=data.loc[:,['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(dat2,hue='age_cut')
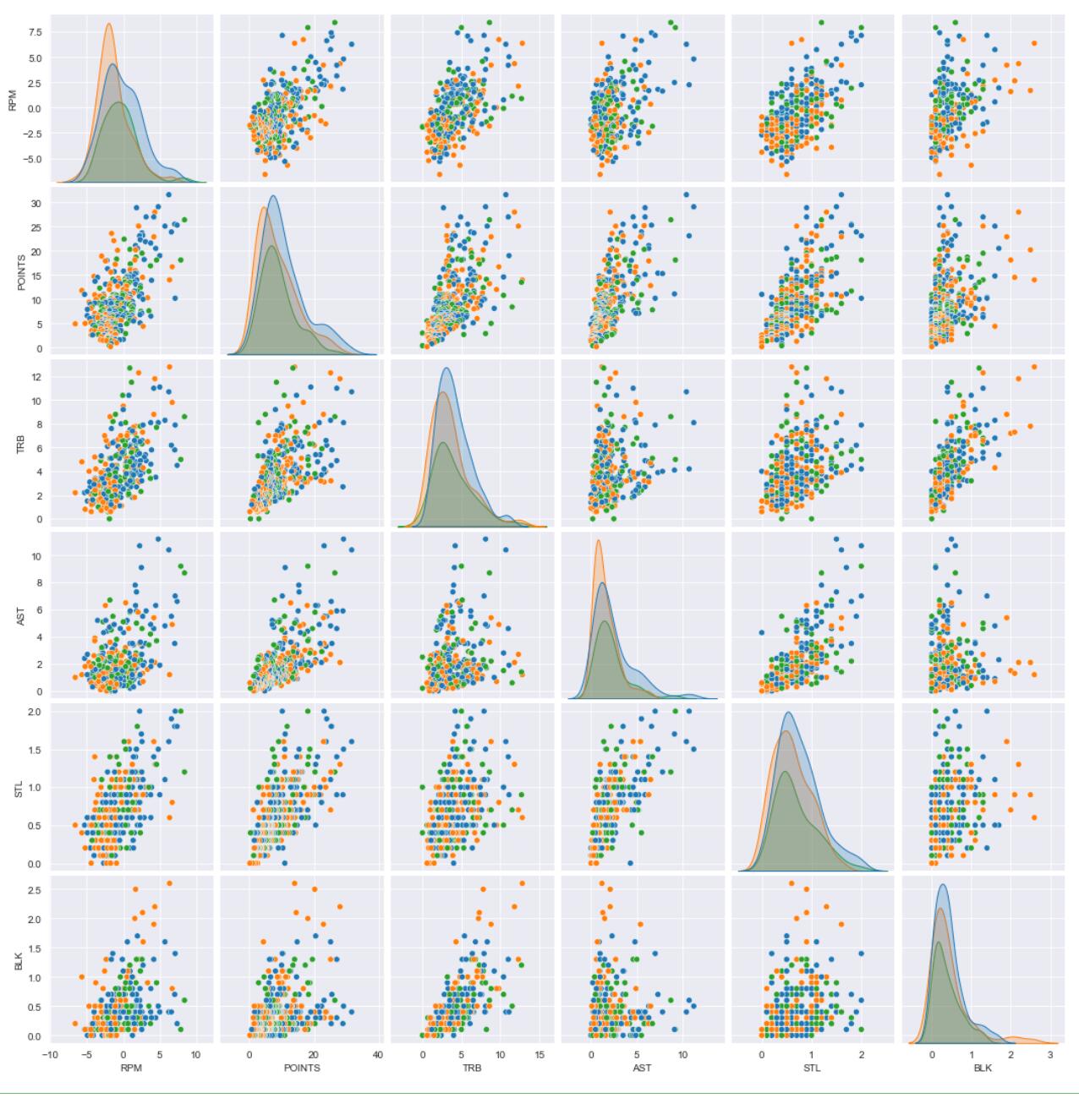
multi_data2 = data.loc[:, ['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(multi_data2, hue='age_cut') # 按照标签进行分类加颜色
球队数据分析
球队薪资排行
将数据按球队分组,平均薪水降序排列,看一下联盟十大土豪球队:
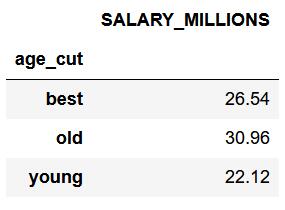
# 按照年龄进行划分,按照平均薪水薪水进行聚合
data.groupby(by='age_cut').agg({'SALARY_MILLIONS': np.mean}) # 分组聚合不分家
data_team = data.groupby(by='TEAM').agg({'SALARY_MILLIONS': np.mean}) # 分组聚合不分家
data_team.sort_values(by='SALARY_MILLIONS', ascending=False).head(10)
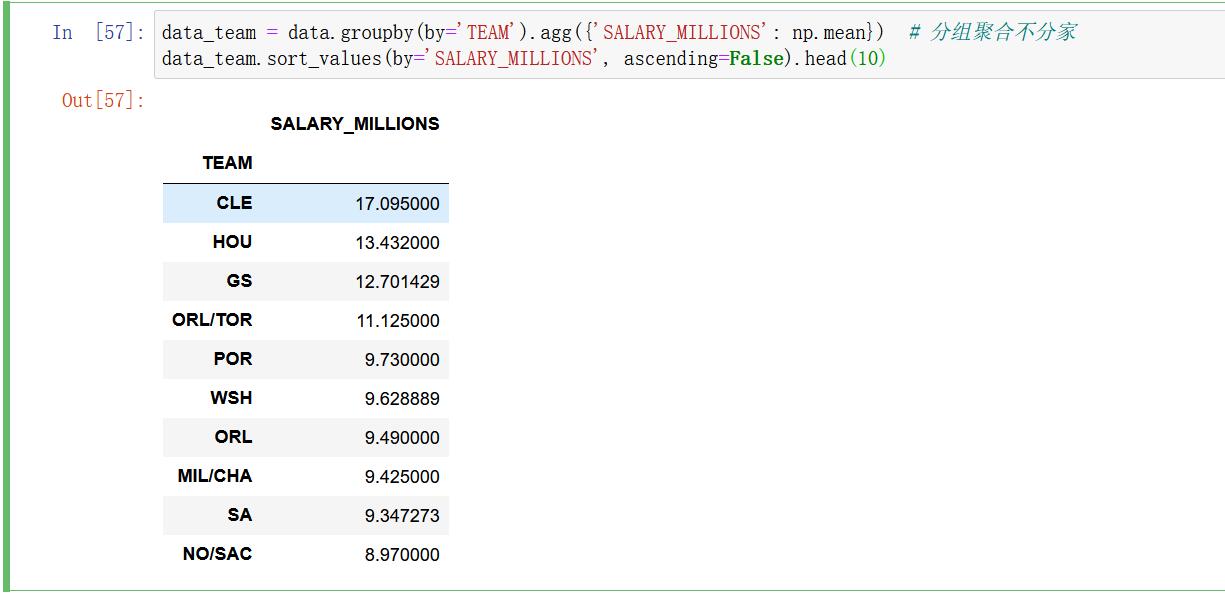
# 分组操作 按球队
dat_grp = data.groupby(by=['TEAM'], as_index=False).agg(
{'SALARY_MILLIONS': np.mean, 'RPM': np.mean, 'PLAYER': np.size})
dat_grp.sort_values(by='SALARY_MILLIONS', ascending=False).head(10)
