第五周.02.标签传播与社群检测
Posted oldmao_2001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第五周.02.标签传播与社群检测相关的知识,希望对你有一定的参考价值。
本文内容整理自深度之眼《GNN核心能力培养计划》
公式输入请参考: 在线Latex公式
标签传播
Learning from Labeled and Unlabeled Data with Label Propagation
一篇比较老的文章,因此一些写法和现在的套路对不上。另外整体比较短。
摘要
本文用未标记的数据来辅助标签数据来进行分类任务。
We investigate the use of unlabeled data to help labeled data in classification.
本文提出一种迭代的方法:标签传播,该方法将标签在数据集中密集区域内进行传播。这里的密集区域是用未标记数据来判定的,简单来说就是不看标签,直接看数据之间的图结构信息。
We propose a simple iterative algorithm, label propagation, to propagate labels through the dataset along high density areas defined by unlabeled data.
本文对提出的算法及相关算法进行了分析。
We analyze the algorithm, show its solution, and its connection to several other algorithms.
本文提出了如何使用最小生成树来学习模型参数,如何进行特征选取等,实验结果非常好。
We also show how to learn parameters by minimum spanning tree heuristic and entropy minimization, and the algorithm’s ability to perform feature selection. Experiment results
are promising.
Introduction不看,直接从第二节开始看。
2.1 Problem setup
标签数据表示为:
(
x
1
,
y
1
)
⋯
(
x
l
,
y
l
)
(x_1,y_1)\\cdots(x_l,y_l)
(x1,y1)⋯(xl,yl)
标签类别表示为:
Y
L
=
{
y
1
⋯
y
l
}
∈
{
1
⋯
C
}
Y_L=\\{y_1\\cdots y_l\\}\\in\\{1\\cdots C\\}
YL={y1⋯yl}∈{1⋯C}
C
C
C是类别数量且为已知,所有的类别均已出现在标签数据中,不会有新的类别出现
未标注数据表示为:
(
x
l
+
1
,
y
l
+
1
)
⋯
(
x
l
+
u
,
y
l
+
u
)
(x_{l+1},y_{l+1})\\cdots(x_{l+u},y_{l+u})
(xl+1,yl+1)⋯(xl+u,yl+u)
可以看到未标注数据的个数要远远大于标签数据:
l
<
<
u
l<<u
l<<u
标签数据和未标注数据集合
X
X
X的维度是
D
D
D:
X
=
{
x
1
⋯
x
l
+
u
}
∈
R
D
X=\\{x_1\\cdots x_{l+u}\\}\\in R^D
X={x1⋯xl+u}∈RD
任务是用标签数据和未标注数据集合
X
X
X和标签
Y
L
Y_L
YL来预测未标记数据的标签
Y
U
Y_U
YU。
模型思想和GCN一样,相邻节点会有相似的表征或标签。
Intuitively, we want data points that are close to have similar labels.
但是这里的数据没有图的结构,也不存在相邻节点,因此第一步就是做一个全连接的图,涵盖所有节点,并用节点之间的欧氏距离
d
i
j
d_{ij}
dij来表示节点的边,同时距离越小,两个节点之间的权重
w
i
j
w_{ij}
wij越大(
σ
\\sigma
σ是超参数):
w
i
j
=
exp
(
−
d
i
j
2
σ
2
)
w_{ij}=\\exp\\left(-\\cfrac{d^2_{ij}}{\\sigma^2}\\right)
wij=exp(−σ2dij2)
然后给所有点加上soft labels,就是每个节点上有
C
C
C个标签的概率分布(概率和为1),这里对应可以看成是GCN里面的每个节点的初始化embedding;然后让每个节点的soft labels通过边来进行传播,当边的权重
w
i
j
w_{ij}
wij越大,那么标签传播越容易,这里对应可以看成是GCN里面的卷积操作。
这里给出标签从点
i
i
i传播到
j
j
j的转移概率可以算出来,然后把所有节点都算出来就变成了一个概率转移矩阵:
T
i
j
=
P
(
j
→
i
)
=
w
i
j
∑
k
=
1
l
+
u
w
k
j
T_{ij}=P(j\\rightarrow i)=\\cfrac{w_{ij}}{\\sum_{k=1}^{l+u}w_{kj}}
Tij=P(j→i)=∑k=1l+uwkjwij
矩阵大小为:
(
l
+
u
)
×
(
l
+
u
)
(l+u)\\times (l+u)
(l+u)×(l+u),分母带邻接矩阵中的行求和,也就是邻居节点求和,相当于归一化操作。
文章还定义了一个
(
l
+
u
)
×
C
(l+u)\\times C
(l+u)×C的标签矩阵
Y
Y
Y。
2.2 The algorithm
The label propagation algorithm is as follows:
- All nodes propagate labels for one step: Y ← T Y Y \\leftarrow TY Y←TY
- Row-normalize Y Y Y to maintain the class probability interpretation.
