分布式存储趟过的那些坑 Posted 2021-04-02 中兴数据智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式存储趟过的那些坑相关的知识,希望对你有一定的参考价值。
大数据 / 人工智能 / 区块链 / 数据库 / 分布式存储
分布式存储,简而言之就是将数据分散存储在多个独立的节点上。由于其具备高可扩展性、高可靠性、高安全性等特点,在大规模数据应用场景下有着广泛的应用。但是,由于相对传统的集中式存储,分布式存储的系统架构更加复杂,因此在实际应用中也容易遭遇更多的“坑”。本系列将根据中兴通讯分布式存储系统的具体实践,为您逐一解析并趟平分布式存储的各种或浅或深的“坑”。
许军宁 | 文 © 中兴数据智能(ZTE-DI)出品
引子 “ 小Q: 分布式存储好像很厉害的样子,刚连上系统,我的空间一下子就变大啦,比这台主机容量多好几倍哦。
小A: 分布式存储的目的就是将多台设备的存储空间联合起来,构成一个大的池子,存储容量看起来自然就多喽。
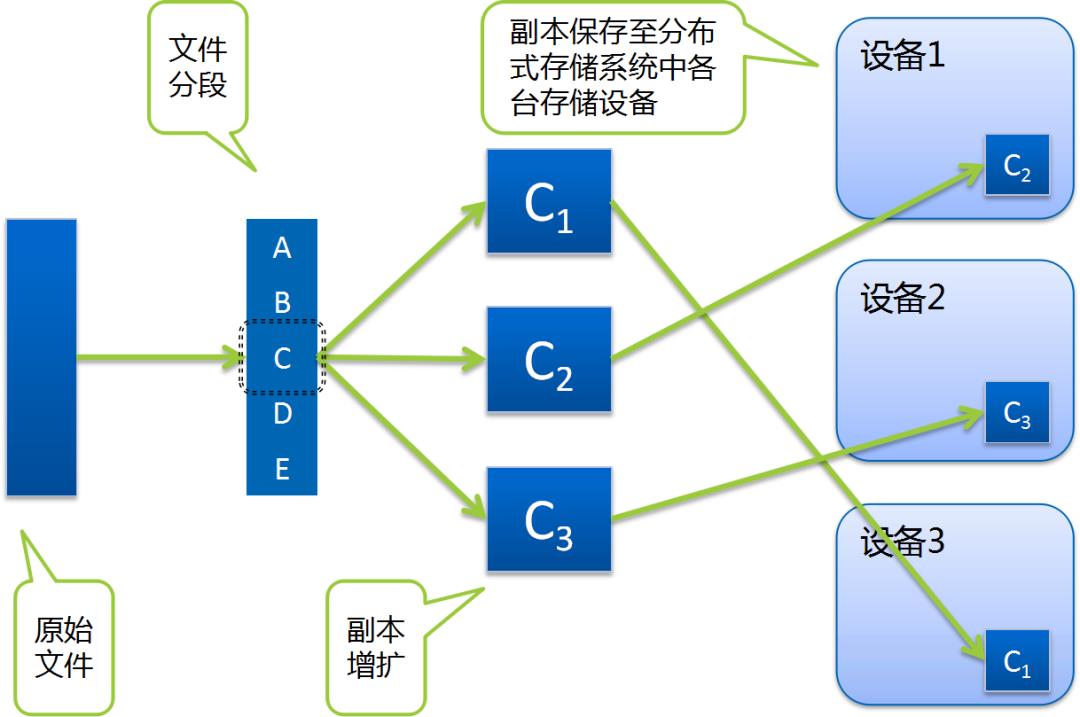
小A: 这可不好说了,通常一个文件会被拆分,其中每个分段再通过冗余技术,以多个相同副本或多个纠删码分片的形式散布到系统中的各台设备上。
小Q: 分的这么散啊,读一个文件时岂不是要到处找内容,如果有一台机器坏了,文件不就不完整了么?