骑士队和勇士队已超高的薪水排在这份榜单的前两名,群星璀璨的他们最终在季后赛中一路厮杀,双双闯入分区决赛。
排在第三的开拓者有10名球员上榜,可谓后补活力充沛。球队薪金结构的健康与否对球队的发展至关重要。
球队年龄结构
先胖不算胖,后胖压倒炕,优质的年轻球员储备是保持球队竞争性的密匙。
我按照分球队分年龄段,上榜球员降序排列,如上榜球员数相同,则按效率值降序排列。
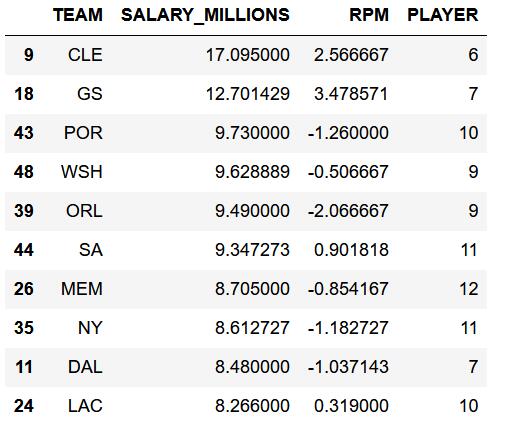
# 分组操作 按场上位置
dat_grp2 = data.groupby(by=['TEAM', 'age_cut'], as_index=False).agg(
{'SALARY_MILLIONS': np.mean, 'RPM': np.mean, 'PLAYER': np.size})
dat_grp2.sort_values(by=['PLAYER', 'RPM'], ascending=False).head(15)
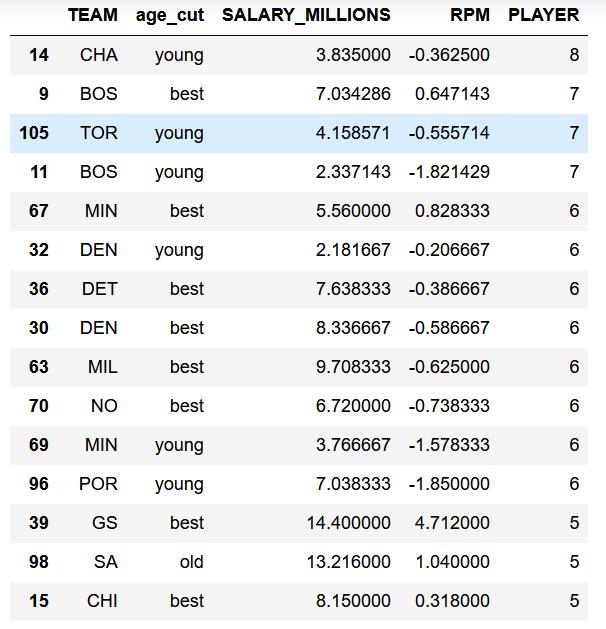
在这份榜单里,排在榜首的公牛队(CHA)有年轻球员8人,但效率值偏低,小伙子们还需努力啊。
绿凯(BOS) 不得了,黄金年龄球员和年轻球员共14人,效率值较高,未来一片光明。
年轻的 森林狼(MIN) 有6名黄金年龄球员,老马刺(SA) 有5为年长球员,一老一小效率值还都不错。
最牛的还属宇宙勇(GS),5名黄金年龄球员效率值为恐怖的4.7,明星在手天下我有!
球队综合实力分析
最后我们来看看球队综合实力:
按照效率值降序排列前10名球队的相关信息如下:
# 数据可视化 按球队
dat_grp3 = data.groupby(by=['TEAM'], as_index=False).agg({'SALARY_MILLIONS': np.mean,