- Clamp the labeled data. Repeat from step 2 until
Y
Y
Y converges.
在第二步里面得到第一步标签传播的结果后会去比对前 l l l个有标签的结果,会将前 l l l个重置为ground truth。
第三步里面提到,防止标签数据的fade away,这里会固定有标签数据节点的分布(这里其实是相对于独热编码,如有是三分类,数据节点属于第二类,那么就表示为[0,1,0])
Step 3 is critical: Instead of letting the labeled data points ‘fade away’, we clamp their class
distributions to Y i c = δ ( y i , c ) Y_{ic}=\\delta(y_i,c) Yic=δ(yi,c)
下面对算法的收敛性进行了数学上的证明,大概思路是将转移矩阵分块(亦可以参考GGNN论文思路),然后得到 Y U Y_U YU的推导公式,然后证明经过若干次迭代后,其极限是收敛的。
社群检测
这个其实也是标签传播的派系,相同标签可以看做同一个社群,只不过在其基础上进行了改进。
Near linear time algorithm to detect community structures in large-scale networks
摘要
开门见山提出社群检测任务的重要性和应用。
Community detection and analysis is an important methodology for understanding the organization of various real-world networks and has applications in problems as diverse as consensus formation in social communities or the identification of functional modules in biochemical networks.
给出当前研究的不足:computationally expensive。
Currently used algorithms that identify the community structures in large-scale real-world networks require a priori information such as the number and sizes of communities or are computationally expensive.
本文提出的方法是?
In this paper we investigate a simple label propagation algorithm that uses the network structure alone as its guide and requires neither optimization of a predefined objective function nor prior information about the communities.
算法的原理是?
In our algorithm every node is initialized with a unique label and at every step each node adopts the label that most of its neighbors currently have. In this iterative process densely connected groups of nodes form a consensus on a unique label to form communities.
得到的结果是?
We validate the algorithm by applying it to networks whose community structures are known. We also demonstrate that the algorithm takes an almost linear time and hence it is computationally less
expensive than what was possible so far.
COMMUNITY DETECTION USING LABEL PROPAGATION
关于基础的设定就不写了,和上面一样的,这里不同的是提出了两种更新,一种是同步更新,就是上面的那种更新方式,t时刻的节点信息是由t-1时刻的邻居信息汇聚而来。但是这种更新方式对于bi-partite和star类型(star类型是bi-partite的特例)的图会有震荡的现象,具体看原文图三:
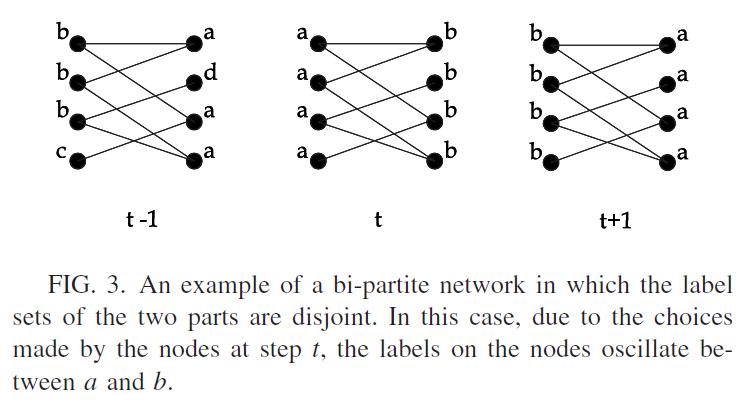
可以从图中可以看到t和t+1时刻的图就开始发生震荡了,因为左右两边的节点都是同时更新的,所以会发生互换标签的结果。
因此这里采用异步更新的方式,将迭代过程更新后的标签结果及时作为下一个节点计算的参照。
以上是关于第五周.02.标签传播与社群检测的主要内容,如果未能解决你的问题,请参考以下文章