小A: 这可不必担心,分布式存储软件做的就是分布式存储调度、管理、整合的工作。文件读写与单机操作,在使用体验上没有区别。即便是有硬盘或者机器损坏,只要在冗余设计限度内,都可以保证内容能够完整、正常的访问。
” 分布式存储以软件方式将多台设备的存储空间打通,形成统一的存储资源池。其大容量、高吞吐、规模灵活的特点显著优于传统的单机存储/集群存储方案。在云化演进中,其地位日趋重要,已成为云基础设施中的关键组件。
随着规模的扩大,设备的增多,既往单机设备上很多异常问题和现象,在分布式存储系统中已经变得不再罕见,简单的异常处理方式也已不能满足大型系统的运用需要。在架构方面,分布式存储对大量复杂的情况作了识别和处理预案,努力保证数据存储可靠性和存储服务可用性。
为提升数据存储可靠性和存储服务可用性,大型分布式存储系统在方案框架上采用的典型手段包括:
1、数据存储冗余:
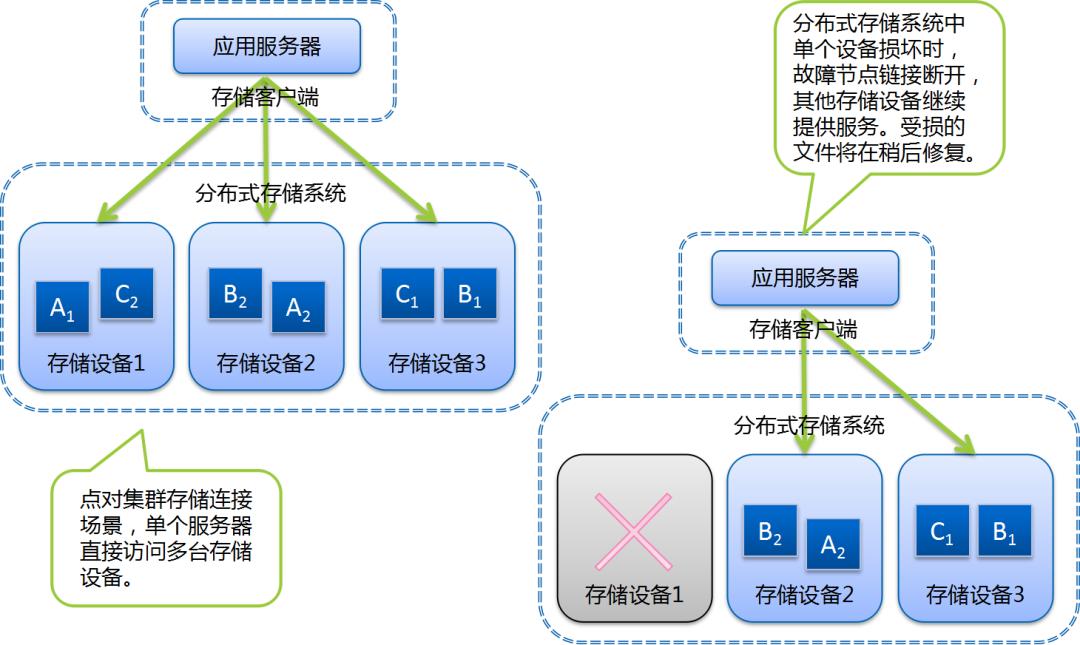
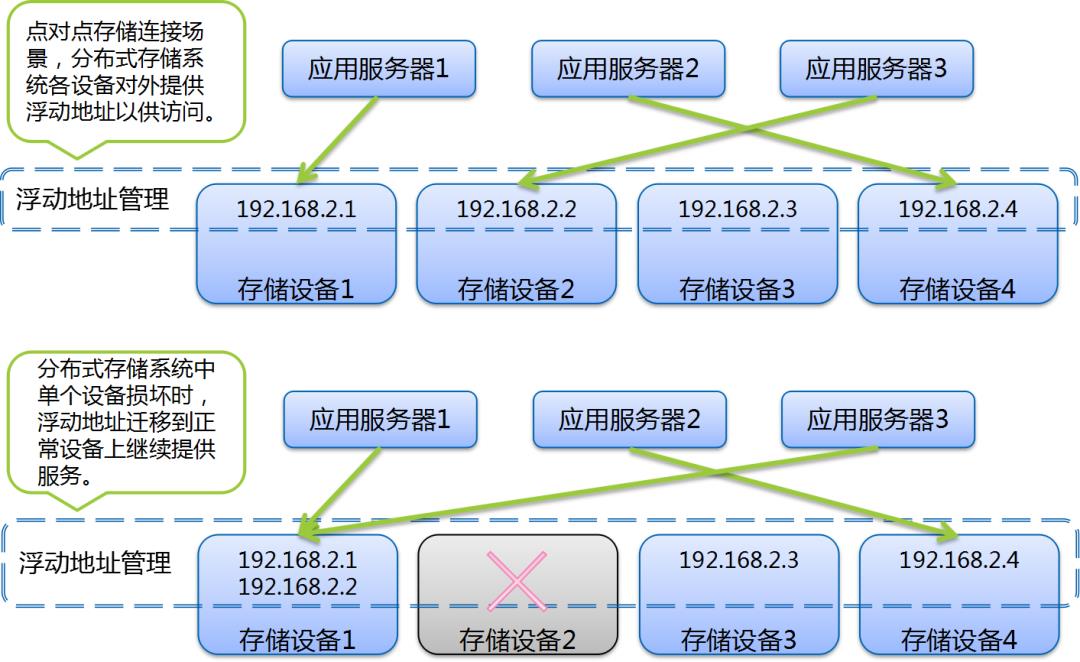
主要技术方案包括多路径读写和服务地址自适应浮动。前者多见于专用客户端或较新的存储协议中;后者在传统固定服务地址挂接方案中更为常见。
现代主流商用或开源分布式存储/云存储方案中均采用该基本框架;在实践层面,该基本框架已经可以较好的应对典型的风险场景。
连续坏盘该咋办 “ 小Q: 分布式存储系统的硬盘总数比普通的单机存储要多很多,这样硬盘损坏的概率不是也要大很多么,数据是不是更容易损坏?