'RPM': np.mean,
'PLAYER': np.size,
'POINTS': np.mean,
'eFG%': np.mean,
'MPG': np.mean,
'AGE': np.mean})
dat_grp3 = dat_grp3.loc[dat_grp3.PLAYER > 5]
dat_grp3.sort_values(by=['RPM'], ascending=False).head(10)
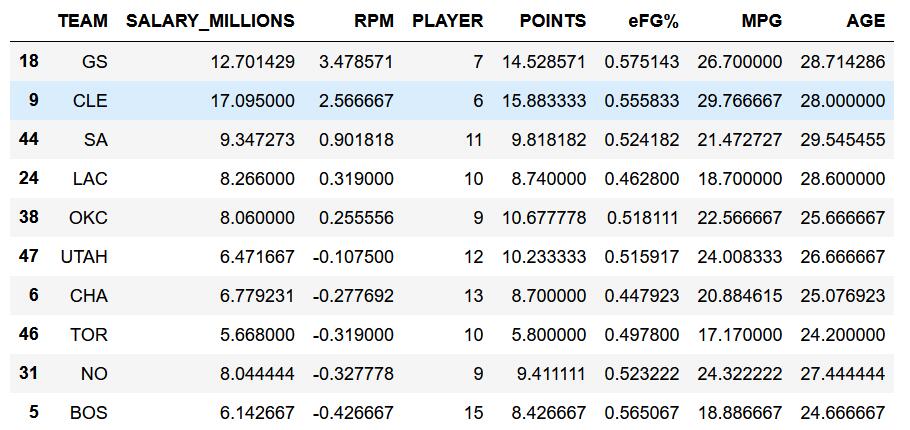
勇士(GS)和骑士(CLE) 占据前两名的位置,效率值反映球队实力的事实情况。
老马刺(SA) 排名第三,平均年龄达29.5岁排名第一,更新血液迫在眉睫。
雷霆(OKC) 由于大威少的存在能排在第5位,各项数据中规中矩。
箱线图
利用箱线图和小提琴图看着10支球队的相关数据
data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS']).head()

# 利用箱线图和小提琴图看着10支球队的相关数据
# 箱线图
sns.set_style('whitegrid') # 设置seaborn的面板风格
plt.figure(figsize=(20, 10))
# 获取相应数据
data_team2 = data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])] # 从data中取数据,要输TEAM那就是data.TEAM
# 进行相应绘图
# 分割画板
plt.subplot(3以上是关于球迷福利NBA球员数据分析的主要内容,如果未能解决你的问题,请参考以下文章