日志VS网络数据,谁能做好全链路监控?
Posted 鲜枣课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日志VS网络数据,谁能做好全链路监控?相关的知识,希望对你有一定的参考价值。
对系统的运行状态进行监控,是IT工程师的一项重要工作。
如果不能确保整个系统及其链路处于稳定运行的状态,那么,企业的业务稳定发展就无从谈起。
21世纪以来,随着云计算的兴起,系统架构发生了显著的变化。分布式崛起,开始取代单体式,成为行业的主流选择。微服务概念的提出,容器等云原生技术的发展,加剧了这一变化。
系统架构变化之后,对系统进行监控的需求也随之变化,监控难度大幅增加。
目前,对系统进行全链路监控,根据数据源、监控路径、落地方式等不同,存在多种监控方式。市场上最主流的监控派别,是日志类和网络数据类。
接下来,我们通过对比的方式,看看这两种技术派别的主要差异。
▉ 数据源对比
采样数据 VS 全量数据
日志类的数据来源有两类:
一种是传统物理设备上的日志文件,这种日志文件能够提供的数据格式、数据精细度、数据内容,都是各个设备厂商预先设定的。
另外一种,是程序开发过程中或开发完成后,为捕获程序或者系统本身的运行信息,开发出来的日志系统。
日志系统本身不对应用程序发起主动式访问,只是伴随着程序的运行,将相关的运行数据(机器本身或者程序运行的状态信息)输送出来。
此外,日志属于采样数据,信息级别与功能均由人工定义,在存储以及分析的过程中,时常因前端需求而更改,按照人为需求进行目标输出,因此边界十分明显。
再来看看网络数据。
网络数据是应用程序之间通过网络进行传输的独特过程数据。它能够提供业务活动、应用性能、安全性与IT基础架构等方面的信息。
获取网络数据的方式比较简单,通过交换机镜像的方式,就可以将网络数据复制出来。
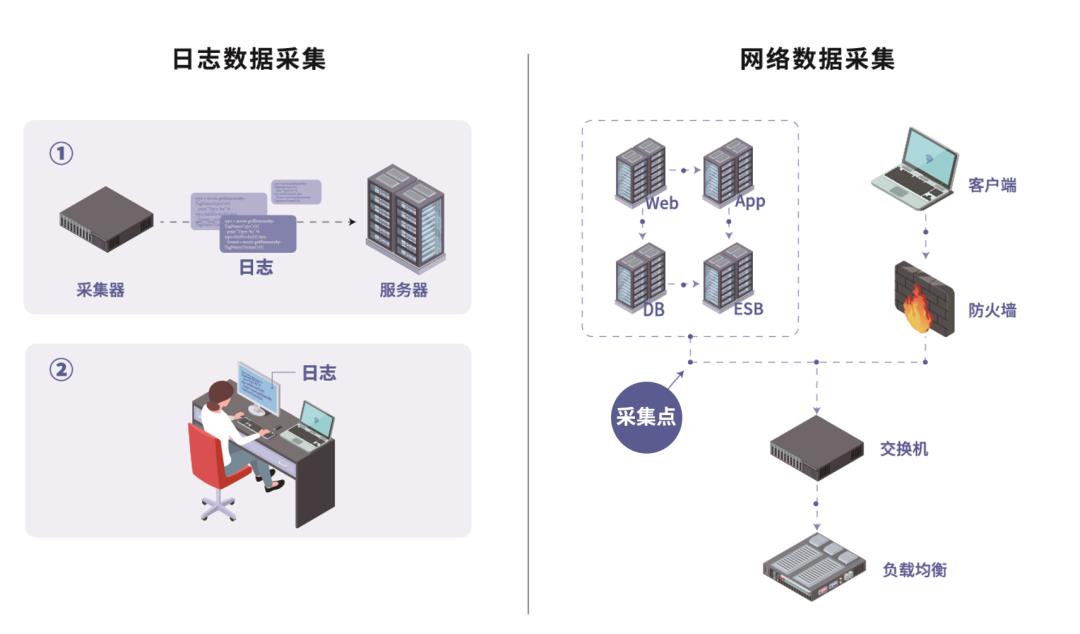
网络数据获取之后,送至分析服务器,即可实现性能监控。
网络数据是一种全量数据,通过旁路捕获数据包,不消耗任何系统资源,可以实时反映设备、服务器、系统等运行的状态。
时间精度和实时性
日志时间由系统程序自动打印,一般精确到毫秒。
网络数据的时间戳,由捕获服务器的高性能网卡抓包时进行标记,最快可以实现纳秒级。
尽管两者同样采用ntp时间同步,但两者之间的时间准确程度也会因网络传输等因素产生毫秒级以上的差距。
在网络传输过程中,由于Delayed ACK与Nagle算法的相互作用,会导致最大500毫秒的延迟。日志往往无法排查此类问题,而通过网络数据可以进行数据包回溯分析。因此,网络数据比日志具备更高的实时性。
▉ 监控路径对比