小A: 分布式存储有冗余机制,可以通过副本或其他的机制保证单块硬盘损坏不会丢失数据。
小Q: 那么,如果坏了一块硬盘之后又有硬盘损坏呢,有一块硬盘坏就有可能再有一块硬盘坏啊。
小A: 一块硬盘损坏之后,会有自动修复机制,受损硬盘上的数据会根据规则在其他正常硬盘上重建,这样系统就会恢复原有的副本数量/冗余级别。再有硬盘损坏时,重复以上过程就可以了,不用担心的。
小Q: 可是如果接连出现两块硬盘损坏呢,就是第一块硬盘损坏后,数据还没有重建好,就又坏了一块硬盘,真的不会丢数据么?
小A: 这个情况就复杂一些啦,如果最初的冗余度只有2,例如配置为双副本,那么当两个副本正好都在损坏的硬盘上时,设备破损的情况就超过了冗余能力,这时数据损失是不可避免的。当然,如果我们最初配置的是三副本,这个时候应该还有一个可用的副本,在安全级别允许的条件下,仍然可以对其进行复制,恢复成三副本。
小Q: 嗯,明白了。如果真的出现两块硬盘接连损坏,那么丢失两个副本的比只丢失一个副本的风险更大一些,我们是不是应该优先去修复丢失两个副本的文件?
小A: 是的,这是基于风险的差异化数据修复方案,更容易丢失的数据优先进行恢复。
” 随着设备数量的增加和相对廉价设备的使用,存储数据异常、单个存储器件乃至单个存储节点的失效已经不再是罕见情况,数据修复能力已成为分布式存储系统的标准功能。
常见的数据修复技术的关注重点集中在高效率的方案方法方面,高速高效的数据修复方案固然可以提升系统的可靠性,但另一方面,数据修复是以消耗与正常业务处理共享的系统资源为代价的。不限制数据修复处理的资源占用,往往会影响到正常的存储业务处理;设定特定的处理速度,又不能充分发挥系统的恢复能力,加大数据丢失风险。上述问题在低负荷系统中表现尚不明显;但在资源使用较为充分的重载系统中,已经成为影响存储服务质量和数据保存可靠性的重要风险点。在整体高负载或者限制修复速度的情况下,采用同一修复策略,也会导致冗余度较低,甚至已无存储冗余的数据不能得到更快的修复,面临冗余设计击穿风险。
针对上述问题,一种更加有针对性策略的分布式存储系统数据修复方法被引入,其要点包括:
按照冗余程度差异确定数据安全风险,优先修复安全风险更高的数据。
