NLP 笔记:Skip-gram
Posted 刘文巾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP 笔记:Skip-gram相关的知识,希望对你有一定的参考价值。
1 skip-gram举例
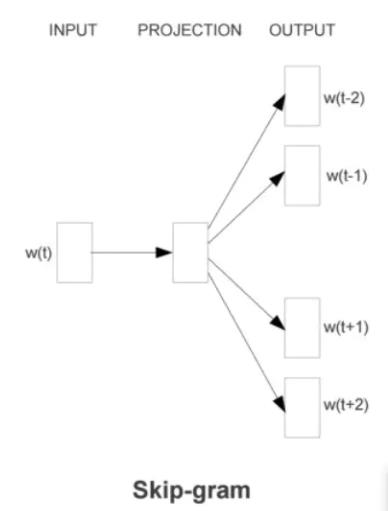
假设在我们的文本序列中有5个词,[“the”,“man”,“loves”,“his”,“son”]。
假设我们的窗口大小skip-window=2,中心词为“loves”,那么上下文的词即为:“the”、“man”、“his”、“son”。这里的上下文词又被称作“背景词”,对应的窗口称作“背景窗口”。
跳字模型能帮我们做的就是,通过中心词“loves”,生成与它距离不超过2的背景词“the”、“man”、“his”、“son”的条件概率,用公式表示即:
![]()
进一步,假设给定中心词的情况下,背景词之间是相互独立的,公式可以进一步得到
![]()
用概率图表示为:
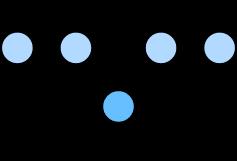
可以看得出来,这里是一个一对多的情景,根据一个词来推测2m个词,(m表示背景窗口的大小)。
2 skip-gram 逐步解析
2.1 one-hot word symbol(编码)
在NLP学习笔记:word2vec_刘文巾的博客-CSDN博客 中我们说过 one-hot编码有很多的弊端(需要的空间很冗余,且无法反映单词之间的相似程度)。
但是计算机没办法识别“字符”,所有的数据必须先转化成二进制的编码形式,one-hot编码就是最便捷的一种表达方式了。(这里的one-hot只是一种过渡)
2.2 词嵌入(word embedding)
但是,one-hot表达的向量过于稀疏。我们需要用一个稠密的向量来表示单词空间。(这个向量是可以在空间中表征一定单词的含义)
我们必须先初始化一些这样的表示单词的稠密向量,然后通过学习的方式来更新向量的值(权重),然后得到我们最终想要的向量。
2.1中得到的每一个单词的one-hot编码,都需要映射到一个稠密的向量编码中。
这个映射过程,就被称作是嵌入(embedding),因为是单词的映射,所以被叫做词嵌入(word embedding)。
假设我们要把一个单词映射到一个300维(这个300维是经过大量的实验得出的,一般的映射范围是200-500维)的向量中,那么我们直观的做法就是:矩阵运算。