作为两种数据源,日志与网络数据所监控的定义与范围有着天然的差别。
分布式追踪领域有三个重要的概念:Metrics、Trace、Log:
Metrics即指标,反映组件实时状况与健康度;
Trace即链路,反映在单次请求的范围内如何处理信息;
Log即日志,反映离散的事件或过程;

(Metrics、Tracing、Logging三者间的关系示意图)
全链路监控,就是利用上述三者之间的关系,分步骤实现的。
一般来说,进行全链路监控有两种做法:
第一种做法:首先通过指标(Metrics),查看组件的健康程度、受影响的交易类型;再通过指标关联,查看整个交易路径的健康度(Trace);最后,定位具体的问题节点(Log),找出根因。
第二种做法:当交易出现问题,首先查看出错的具体路径(Trace),再查看相对应的指标(Metrics),如服务器或应用性能指标等,最后查看详细日志数据(Log)。
网络数据,通常反映的是指标。然而,无论是指标还是日志,都必须经过数据加工处理,才能进入全链路追踪体系。
Metrics辅助于应用监控,倾向于节省资源,会对数据进行天然的“压缩”。而Log倾向于无限增加,会频繁地超出预期容量。
无论是日志类还是网络数据类监控,都可以采用以上两种做法。只不过介于数据源的因素,网络数据类监控具有天然可操作性,而日志类监控却经过了一个漫长的发展期,并衍生出许多新的问题。
▉ 落地方式对比
全链路监控的需求,并不是一开始就有的。受制于网络技术与业务发展等诸多因素,不同阶段对全链路监控的标准和需求也有着明显的差异。
网络发展初期,业务规模小,企业通常采用标准作业程序(SOP)。
此时,由于系统多为单体架构,操作简单、易部署,为节省资源、缩短时间成本,除核心系统外,没有监控其它系统的需求。因此,系统版本迭代较慢,不易扩展,全链路监控也就无从谈起。
到了2010年左右,互联网发展进入飞跃期。随着业务量逐渐增多,业务分支越来越细,垂直架构逐渐兴起。
然而,这一时期,系统与系统之间存在数据冗余,且同一个子系统中的业务无法实现关联。尽管全链路监控的需求与日俱增,如何实现却成为一道现实难题。
在追求全链路监控的过程中,由于缺乏统一的标准,对现有系统进行改造成为当时较为普遍的解决方案。
然而,改造系统同样面临两个严峻问题:
第一大问题:改造周期过长。
即便如BMC对系统实施改造,在半年内也仅能完成两套系统的改造工作。如果用户规模持续增多、业务量持续走高,耗时将会更久。而通过网络数据对系统进行改造,可以实现3个月内10套系统的改造升级工作。
第二大问题:成本过高。
日志改造需要网络部门与开发部门协同合作。我们都知道,在企业内部,开发部门属于增效部门,运维部门属于降本部门,二者之间有天然的隔阂。