在更复杂的一些场景下,例如,大型分布式存储系统,往往同时存在多种冗余度数据,针对不同的逻辑单元有着不同的服务质量(Quality of Service,QoS),针对不同的用户有着差异化的服务等级协议(Service Level Agreement,SLA)要求。
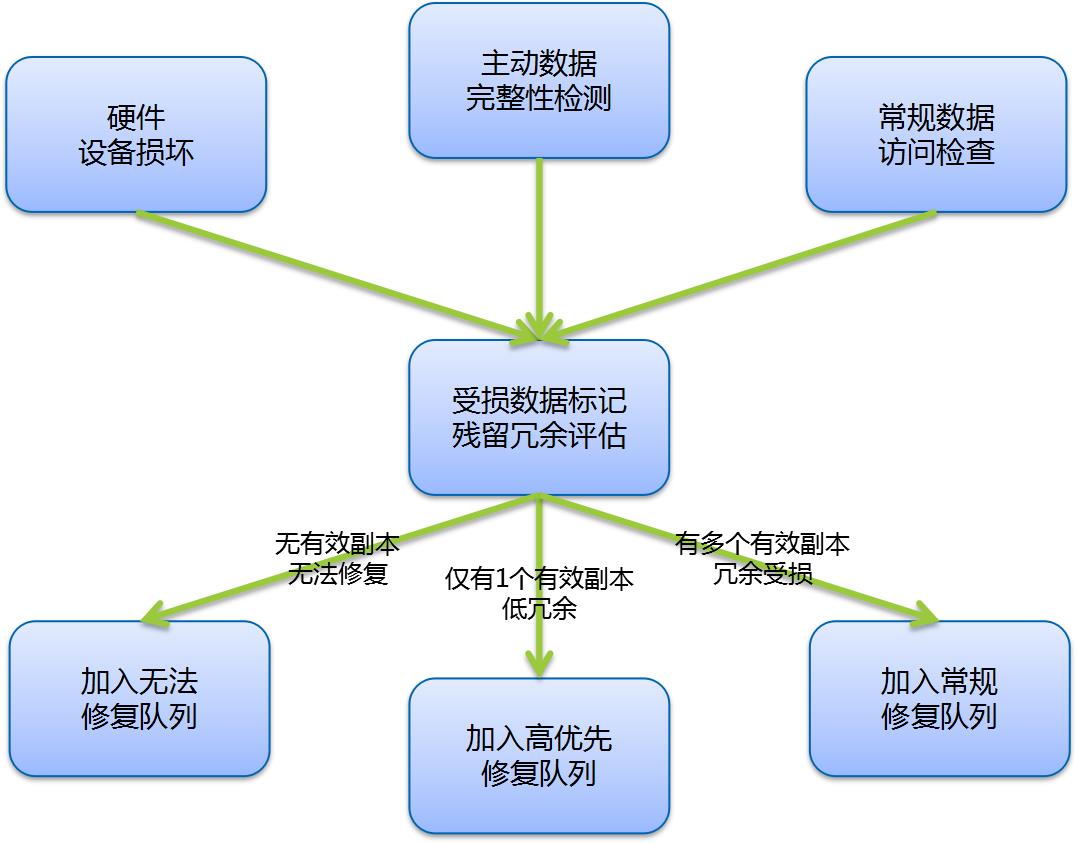
需要考虑多影响要素综合评估受损数据的丢失风险,要点包括:
在受损数据发现与识别后,针对受损数据进行分析,进行影响要素参数提取。
例如,检查受损数据对应的元数据信息,确定原始冗余度;
检查受损数据其他副本/分片状态,确定残留冗余度;
根据数据所处单元,提取相应的服务质量要求指标;
根据数据所属用户,提取服务等级协议要求参数;
存储系统的整体服务质量参数等。
上述参数提取完成后,根据评估规则进行数据丢失风险计算。
最后,根据风险评估结果确定相应的数据修复优先级。
* 本文为中兴数据智能原创文章,转载请留言或评论获取授权。
以上是关于分布式存储趟过的那些坑的主要内容,如果未能解决你的问题,请参考以下文章
运维告诉你分布式存储的那些“坑”
细说分布式Redis架构设计和踩过的那些坑
Fine原创JMeter分布式测试中踩过的那些坑
关于在使用scrapy-redis分布式踩过的那些坑:
[转] 那些在使用webpack时踩过的坑
1年时间业务量疯长40倍,谈人人车的平台架构演进之路
 分布式存储,简而言之就是将数据分散存储在多个独立的节点上。由于其具备高可扩展性、高可靠性、高安全性等特点,在大规模数据应用场景下有着广泛的应用。但是,由于相对传统的集中式存储,分布式存储的系统架构更加复杂,因此在实际应用中也容易遭遇更多的“坑”。本系列将根据中兴通讯分布式存储系统的具体实践,为您逐一解析并趟平分布式存储的各种或浅或深的“坑”。
分布式存储,简而言之就是将数据分散存储在多个独立的节点上。由于其具备高可扩展性、高可靠性、高安全性等特点,在大规模数据应用场景下有着广泛的应用。但是,由于相对传统的集中式存储,分布式存储的系统架构更加复杂,因此在实际应用中也容易遭遇更多的“坑”。本系列将根据中兴通讯分布式存储系统的具体实践,为您逐一解析并趟平分布式存储的各种或浅或深的“坑”。