因为我们每个单词现在的情况是N维的一个向量(N是字典中单词的数量),如果映射到300维,需要的权重矩阵就是N ∗ 300,这样得到的矩阵就是一个1 ∗ 300的矩阵(向量)。
2.2.1 词嵌入举例
假设我们字典中有5个单词(即N=5),那么word embedding如下图所示: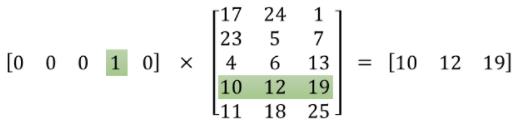
通过上图,我们可以发现一个规律:
计算出来的这个“稠密的”向量,和我们单词在one-hot编码表的位置是有关系的。
如果单词的one-hot编码中,第i维是1,那么生成的稠密词向量就是编码表的第i行。
所以我们word embedding生成稠密词向量的过程,就是一个查找编码表的过程。而这个编码表,我们可以想成是一个神经网络的隐藏层(这个隐藏层没有激活函数)。通过这个隐藏层,我们把one-hot编码映射到一个低维度的空间里面。
3 skip-gram 数学原理
在skip-gram中,每个词被表示成两个d维向量,用来计算条件概率。
假设这个词在词典中索引为i,当它为中心词时向量表示为 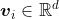 ,而为背景词时向量表示为
,而为背景词时向量表示为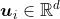 。
。
设中心词
在词典中索引为c,背景
在词典中索引为o,给定中心词生成一个背景词的条件概率可以通过对向量内积做softmax运算而得到:
可以想成是以c为中心词,o为背景词的概率权重;
分母相当于以c为中心词,生成其他各个词的概率权重。
所以二者一除就是给定中心词生成某一个背景词的条件概率
由上面那个式子,我们可以得到:每一个中心词,推断两边分别m个位置的背景词的概率:
其中,t表示窗口中心词的位置;m表示推断窗口的大小
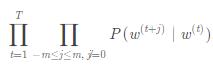
我们为了求出“最好”的word embedding,可以最大化上面那个概率。
基于此,我们可以使用最大似然估计的方法。
但是一个函数的最大值往往不容易计算,因此,我们可以通过对函数进行变换,从而改变函数的增减性,以便优化。
其中,我们把
带到上式中,可以得到

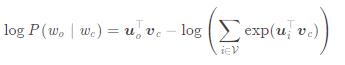
通过上面一段的操作,我们把一个求最大值的问题转换成了一个求最小值的问题。
求最小值,我们可以使用梯度下降法。