改造日志,势必会增加开发成本、增加人天数。而利用网络数据进行改造,将90%的工作在运维部门内部完成,极大地降低开发成本,提高运维效率。
2014年,ThoughtWorks首席科学家Martin Fowler与James Lewis给出了微服务的完整定义:
每个服务运行在自己的进程中;
微服务之间采用轻量级通信;
微服务应基于业务能力进行构建;
采用自动化部署机制实现微服务的独立部署;
服务的管理应采用最小的中心化管理。
随着分布式链路架构的日益成熟,云环境与微服务的天然契合性,为日志全链路监控标准的产生奠定了一定基础。
微服务即服务按照不同维度拆分,一次请求往往涉及多个服务,这些应用服务由不同的团队开发、使用不同的编程语言,横跨多个数据中心。因此,全链路监控势在必行,进一步刺激了基于日志的全链路监控标准与工具的产生。
微服务架构中,业务链路极其复杂。如何快速发现问题、判断故障节点、梳理服务链路、分析链路性能,是影响全链路监控的主要问题。
而基于日志的全链路监控,就主要围绕这些问题,通过埋点与生成日志、收集与存储日志、分析和统计调用链路数据来一一实现。
日志通常利用Trace ID、Parent ID等信息,对调用链路进行查询与问题定位。但是在调用的过程中,如果调用失败,会直接中断主流程,而调用过程又具有高依赖与频繁依赖的特性,因此提升性能、增强稳定性是解决日志全链路监控的关键。
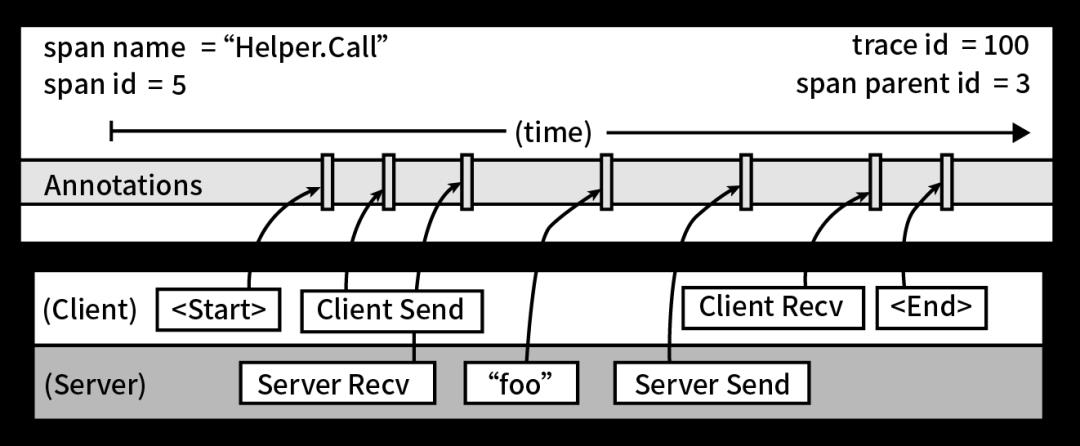
(span细节图)
为了解决性能问题,众多大厂纷纷入局,研发了许多开源的日志类监控工具,如谷歌的Dapper、Zipkin、Sky Walking 、Pinpoint等。
但是这些开源监控产品,通常通过代码埋点进行部署,传递的是底层数据,和业务的相关性较低。
除此以外,探针的性能、Collector的扩展性、时间人工成本等因素,也影响着全链路监控的应用。
比如,在某大型股份制银行长达两年的云上分布式链路追踪来看,其人工成本增加近150%,这对于某些中小型企业是难以承受的压力。
而通过网络数据,无需对系统进行改造,仅需对数据进行解码,梳理各个节点的访问关系,刻画业务的调用路径,相比日志更易落地。
▉ 结语
未来,随着技术的发展,日志类全链路监控的落地难题也许会被攻克。但就目前而言,无论是数据源、监控路径,亦或落地方式,基于网络数据的全链路监控明显优于日志。
需求决定市场,选择网络数据作为监控数据源,完全可以从源头解决全链路监控的一系列难题,从而维护网络稳定,发挥系统性能,推动企业业务的快速发展。
扫描下方二维码,学习更多运维技术知识

以上是关于日志VS网络数据,谁能做好全链路监控?的主要内容,如果未能解决你的问题,请参考以下文章