在优化之前,我们要搞清楚我们优化的目标是那个,哪些是参数。
我们要做一个假设,在对中心词权重更新时,背景词的权重是固定的,然后在以同样的方式来更新背景词的权重。
接下来我们求导计算梯度
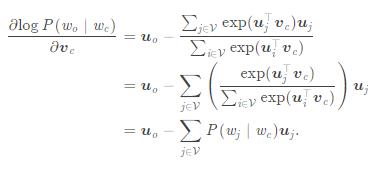
这里就计算出来了中心词的梯度,可以根据这个梯度进行迭代更新。
对于背景词的更新是同样的方法。(就是上式不是对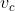 的偏导数,而是每个的偏导数了。
的偏导数,而是每个的偏导数了。
但是要注意背景词的个数不是唯一的,所以更新的时候要逐个更新。
训练结束后,对于词典中的任一索引为i ii的词,我们均得到该词作为中心词和背景词的两组词向量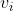 和
和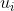
还有一个小问题要说明一下:
在词典中所有的词都有机会被当做是中心词和背景词。在更新的时候,都会被更新一遍,这种时候该怎么确定一个词的向量到底该怎么选择呢?
——在NLP应用中,一般使用中心词向量作为词的表征向量。
4 skip-gram流程总结
1)one-hot编码。
每个单词形成V∗1的向量;对于整个词汇表就是V∗V的矩阵。
2)word embedding 词嵌入。
根据索引映射,将每个单词映射到d维空间。
通过这样的方式就可以将所有的单词映射到矩阵W上(矩阵W的形状为V∗d),并且每个单词与矩阵中的某列一一对应。
3)skip-gram模型训练。初始化一个d维空间的矩阵作为权重矩阵W ′ ,该矩阵的形状为V ∗ d 。
值得注意的是,目前我们已经有了两个d维空间的矩阵,要清楚这两个矩阵都是干什么的。
矩阵W的每一行对应的是单词作为中心词时的向量
这里初始化的矩阵W'的每一列则对应的是单词作为背景词时的向量
每个词都有机会成为中心词,同时也会成为其他中心词的背景词,因为窗口一直再变动。
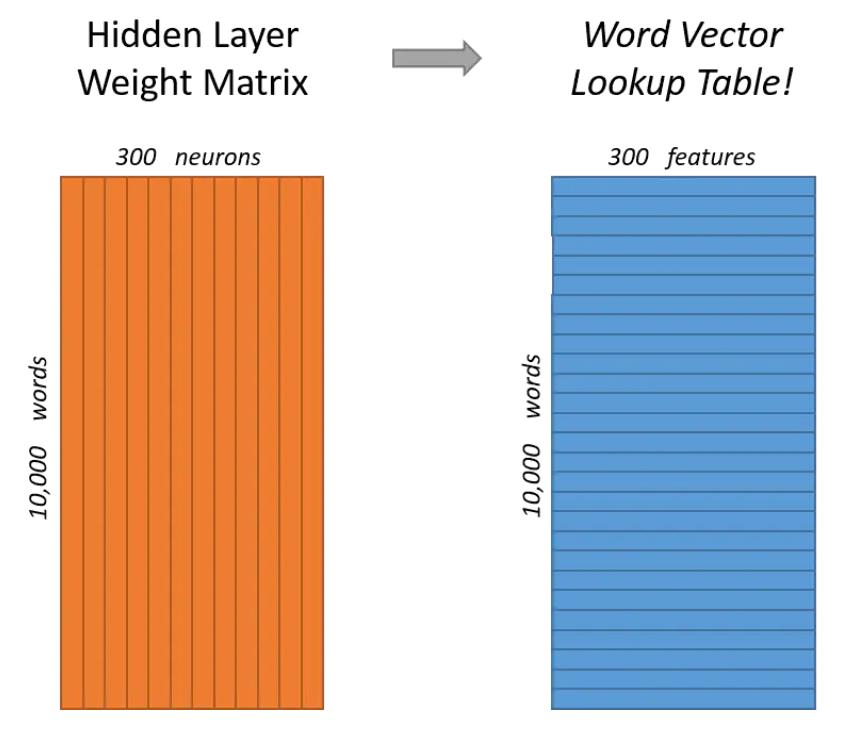
4)取出一个词作为中心词。该词的词向量
此时会得到一个背景词的计算结果,即:
(假设背景词的索引为o)。
重复计算,我们可以得到
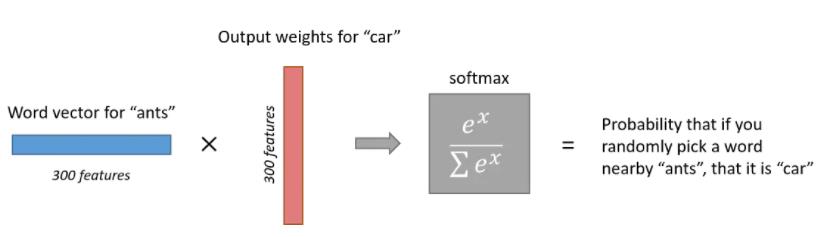
5)softmax层的映射。
在上一步中得到了V个背景词的概率权重,那么此时我们需要做的就是计算某一个词作为背景词的条件概率,即
6)概率最大化。
skip-gram的学习相当于监督学习,我们是有明确的背景词输入的。(就是知道这个地方的背景词应该是哪个)
我们期望窗口内的词的输出概率最大。因此我们的目标变为极大化概率
。
在不影响函数单调性的前提下我们变为极大化函数:
l(对数似然)。
但是,计算一个函数的最大值不如计算一个函数的最小值来的方便,因此这里给这个函数进行单调性变换:
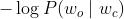
7)极小化目标函数。
通过上面的变换,此时已经变为一个数学优化问题,梯度下降法更新参数。
8)更新中心词的向量
后面减去的即为梯度:

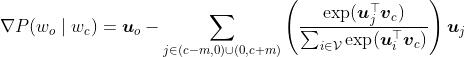
9) 8对应的梯度里面,相比于5,又多了一层对于j的求和,这个下标代表的背景词,m是窗口的大小。这么做才能与我们最初的设定相对应:一个中心词,推断多个背景词。
10).根据同样的原理,在窗口进行移动了之后,可以进行同样的更新。
11.在词汇表中所有的词都被训练之后。我们得到了每个词的两个词向量分别为
。
 5 skip-gram 优化
5 skip-gram 优化
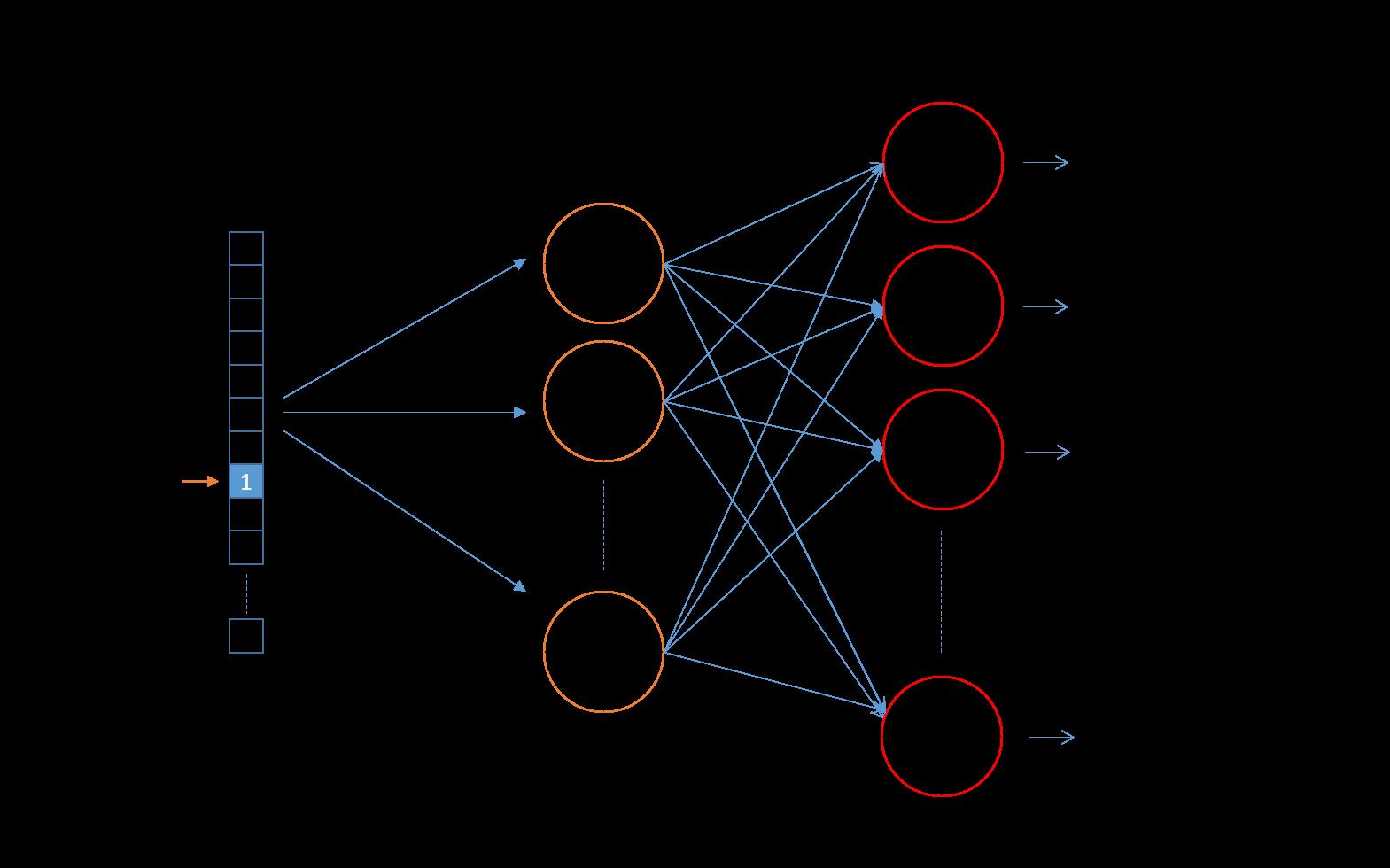
我们现在有一个包含10000个单词的词汇表,向量特征为300维。
那么对于这个词汇量的skip-gram,将会有两个weights矩阵----一个隐藏层和一个输出层。
这两层都会有一个300x10000=3000000的权重矩阵。
在如此大的神经网络上进行梯度下降是非常慢的,更加严重的是,我们需要大量训练数据去调整权重,以及避免过拟合。
在论文“Distributed Representations of Words and Phrases and their Compositionality”中,主要有三种方式来优化skip-gram:
5.1 在模型中将共同出现的单词对或者短语当做单个“词”
比如像“Boston Globe”(“波士顿环球报”,一种报纸)这样的单词对,在作为单独的“Boston”和“Globe”来进行看待的时候有着非常不同的含义。
所以在将它作为一整个“Boston Globe”来说是非常有意义的,不论它出现在文中哪里,都将一整个当成一个单词来看待,并且有它自己的词向量。
论文中使用了1千亿个来自谷歌新闻数据集的单词来进行训练。额外增加的短语使得这个模型的单词尺寸缩减到了3百万个单词!
5.2 二次采样
在一个很大的语料库中,有一些很高频率的一些词(比如冠词 a,the ;介词 in,on等)。
这些词相比于一些出现的次数较少的词,提供的信息不多。同时这些词会导致我们很多的训练是没有什么作用的。
为了缓解这个问题,论文中提出了二次采样的思路:每一个单词都有一定概率被丢弃。这个概率为:

f(wi)是单词出现的次数与总单词个数的比值。(例如“peanut”在1 billion 单词语料中出现了1000次,那么z('peanut')=1E-6)
t是一个选定的阈值,一般在1E-5左右。
5.3 负采样
在训练skip-gram时,每接受一个训练样本,就需要调整所有神经单元权重参数,来使神经网络预测更加准确。
换句话说,每个训练样本都将会调整所有神经网络中的参数。
词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。
负采样的思路是:每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
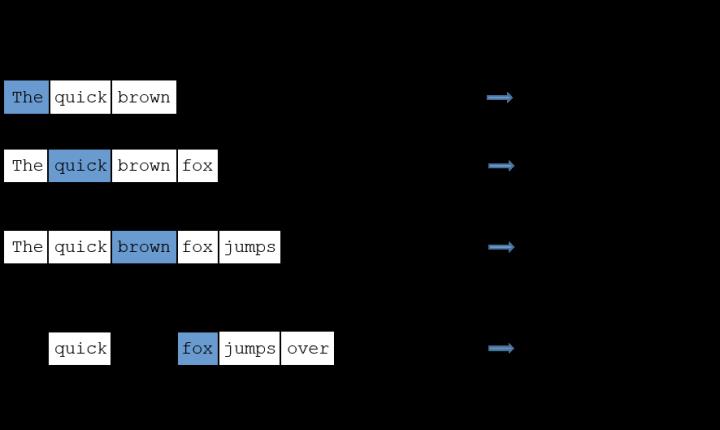
如果词汇表的大小为1万, 当输入样本 ( "fox", "quick") 到神经网络时,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称之为 negative word。
负采样的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
在论文中作者指出指出对于小规模数据集,建议选择 5-20 个 negative words,对于大规模数据集选择 2-5个 negative words.
如果使用了负采样,那么 仅仅需要去更新positive word- “quick” 和选择的其他 10 个negative words 的结点对应的权重,共计 11 个输出神经元,相当于每次只更新 300 x 11 = 3300 个权重参数。对于 3百万 的权重来说,相当于只计算了千分之一的权重,这样计算效率就大幅度提高。
这里指的权重是前面说的W'的权重,也就是背景词矩阵的权重
5.3.1 负样本(negative words)的选择
论文中使用 一元模型分布 (unigram distribution) 来选择 negative words。
一个单词被选作 负样本 的概率跟它出现的频次有关,出现频次越高的单词越容易被选作负样本,经验公式为:

其中:
f(w) 代表 每个单词被赋予的一个权重,即 它单词出现的词频。
分母 代表所有单词的权重和。
公式中指数3/4完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。
参考文献
NLP之---word2vec算法skip-gram原理详解_Ricky-CSDN博客_skipgram
Word2Vec教程-Skip-Gram模型 - 简书 (jianshu.com)
Word2Vec教程-Negative Sampling 负采样 - 简书 (jianshu.com)
以上是关于NLP 笔记:Skip-gram的主要内容,如果未能解决你的问题,请参考以下文章